私は、AIが生成した文章をより自然で本物らしく聞こえるようにする、高度なAIヒューマナイザー・ツールを作りましたが、実際のユーザーから率直なフィードバックを得るのに苦労しています。現実の利用環境でどのように機能しているかを知りたいです。実際に人間らしく聞こえるのか、コンテンツ制作やSEOにおいて信頼して使えるのか、どこで破綻したり明らかにAIが書いたように感じられるのかを知りたいです。問題点を修正し、品質を向上させ、ブロガーやマーケター、そして人間らしいAIコンテンツを求める一般ユーザーにとって安全かつ信頼できるツールにするために、具体的で実用的なフィードバックが必要です。
Clever AI Humanizer:実際に使ってみた体験レビュー(証拠付き)
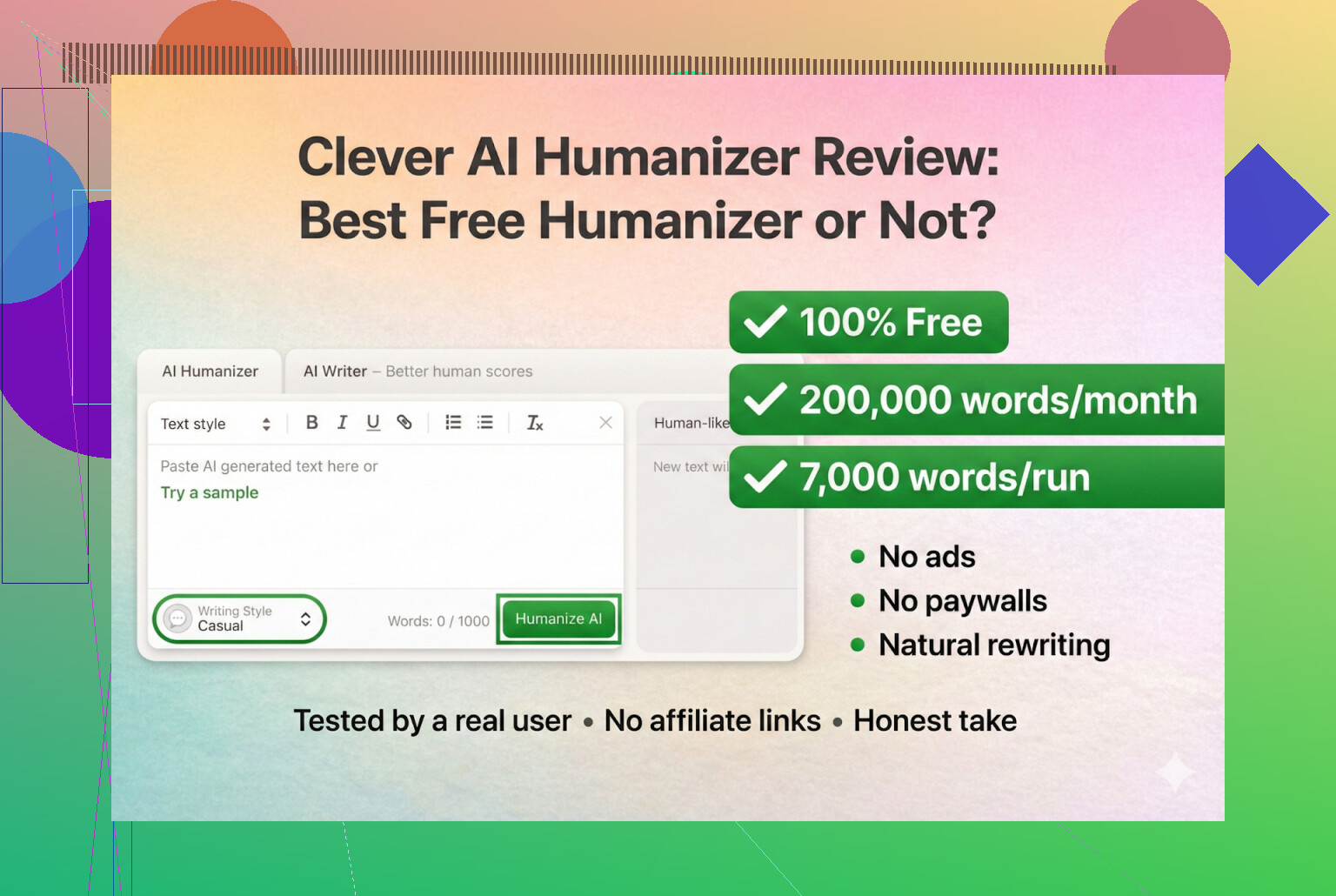
最近いろいろな「AI人間化ツール」を試しています。というのも、DiscordやRedditで「今まだ使えるのはどれ?」という話題を何度も見かけたからです。多くのツールが、いつの間にか動かなくなったり、突然有料SaaSになったり、静かに質が落ちていたりします。
そこで今回は、「完全無料・ログイン不要・クレカ不要」のツールから検証を始めることにしました。最初の候補は Clever AI Humanizer です。
ツールはこちら:
Clever AI Humanizer — 最高の100%無料ヒューマナイザー
見る限り、これが本物の公式サイトで、クローンやよく分からない別ブランドではなさそうです。
URLのややこしさと偽物サイト
一度自分も引っかかってしまったので、軽めの注意喚起です。「AI humanizer」と似た名前を使い、同じキーワードで広告を出しているサイトがたくさんあります。何人かから「本物の Clever AI Humanizer ってどれ?」とDMが来たのですが、全然別の有料サイトに飛ばされ、「Pro機能」を課金しろと言われたそうです。
整理すると:
- Clever AI Humanizer 本体(https://aihumanizer.net/ja)
- 自分が見た範囲では:
- 有料プランなし
- 定期サブスクなし
- 「9.99ドルで5,000語アンロック」系のポップアップもなし
もしGoogle広告をクリックしてクレカを登録させられたなら、それはこのツールではありません。
テスト方法(完全にAI対AI)
できるだけ厳しい条件で試したかったので、甘い条件は一切つけませんでした。
- ChatGPT 5.2 に「Clever AI Humanizer についての完全AI記事」を執筆させる
