我开发了一款智能的 AI 人类化工具,旨在让 AI 生成的文本听起来更自然、更真实,但我一直很难从真实用户那里获得坦诚的反馈。我想了解它在真实场景中的表现:它听起来是否真的像人写的?在内容创作和 SEO 方面是否可靠?在哪些地方会失败或让人一眼看出是 AI 生成的?我需要详细、实用的反馈,以便修复问题、提升质量,并确保它对博主、营销人员和日常用户来说是安全、可靠的,能够帮助他们生成听起来更像人写的 AI 内容。
Clever AI Humanizer:我的真实使用体验,附完整证据