- 人間による修正ゼロ
- そのままコピペ
- その出力を Clever AI Humanizer の Simple Academic モードに通す
- 出てきた文章を、複数のAI検出ツールでチェック
- さらに ChatGPT 5.2 に、その書き直し結果を評価させる
こうすることで「最初の文章がもともと人間っぽかったのでは?」という逃げ道をなくしています。完全にマシン同士のやり取りです。
Simple Academicモード:あえて一番キツい設定を選んだ理由
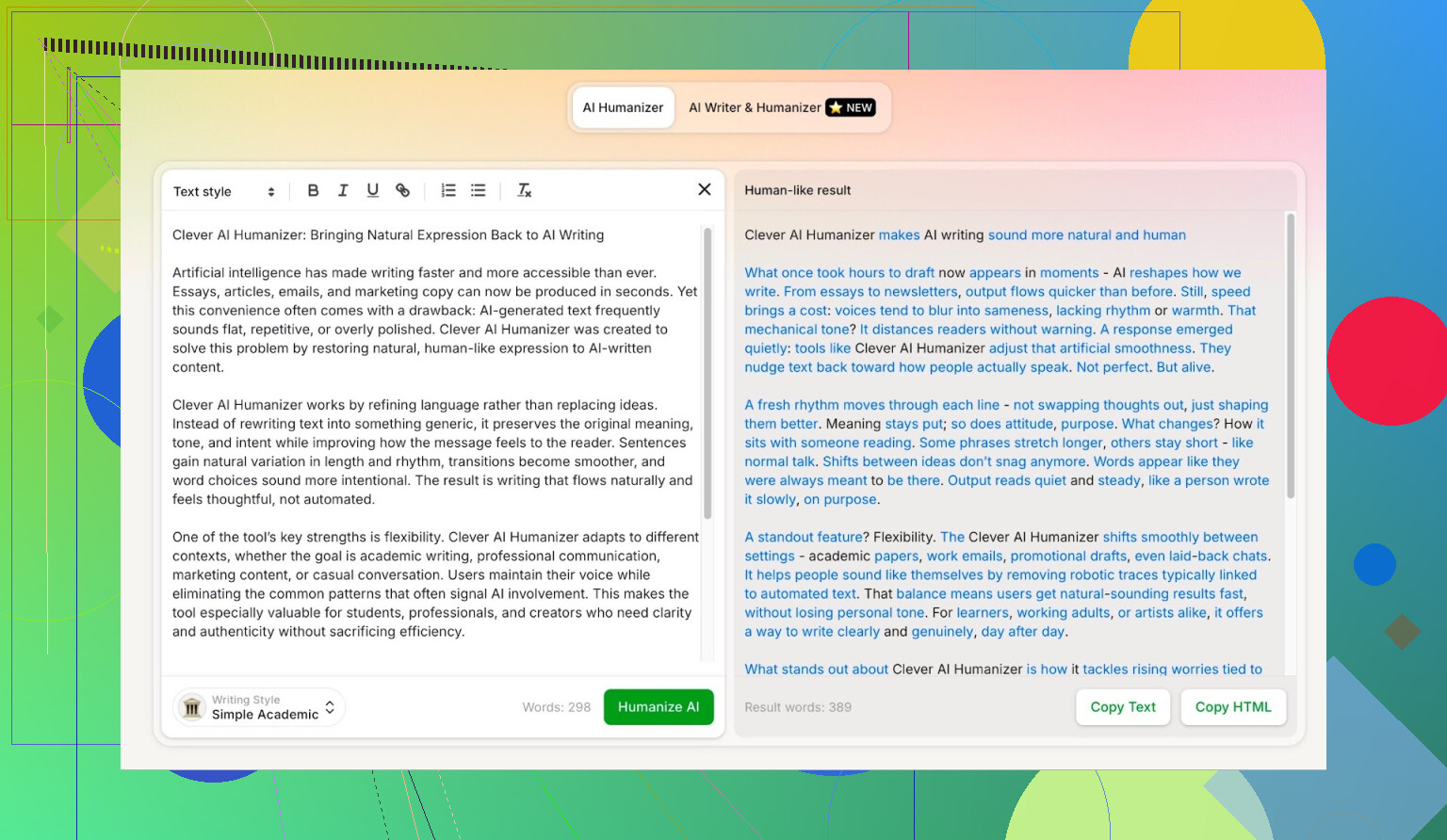
カジュアル系やブログ調のような、ゆるいスタイルは選びませんでした。最初から Simple Academic 一択です。
このモードの体感としては:
- ちゃんと読めるが、論文ほどガチガチではない
- 少しフォーマルで、構成が整理されている
- それなりに「アカデミック寄り」の表現だが、修士論文レベルではない
この中間ゾーンは、AI検出ツールが特に「AIっぽい!」と騒ぎ出しやすいところです。文がきれいに整い過ぎるからです。なので、このスタイルで検出をすり抜けられるなら、かなり面白い結果といえます。
ZeroGPT:「信用してないけど、みんな使うから」枠でテスト
ZeroGPT があまり好きではない理由はシンプルで、
「アメリカ合衆国憲法」を100%AI判定した前科 があるからです。
一度それを見ると、信頼度は一気に落ちます。
とはいえ:
- いまだにGoogle検索結果の上位に出てくる
- 多くの人が「とりあえず」で使っている
- なので一応、検証対象に含めました
Clever AI Humanizer の出力結果は:
ZeroGPT:0% AI検出
このツールでこれ以上良いスコアは、まず出ません。
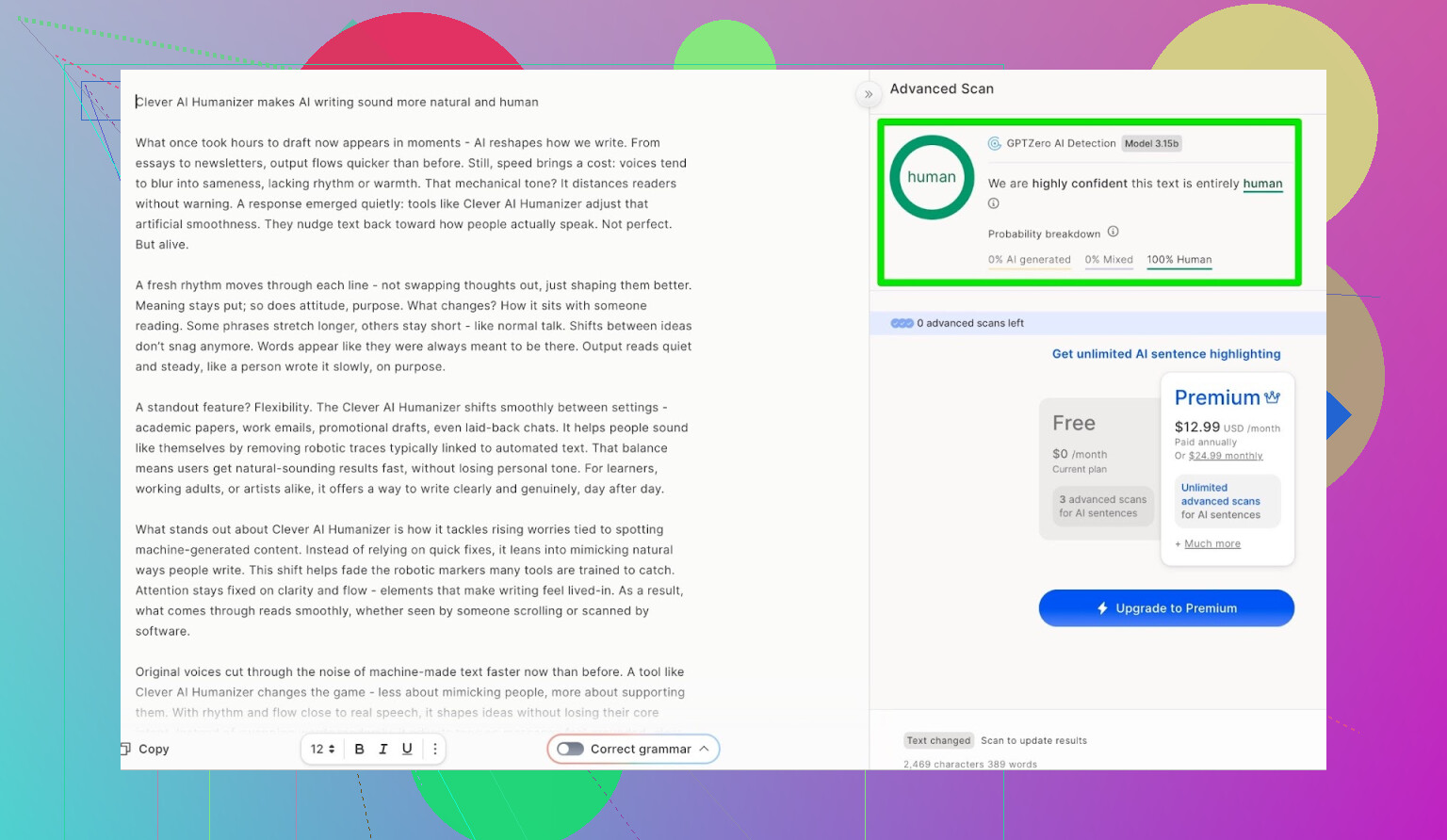
GPTZero:セカンドオピニオンも同じ結論
次に試したのは GPTZero です。
これは学校や大学で広く使われていて、「一番怖いツール」として名前が挙がりがちです。
Clever AI Humanizer(Simple Academicモード)の出力は:
- 100% 人間が書いたテキスト
- 0% AI
という判定でした。
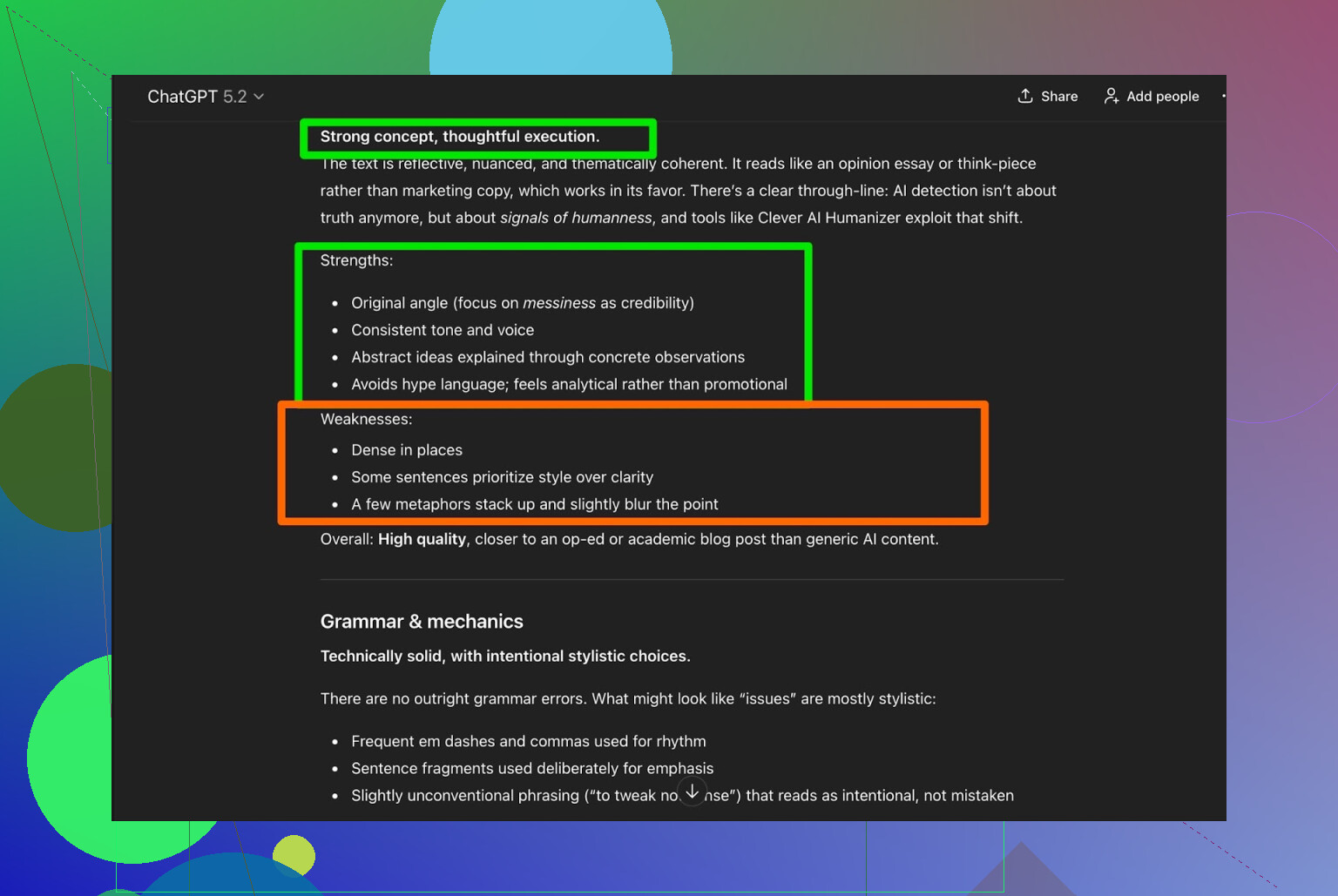
つまり、一般的に最もよく使われている2つの検出ツールでは、どちらも完璧なスコアで通過したことになります。
でも、内容は「読めたもんじゃない」になっていないか?
多くの人間化ツールがつまずくのはここです。
検出ツールは回避できても、肝心の文章が「翻訳アプリ4往復後のレポート」みたいな、妙な仕上がりになるパターンです。
そこで、Clever AI Humanizer の出力を ChatGPT 5.2 に読ませて分析してもらいました。

ざっくりした評価としては:
- 文法: 問題なし
- 文体: Simple Academic のイメージにだいたい合っている
- 総評: それでも 人間による最終チェックを推奨
この点については、自分も完全に同意です。現実として、
どんなAI生成文・AI人間化文でも、人間の読み直しを入れた方がいい
というのは変わりません。
「人間による編集は一切不要です」と言い切るツールがあれば、おそらくそれは宣伝文句であって事実ではないと思った方がいいです。
Clever AI Humanizer内蔵のAI Writerも試してみた
別ツールとして、こんなページもあります:
https://aihumanizer.net/jaai-writer
ここからが少し面白いところです。従来の流れだと:
LLMで生成 → コピペ → 人間化ツールに投入 → うまくいくか祈る
ですが、このAI Writerを使うと:
- 生成と人間化をワンステップでやってくれる
- 文の構造やスタイルを、最初から「人間っぽく」設計できる
というメリットがあります。自分で生成したAI文を後から無理やり書き換えるよりも、ツール側が最初からパターンを崩して作った方が、典型的な「AIくささ」を避けやすいからです。
テスト内容は:
- 文体:Casual(カジュアル)
- トピック:AI人間化、かつ Clever AI Humanizer に言及すること
- プロンプト内に、わざと小さなミスを混ぜて、挙動を見る
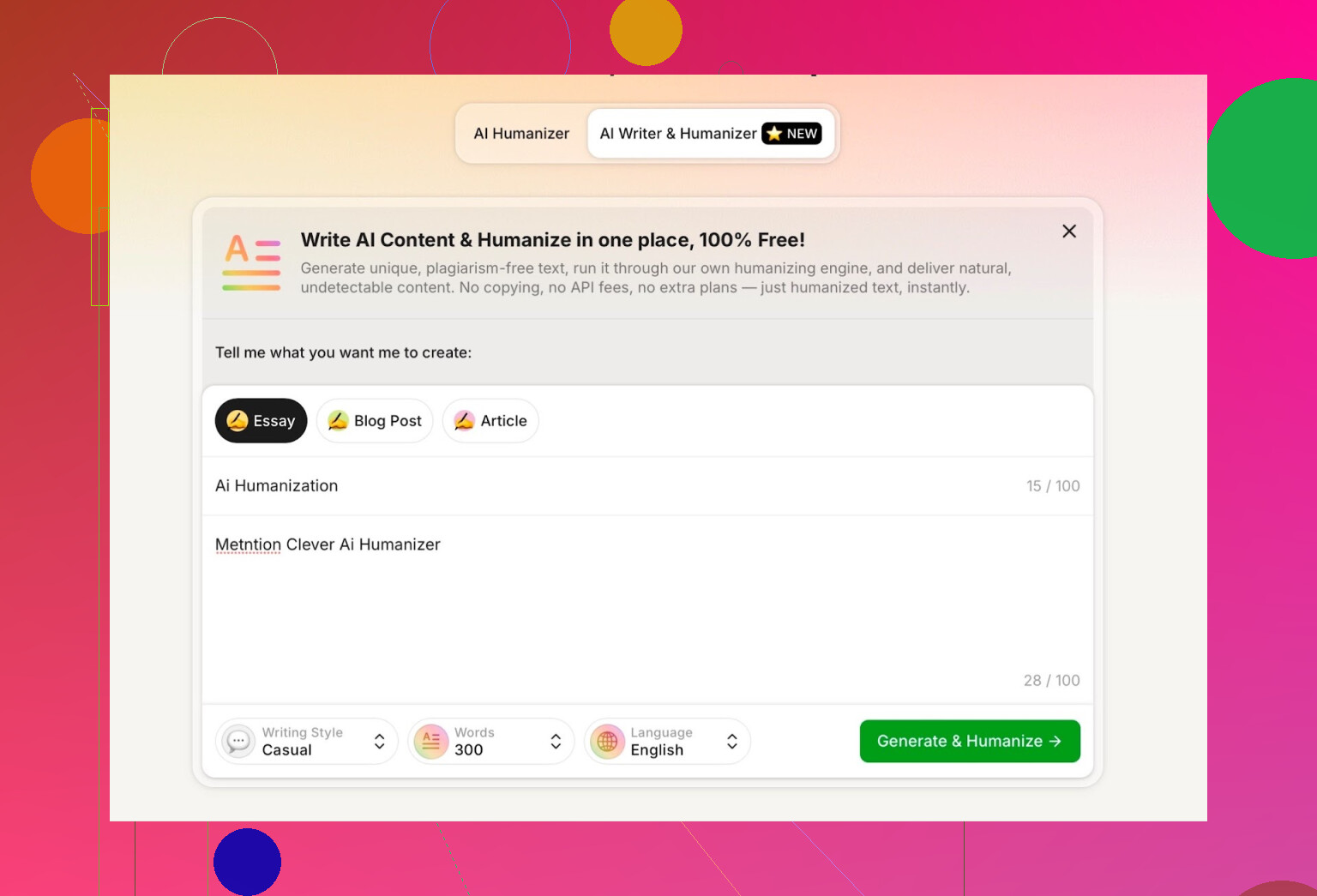
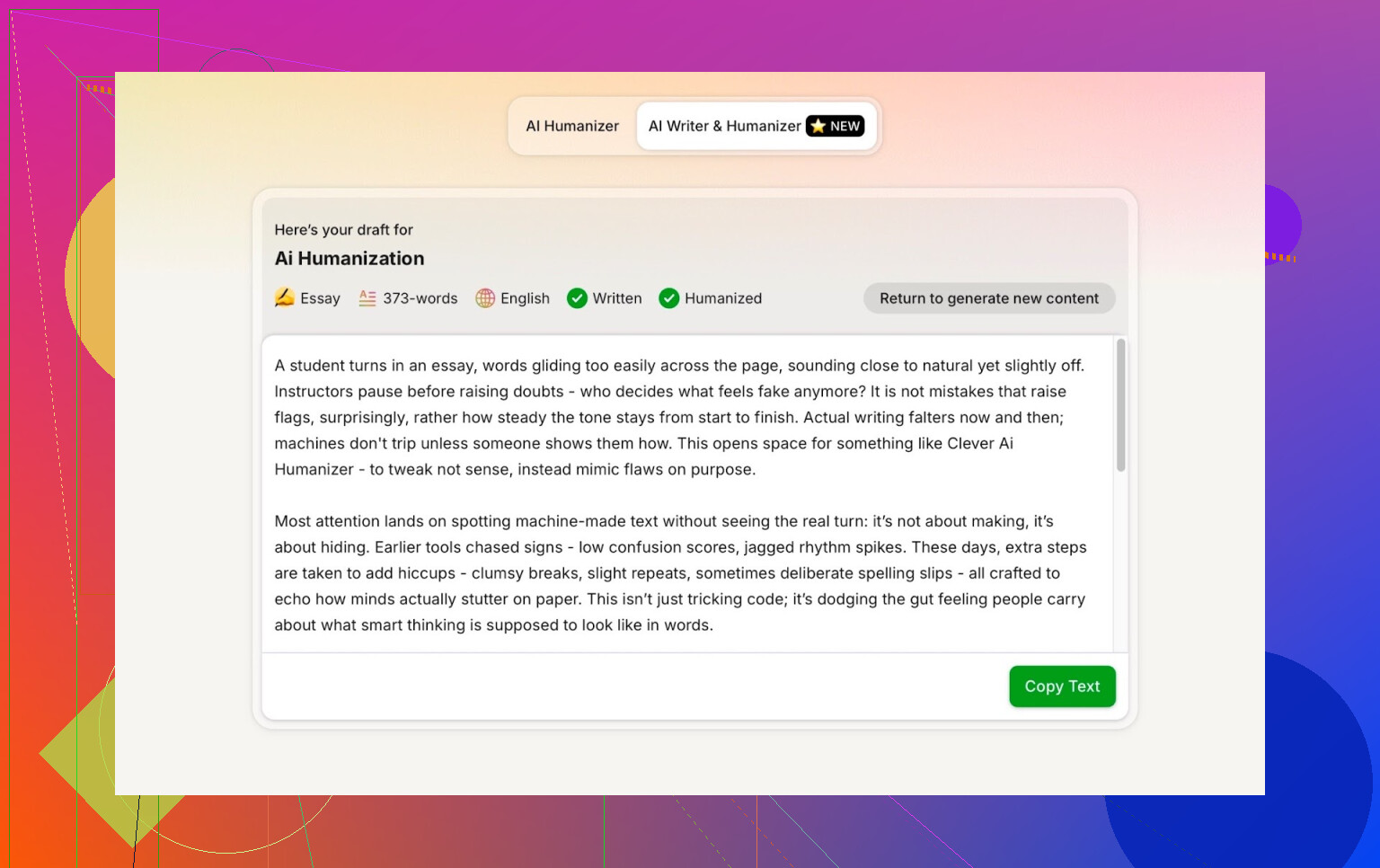
出てきた文章は、自然で会話調。こちらのタイポを、変な形で真似したりもしませんでした。
一つ気になった点:
- 300語で書いてほしい と指定
- 実際には 300語オーバー の出力
300と言ったら300にしてほしい。412語は求めていません。レポート課題やコンテンツ制作で、語数の上限・指定がシビアなときには、これは普通に困るポイントです。
これが、現時点での自分の最初の不満点です。
AI Writer出力の検出スコア
AI Writerが生成した文章を、以下のツールで検査しました。
- GPTZero
- ZeroGPT
- 追加で QuillBot detector
結果は:
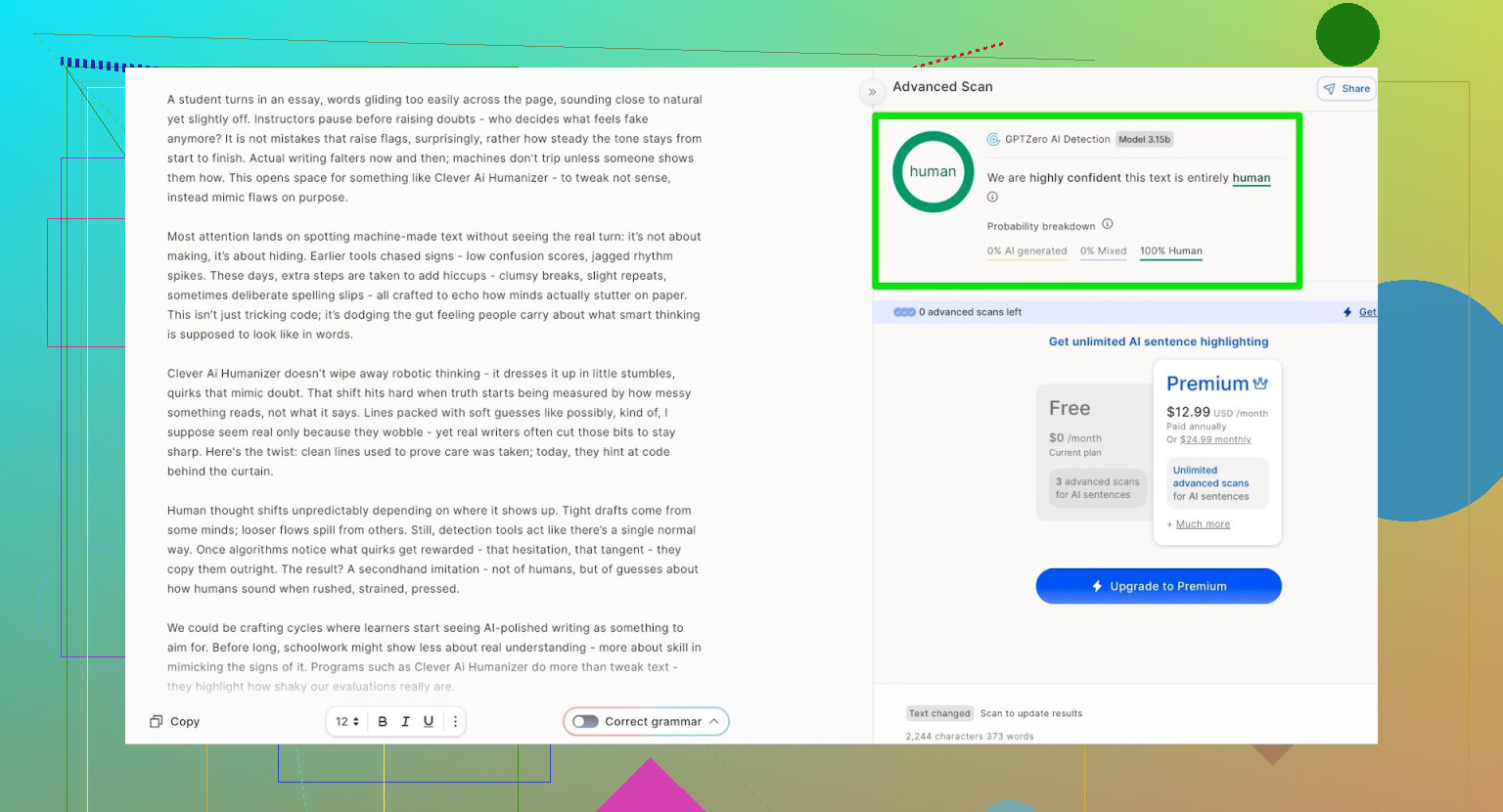
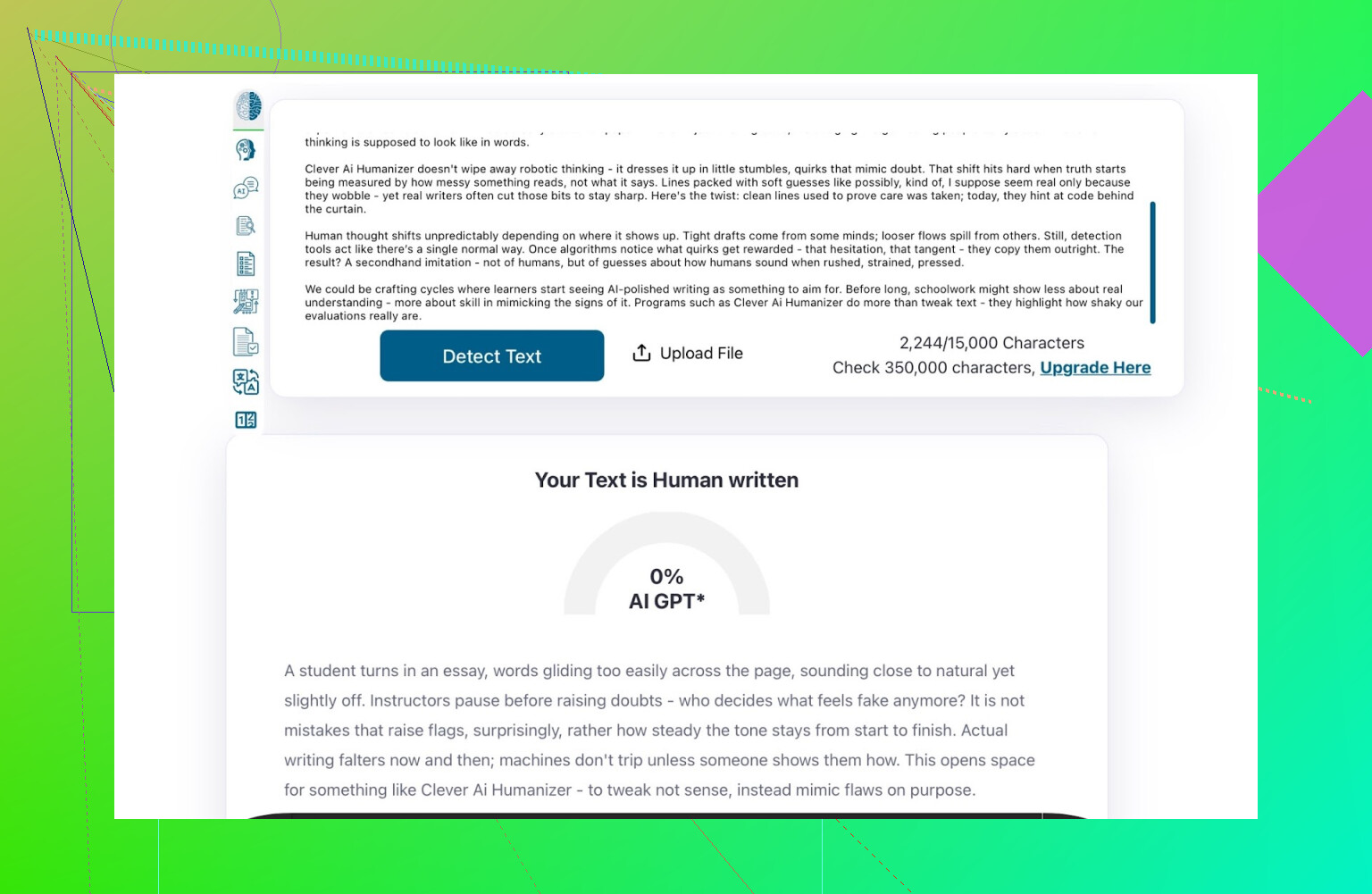
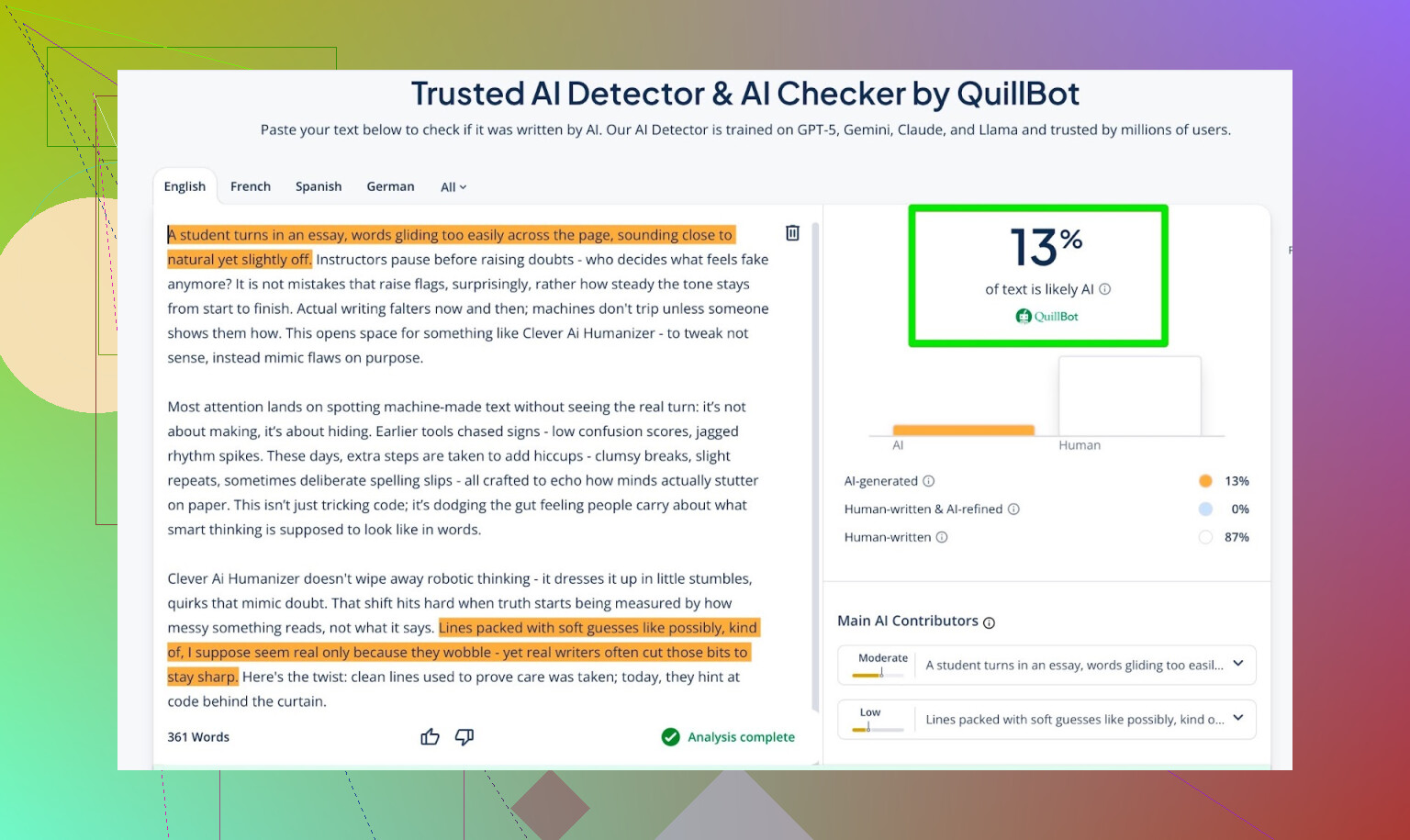
- GPTZero:0% AI
- ZeroGPT:0% AI、100%人間
- QuillBot:13% AI
QuillBotだけ、わずかに「AI的なパターン」を検出しましたが、それでも大半は人間的と判断しています。
トータルでは、かなり良好な数字です。
ChatGPT 5.2にAI Writerの出力を評価させてみた
自分が一番気にしていたのは、「検出器をごまかせるか」だけではなく、
- 人が書いたように聞こえるか
- 文体やトーンが一貫しているか
- 自然な読み心地になっているか
という点です。
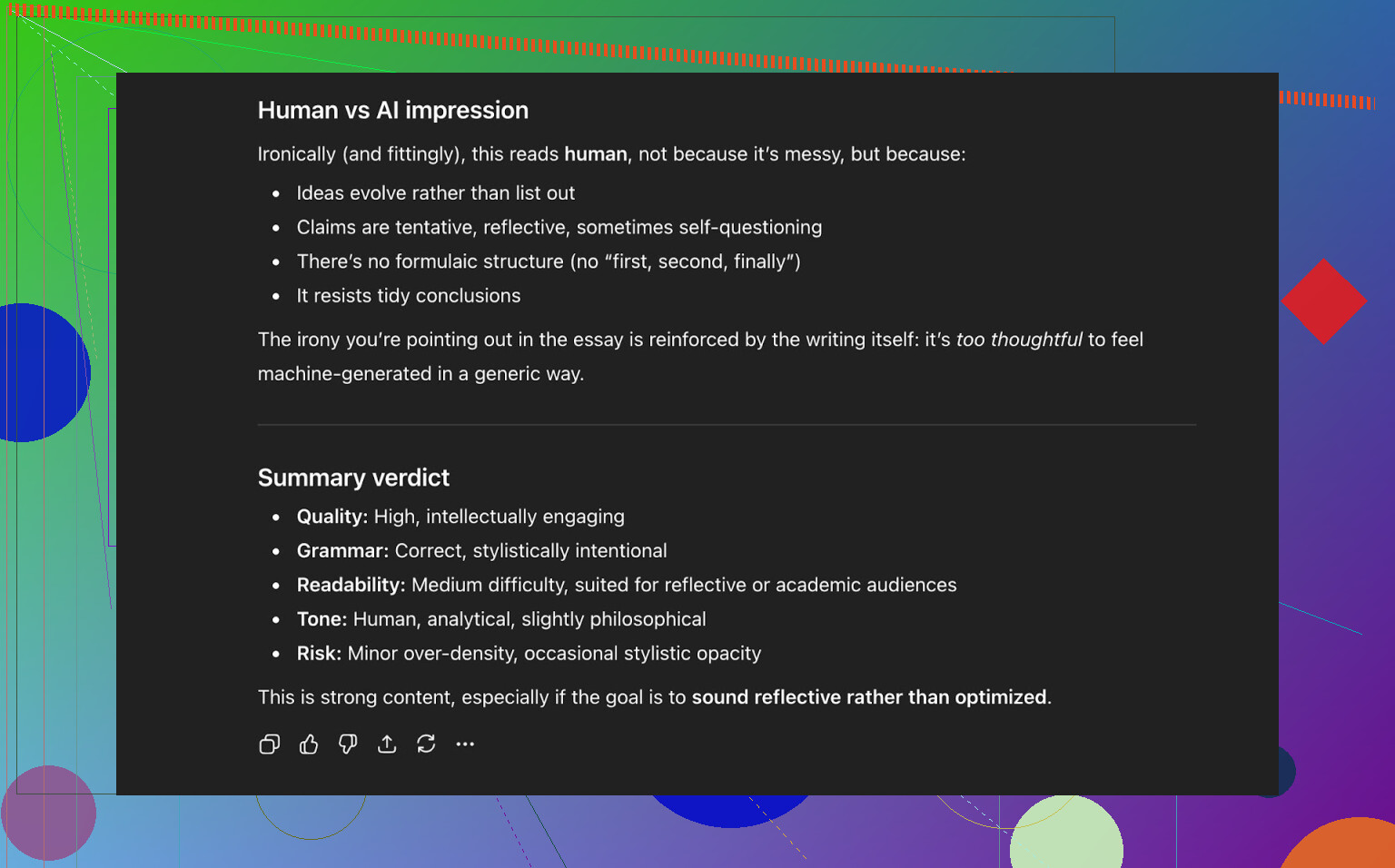
そこで、AI Writerの文章をそのまま ChatGPT 5.2 に渡し、「人間が書いたように感じるか/AIが書いたように感じるか」を判定してもらいました。
ChatGPT 5.2の結論:
- 人間が書いた文章として読める
- クオリティは高い
- 文法や構成に目立った破綻はなし
つまり、この時点でその文章は:
- 公開されているAI検出ツール3つを、かなり良いスコアで通過しつつ
- 現行のLLMの判断でも「人間文っぽい」と見なされた
ということになります。
他の人間化ツールとの比較
自分でテストした範囲だと、Clever AI Humanizer は、よく名前の挙がる他ツールよりも総合的に良い結果を出しました。
以下はそのときのざっくりしたまとめ表です:
| Tool | Free | AI detector score |
| ⭐ Clever AI Humanizer | Yes | 6% |
| Grammarly AI Humanizer | Yes | 88% |
| UnAIMyText | Yes | 84% |
| Ahrefs AI Humanizer | Yes | 90% |
| Humanizer AI Pro | Limited | 79% |
| Walter Writes AI | No | 18% |
| StealthGPT | No | 14% |
| Undetectable AI | No | 11% |
| WriteHuman AI | No | 16% |
| BypassGPT | Limited | 22% |
自分の実測テストで、Clever AI Humanizerが上回ったツール:
- Grammarly AI Humanizer
- UnAIMyText
- Ahrefs AI Humanizer
- Humanizer AI Pro
- Walter Writes AI
- StealthGPT
- Undetectable AI
- WriteHuman AI
- BypassGPT
念のため補足しておくと、この表はあくまで「検出ツールのスコア」を基準にしたもので、「どの文章が一番心地よく読めるか」という主観評価とは別です。
Clever AI Humanizerの弱点・物足りない点
魔法のツールではないので、もちろん欠点もあります。
気になったところ:
- 語数コントロールが緩い
- 300語指定でも、280〜370語くらいのブレは普通にある
- パターンが残ることもある
- ツールやモデルによっては、一部がまだAIっぽいと判定される場合もある
- 内容のズレ(ドリフト)
- 元テキストをきっちりトレースするというより、思った以上に大胆に書き換えることもある
良い面としては:
- 文法品質: 体感では8〜9/10くらい
- 文章の流れはスムーズで、1〜2行ごとに引っかかるような不自然さは少ない
- 意図的な誤字(例:「I was」を「i was」にするなど)を混ぜて検出回避を狙うような、悪質なテクニックは使っていない
最後のポイントは割と重要です。一部のツールは、わざと間違いを入れて「人間っぽさ」を演出しようとしますが、それによって検出ツールはごまかせても、文章としての質は確実に落ちます。
不思議な点:0%AIでも、完全に「人間感」があるとは限らない
これは言語化が難しいのですが、複数の検出ツールで 0% AI 判定になった文章でも、どこか「マシンっぽさ」を感じることがあります。話題の展開の仕方、情報の並べ方、妙に整ったリズムなどです。
Clever AI Humanizerは他よりうまく隠せている方ですが、完全にその「匂い」が消えるわけではありません。これはツールの欠点というより、現時点のAIエコシステム全体の限界に近い話です。
状況としては、完全にイタチごっこです。
- 検出ツールが賢くなる
- 人間化ツールがそれに対応する
- 検出ツールがまたアップデートされる
- 以下、繰り返し
「未来永劫使える完全ステルスツール」を期待すると、まず間違いなく裏切られます。
結局、現時点で「一番良い」無料人間化ツールなのか?
自分が実際に試して、検出ツールとLLM判定の両方を見た 無料ツール の範囲に限れば:
- Clever AI Humanizer は、今のところ一番上に置いてよいと思っています。
- 特に、以下の2機能を両方持っている点が大きいです:
- 既存テキストを人間化するツール
- 最初から人間っぽく書いてくれる統合型AI Writer
とはいえ、最終的には必ず:
- 自分の目で読み直し
- おかしな部分を手で直し
- 自分の声や文体に合うようにトーンを整える
という作業は必要です。
もしあなたの疑問が、
「特に無料で使えるものとして、今Clever AI Humanizerを試す価値はある?」
というものであれば、自分のテスト結果に基づけば、答えは「ある」と言えます。
さらに深掘りしたい人向けの参考リンク
Reddit上には、スクリーンショット付きの検証やレビューもいくつか上がっています。
-
AI人間化ツールの総合比較と検出結果まとめ:
https://www.reddit.com/r/DataRecoveryHelp/comments/1oqwdib/best_ai_humanizer/?tl=ja -
Clever AI Humanizer にフォーカスした個別レビュー:
https://www.reddit.com/r/DataRecoveryHelp/comments/1ptugsf/clever_ai_humanizer_review/?tl=ja
Clever AI Humanizerを使うなら、あくまで:
- 補助ツール であって、完全な代替ではない
- 「70〜90%まで自動で持っていく」ための道具
- 最終的な品質は、それをチェックする人間しだい
くらいのイメージで扱うのがちょうどいいと思います。
最後に文章に責任を持つのは、やはり人間側です。
短く言うと: 検出ツールのスコアを眺めたり、ほかのAIに意見を聞いたりするだけでは、あなたが欲しい「本当のユーザーからの率直なフィードバック」は手に入らない。それは全体の 一部 ではあるけれど、いちばん安易な部分でもある。
あなたはすでに @mikeappsreviewer が検出ツールの比較テストや構造化テストをやっているのを見ているはず。あれは有用だけれど、それでもまだ、「午前1時にヘトヘトになりながらレポートを終わらせようとしている人」や「20本の記事をまとめて処理して今にも辞めそうなコンテンツマネージャー」が使ったときに、このツールがどう“感じられるか”までは教えてくれない。
本当に現場での手応えが欲しいなら、こんなことをやるといい:
-
使っている“その瞬間”にフィードバックを埋め込む
- 実行のたびに、3クリックで終わるミニアンケート:
- 「文体の印象: [機械っぽい] [まあ自然] [かなり人間っぽい]」
- 「この出力は、そのまま提出しても安全だと感じましたか? [はい/いいえ]」
- それに加えて、任意入力の小さなテキスト欄: 「何がイラッとしましたか?」
- 「何が良かったですか?」とは聞かないこと。そう聞くとお世辞ばかり集まる。「どこがダメでしたか」と聞く。
- 実行のたびに、3クリックで終わるミニアンケート:
-
意見ではなく“行動”を追う
- 計測するもの:
- ユーザーが「再生成」を押した回数
- (エディタがあるなら)出力直後にどれくらいテキストを手直ししたか
- セッション途中の離脱
- 1回の入力で3〜4回も再生成されているなら、アンケート結果が良く見えても、そのツールは「失敗している」と自分で語っているようなもの。
- 計測するもの:
-
無差別なトラフィックではなく、狙いを絞った実ユーザーテストをする
「インターネット全体」ではなく、小さくて具体的なグループを集める:- AI検出を避けたい学生
- フリーランスライターやコンテンツ制作会社
- 英語が母語でない人で、文章を磨きたい人
彼らに提供するもの: - 非公開のテスト用スペース
- 固定された少数のタスク(エッセイの導入を書き直す、LinkedIn投稿を磨くなど)
- 1人あたり10〜15分の通話または画面録画セッション
アマゾンギフト券やプレミアム無料利用などでインセンティブを出す。こういった20人から得る質的フィードバックは、匿名の2,000クリックよりよほど価値がある。
-
自分のツールをベースラインとA/Bテストする
「これは良いか?」ではなく「これは Xより良いか?」と聞く。
こっそり次のように出し分けられる:- バージョンA: 生のLLM出力
- バージョンB: あなたの「人間味付け」出力
テスターにはどちらがどれか伏せたまま見せて、こう尋ねる: - 「どちらの方が“人間が書いた”感じがしますか?」
- 「実際に提出/投稿するとしたらどちらを選びますか?」
ここでわざわざ検出ツールの話を持ち出す必要はない。
-
わざと“敵意ある”レビュアーを使う
AIコンテンツが大嫌いな人や、超細かい編集者タイプを探す。
彼らにはこう伝える:- 「新人ライターがこの原稿を出してきたと思って、徹底的にダメ出ししてください」
声のトーン、繰り返し、硬さ、論理の流れについての指摘は、「ZeroGPTで0%AIでした」という情報よりはるかに強力。
- 「新人ライターがこの原稿を出してきたと思って、徹底的にダメ出ししてください」
-
自分で“公開ドッグフーディング”をするが、正直に明かす
自分の Clever AI Humanizer の出力を実際に使う:- プロダクトサイトのコピー
- リリースノート
- ブログ記事
そして末尾に小さく一文を足す:
「この投稿は Clever AI Humanizer で下書きし、その後人間が軽く編集しました。違和感を覚えた箇所があればお知らせください。」
文句を言うほど気にしてくれる人たちから、容赦ない生のフィードバックが集まる。 -
“最高のケース”だけでなく“失敗パターン”をテストする
きれいでフォーマルな文章なら、ほとんどのツールはそれなりに見える。むしろテストすべきなのは:- カオスなプロンプト
- 崩れた英語
- スラング、絵文字、変なフォーマット
- メール件名のような超短文
ユーザーにはこう聞く: - 「どこで完全に外しましたか?」
その失敗例を記録し、分類する。
-
“雰囲気の違和感”問題を観察する
検出ツールで0%AIと出ても、文章が依然として「機械的な型」っぽく感じられることは多い。同じリズム、きれいすぎる段落構成、予測可能なつなぎ表現など。
それは検出ツールでは見抜けない。
だが次のようにすれば見えてくる:- ユーザーに「これは“あなた自身”が書いたように聞こえますか?」と聞く
- 変換前と変換後を貼り付けてもらい、「どちらを上司や先生に本当に送りたいですか」と尋ねる。
-
検出ツール回避に偏りすぎない
ここは @mikeappsreviewer の「検出ツール重視」の姿勢に少し異議ありで、ユーザーは「0%AI」が欲しいと 思い込んで はいるが、長期的に彼らをつなぎとめる要素はむしろ:- 自分のトーンに合っていること
- 嘘を紛れ込ませないこと
- 変に没個性的なブロガーみたいな文体にされないこと
UXをまず優先し、「検出されにくさ」はその次に置くべき。そうしないと、いずれ負ける“いたちごっこ”に縛られる。
-
自分たちのための“容赦ない品質メーター”を作る
内部向けに、各出力(匿名化したもの)に次をタグ付けする:
- 検出ツールのスコア
- 信頼できる少人数の人間による評価
- ユーザーからのフィードバック(「イラッとした点」)
毎月、ワースト5〜10%の出力をレビューする。そこに改善の宝が眠っている。
具体的な次の一手としては:
- Clever AI Humanizer 上に小さな「βテスター募集」ページを作る。
- 上限を実ユーザー50人程度に絞る。
- 彼らにこういう条件を提示する: 「無料で使える代わりに、毎週“イマイチだった/違和感があった例”を3件必ず送ってください」
あなたは実はユーザーが足りないのではない。足りていないのは「構造化された、痛みを伴うフィードバック」だ。そのためのパイプを作れば、検出ツールのダッシュボードをさらに20枚スクショするよりも、2週間でずっと多くを学べる。
短く言うと: 検出器のスクショやAIによる自己レビューは「実際のユーザーフィードバック」ではなく、あくまでラボ実験です。やっていることは半分正しいですが、聞く相手を間違えています。
@mikeappsreviewer と @kakeru がすでに話した内容を繰り返さない範囲で、いくつか別の観点を挙げます。
-
「動くか?」ではなく「誰に対して動くか?」を聞く
今のところ「自分のAIヒューマナイザーって良いの?」みたいな、万人向けの正解を追いかけている感じがあります。これはかなりぼんやりしています。実際には用途がかなり違います:
- 学生が検出されないようにしたい
- コンテンツライターが下書きを機械っぽくなくしたい
- 非ネイティブ話者がメールを自然にしたい
- マーケターがブランドボイスを維持したい
フィードバックが集まらない原因は「誰でもウェルカムにしておいて、特定のどの層の声もちゃんと聞いていない」ことかもしれません。1〜2セグメントに絞って、その人たち中心にフィードバックループを設計してください。
-
「尖った」プリセットを用意して、どれが乱用されるかを見る
「シンプルアカデミック」「カジュアル」みたいな汎用モードではなく、実生活に寄せてください:
- 「大学エッセイ仕上げ」
- 「LinkedIn 思想リーダー投稿」
- 「マネージャー宛のコールドメール」
- 「ブログ冒頭のテコ入れ」
そのうえで:
- どのプリセットが一番使われているかを計測
- どれが「ほぼ編集なしで全コピー」されているかを計測
- どれが途中で離脱されやすいかを計測
「大学エッセイ仕上げ」が大量に使われるのに、1回出しただけで離脱されるなら、めちゃくちゃ具体的で行動可能な失敗データが手に入ります。検出器のスクショよりずっと価値があります。
-
「自分の声 vs ヒューマナイズ後」の比較機能を入れる
他の人たちの「検出器重視」路線とは少し違う意見ですが、長期的には0% AIかどうかより「その人らしい声かどうか」のほうが重要です。自分らしさが消えたら、検出不能でもユーザーは離れます。
ユーザーに:
- 元テキストを貼ってもらう
- ヒューマナイズ後の結果を出す
- 差分をざっくり表示:
- 「フォーマル度: +20%」
- 「パーソナルさ: -30%」
- 「文の長さ: +15%」
そのうえで、こう聞きます:
「これはまだ“あなたらしい”と感じますか?」 [はい / まあまあ / いいえ]
この1問のほうが「5段階で評価してください」より、ずっと正直なシグナルになります。
-
「ご褒美」だけでなく、ネガティブインセンティブを入れる
多くの人がギフトカードやβ特典の話をしますが、問題は「特典ほしさに、あなたが聞きたがっている答えを言ってしまう」ことです。
こんな仕掛けを試してください:
- 「本当にひどい出力を3件送ってくれたら(スクショ or ペースト)、Xクレジット追加」
- 「たくさん使ってくれた人」を報酬するのではなく、「失敗例を見つけてくれた人」を報酬する
こうすると「弱点探し」にフォーカスが集まり、「まあまあ良かったです、ありがとう」みたいな曖昧なコメントより役立つ情報が集まります。
-
社内用の「ワースト事例集(Hall of Shame)」を作る
ベストケースで上手く動くことは、すでにわかっているはずです。足りないのは次のようなものを集めた山です:
- 最悪の出力
- 一番気まずい文章
- 意味が変わってしまった例
- ただの汎用AIブロガーみたいな文になってしまった例
週に一度、次のようなセッションを抽出して:
- リジェネレート連打が一番多い50セッション
- 出力後に最速で閉じられた50セッション
その中から10〜20件を手で見て、なぜダメだったかタグ付けしてください。そのパターン認識こそ改善の出発点です。
-
ファネルのどこかに「わざと摩擦」を入れる
「ログイン不要・超高速・超低摩擦」に最適化しているはずですが、それはトラフィックには良くても、フィードバックには最悪です。
別枠として「プロ向けフィードバックサンドボックス」を用意してもよいでしょう:
- 簡単なサインアップ(メール程度)を必須にする
- 上限やモードを増やす
- その代わりにユーザーには:
- 出力ごとに「自然 / ロボっぽい」「テーマ通り / 逸脱」の2チェックをしてもらう
- 任意で「学校 / 仕事 / SNS などの用途」を入力してもらう
数十秒かけてサインアップしてくれる人のほうが、その場限りの通りすがりより、ずっと本音のフィードバックをくれます。
-
期待値をUIの中で明示しておく
「十分良ければ、ワンクリックでコピペして終わりでしょ」という暗黙の前提を持っているなら、そこは修正したほうがいいです。現実の人はそんなふうにツールを扱いません。
UIにこんな文を入れてください:
「これはあなたを70〜90%まで連れていくツールです。送信前に、必ず自分の目でひと通りチェックしてください。」
そのうえで、こう聞きます:
- 「どのくらい手直しが必要でしたか?」 [少しだけ / かなり / ほぼ書き直した]
長文アンケート不要で、かなり正直なフィードバックが取れます。
- 「どのくらい手直しが必要でしたか?」 [少しだけ / かなり / ほぼ書き直した]
-
競合との比較を「痛くない」形で活用する
実際、ユーザーはGrammarly のヒューマナイザーや Ahrefs、Undetectable なども試している前提で動いたほうがよいです。それを無視するより、データとして利用してください。
小さなチェック項目を追加します:
- 「Grammarly や Ahrefs のAIヒューマナイザーなど、似たツールを使ったことがありますか?
- はい、こちらのほうが良い
- はい、こちらのほうが悪い
- だいたい同じ
- 他は使ったことがない」
ブランディングでマウントを取る必要はありません。ただ淡々とデータを取り、
「品質」だけでなく「ポジショニング」を把握してください。 - 「Grammarly や Ahrefs のAIヒューマナイザーなど、似たツールを使ったことがありますか?
-
「検出器で勝つ = プロダクトで勝つ」と思い込むのをやめる
@mikeappsreviewer のスクショを見る限り、Clever AI Humanizer は一般公開されている検出器にはかなり強いようです。それはそれで良いことです。ただ、自問してみてください:
- 「もし明日、すべての検出器が消えたら、このツールはまだ使う価値があるか?」
正直な答えが「微妙かも」なら、ロードマップは次の方向にもっと寄せるべきです:
- パーソナライズ
- トーン制御
- 安全性(事実誤認やでたらめを入れない)
- 元の意図の保持
検出器の軍拡競争が落ち着いたあとに生き残るのは、このあたりの価値です。
-
Clever AI Humanizer を「共創ツール」として明示的に位置づける
「透明マント」みたいな存在だと装うのをやめたほうが、はるかに良いフィードバックが集まります。
UIの例:
「AIが下書き、Clever AI Humanizer が整え、最後はあなたが仕上げます。」
こういう前提を敷いておくと、ユーザーは自然に:
- 「何を手助けしてくれたか」
- 「どこで逆にやりづらくなったか」
を考えるようになります。
そのフレーミングで質問します:
- 「Clever AI Humanizer はあなたの時間を節約しましたか?」 [はい / いいえ]
- 「意味が変わってしまいましたか?」 [はい / いいえ]
「時間は節約されていない」かつ「意味は変わった」という交差点こそ、最も問題の大きい領域です。
すぐ実装できる、かなり実務的な一手はこれです:
- すべての出力のあとに、3つのボタンを出す:
- 「このまま送れる」
- 「使うけど手直しが必要」
- 「これは使えない」
- いちばん下を選んだときだけ、追加入力を1つだけ聞く:
- 「ロボっぽすぎる / トピックから外れた / トーンが違う / 英語がおかしい / その他」
このミニフローをスケールさせるだけで、Clever AI Humanizer の実運用での性能がどうなのか、検出器テストや「他LLMに“だませたか”を聞く」よりもはるかに多くの示唆が得られます。
別の角度からの簡潔な分析的コメントです。UX やテストについてはすでに他の人が深掘りしているので、それ以外の点に絞ります。
1. 「本物のフィードバック」を意見ではなくデータとして扱う
検出器の実験を増やす代わりに、Clever AI Humanizer の周辺にハードな指標を組み込みましょう。
追うべきコア指標
- 完了率: テキスト貼り付け → humanize 実行 → コピーまで到達した割合
- 入力あたりの再生成回数: 再生成が多いほど不満足のサイン
- コピーまでの時間: 2〜5秒以内にコピーされるなら、読まずに「量産」している可能性が高い
- 編集意図: 「書式付きでコピー」「プレーンテキストでコピー」「ダウンロード」のどれを押すか。パターンの違いはユースケースの違いに直結しがち
これで、長文でフィードバックを書いてくれる少数の人だけでなく、すべてのセッションからサイレントなフィードバックが入ってきます。
2. 軽量なコホートラベリング
他の人はペルソナターゲティングを勧めていましたが、もっと徹底的にシンプルでいいと思います。
初回利用時に、ボックス上に 1クリックのセレクタを置く:
- 「用途: 学校 / 仕事 / SNS / その他」
ログインなし、摩擦なし。匿名のコホートタグだけ保存します。
すると次が見えてきます:
- 学校: 再生成率・離脱率が最も高い
- 仕事: ページ滞在は長いがコピー率も高い
- SNS: 素早いコピー、文字数は短い、優先最適化対象ではないかもしれない
どのオーディエンスを取りこぼしているか、当てずっぽうで推測する必要がなくなります。
3. 「控えめ」と「攻めた」人間味付けの A/B テスト
現状の Clever AI Humanizer は「検出器回避 + 可読性」に最適化されている印象です。それ自体は悪くないですが、ユーザーが求める編集レベルはまちまちです。
静かなスプリットテストを走らせてみる:
- バージョンA: 変更は最小限、構造を極力保持、軽めの言い換え
- バージョンB: 強めの書き換え、多様な表現、リズムも大きく変える
比較するポイント:
- どちらが「コピーしてすぐ離脱」行動を多く生むか
- どちらが「もう一度実行」ボタンをより多く押させるか
アンケートも「お願いします」も不要です。行動が答えになります。
4. プロダクトの現実チェックとしての長所・短所整理
@kakeru や @andarilhonoturno の説明と比べると、あなたのツールはすでに「平均より上」のバケットに入っていると思いますが、あえてはっきり言語化しておきます。
Clever AI Humanizer の長所
- 現実的なコンテンツでテストしたとき、一般的な AI 検出器に対して高いパフォーマンスを発揮する
- 出力が全体的に読みやすく文法も自然で、一部ツールのような「わざと誤字を混ぜる」テクニックに頼っていない
- Simple Academic や Casual など、実際のライティング状況にそこそこ対応した複数スタイルを用意している
- 生成と人間味付けを一度に行える統合ライターを持ち、典型的な LLM っぽさを減らしている
- 無料かつ軽いオンボーディングで、初期ユーザー獲得とテストデータの流入に向いている
Clever AI Humanizer の短所
- ワードカウントのコントロールが甘く、厳密な課題やブリーフには致命的になる
- ときどき書き換えが強すぎて内容のズレが生まれ、ユーザーが気づかないリスクがある
- AI 検出スコアが 0% でも、構造やリズムが「機械っぽい」と感じられる文章が残ることがある
- 価値提案を検出器中心に置いているため、常にイタチごっこになりやすく、長期的に陳腐化する可能性がある
- 明示的な文体パーソナライズが少なく、ヘビーユーザーほど「自分の文章が全部同じ声に寄っていく」と感じかねない
5. 検出器への過剰最適化をやめて、リピーターへの過剰最適化に振る
@ mikeappsreviewer のテストに見られるような「検出器重視」の姿勢には少し異論があります。検出器のスクリーンショットはマーケとしては役立ちますが、プロダクトゴールとしては脆いです。
より耐久性のあるシグナル:
- 7日以内に再訪するユーザー数
- 再訪ユーザーの中で、時間経過とともに 1セッションあたりの文字数が増えているか (信頼のサイン)
- 同じブラウザや IP が、学校・仕事など複数コンテキストでツールを使っている頻度
リアルユーザーは「検出器が 0% と言ってくれたから」では定着しません。定着理由は:
- 時間を節約してくれた
- 恥をかかせなかった
- 意味を変えなかった
まずはリピート行動に最適化し、その次に検出スコアを追うべきです。
6. 「隠すパターン」ではなく「信頼パターン」を作る
すべての未来の検出器に勝とうとする必要はありません。目指すべきは、次の条件を満たすツールです。
- 意味を壊さない
- トーンを調整可能にする
- 制約や限界を明確に伝える
小さな UI 追加で効き目が大きいのはこれです:
- 出力後に、短く正直なサマリーを表示する
- 「意味の保持度: 高い」
- 「トーンの変化度: 中程度」
- 「文の構造変化度: 高い」
こうした「見える化」でユーザーはあなたを信頼するようになり、その信頼がアンケート以上に質の高いフィードバックを間接的にもたらします。
7. うざがられずに「質的フィードバック」を集める方法
行動ベースのトリガーを借りましょう。
-
同じ入力に対して 3回以上再生成した場合:
- 小さなインラインプロンプトを表示:
- 「まだ足りない点がありますか?5語で教えてください」 [小さなテキストボックス]
これだけで「ロボットっぽい」「主張が変わった」「冗長すぎる」など、かなり本音のコメントが集まります。
- 「まだ足りない点がありますか?5語で教えてください」 [小さなテキストボックス]
- 小さなインラインプロンプトを表示:
-
humanize 実行前にテキストボックス内の編集に 40秒以上かけている場合:
- 「AI テキストを直していますか?自分の文章を磨いていますか?」と聞く
これで Clever AI Humanizer が「AI 修正ツール」として見られているのか「エディタ」として見られているのかが分かり、ロードマップに影響します。
- 「AI テキストを直していますか?自分の文章を磨いていますか?」と聞く
大きなモーダルも「星5つお願いします」も不要で、文脈に沿った小さなナッジだけで十分です。
8. 競合をどう頭の中で位置づけるか
すでに @kakeru などによる比較や、@mikeappsreviewer の検出器寄りのレビューがありますが、それらはベンチマークであって「北極星」ではありません。
他社はこう捉えればよい:
- 「検出回避を最大まで上げて、文体の一貫性や声を捨てた結果」
- 「軽いパラフレーズで安全側に寄りつつ、検出されやすさは受け入れた結果」
Clever AI Humanizer の今の優位性は「読みやすさ」と「検出回避」のバランスです。次の優位性は「パーソナライズ」と「コントロール」であるべきで、単にまた別の検出器でパーセンテージを数ポイント下げることではありません。
今週中に出荷できて、かつプロダクト改善と実世界のシグナル取得の両方に効く具体的な一手を挙げるなら:
- humanize 実行前に 2つのトグルを追加する:
- 「可能な限り構造を保持する」
- 「より人間的に見えるよう構造を変える」
そして、このトグル組み合わせと次を紐づけてログを取る:
- コピー率の高さ
- 再生成回数の少なさ
- 再訪セッションの多さ
検出器のチャートから推測しなくても、「ユーザーが本当に望んでいる人間味付けのタイプ」がすぐに見えてきます。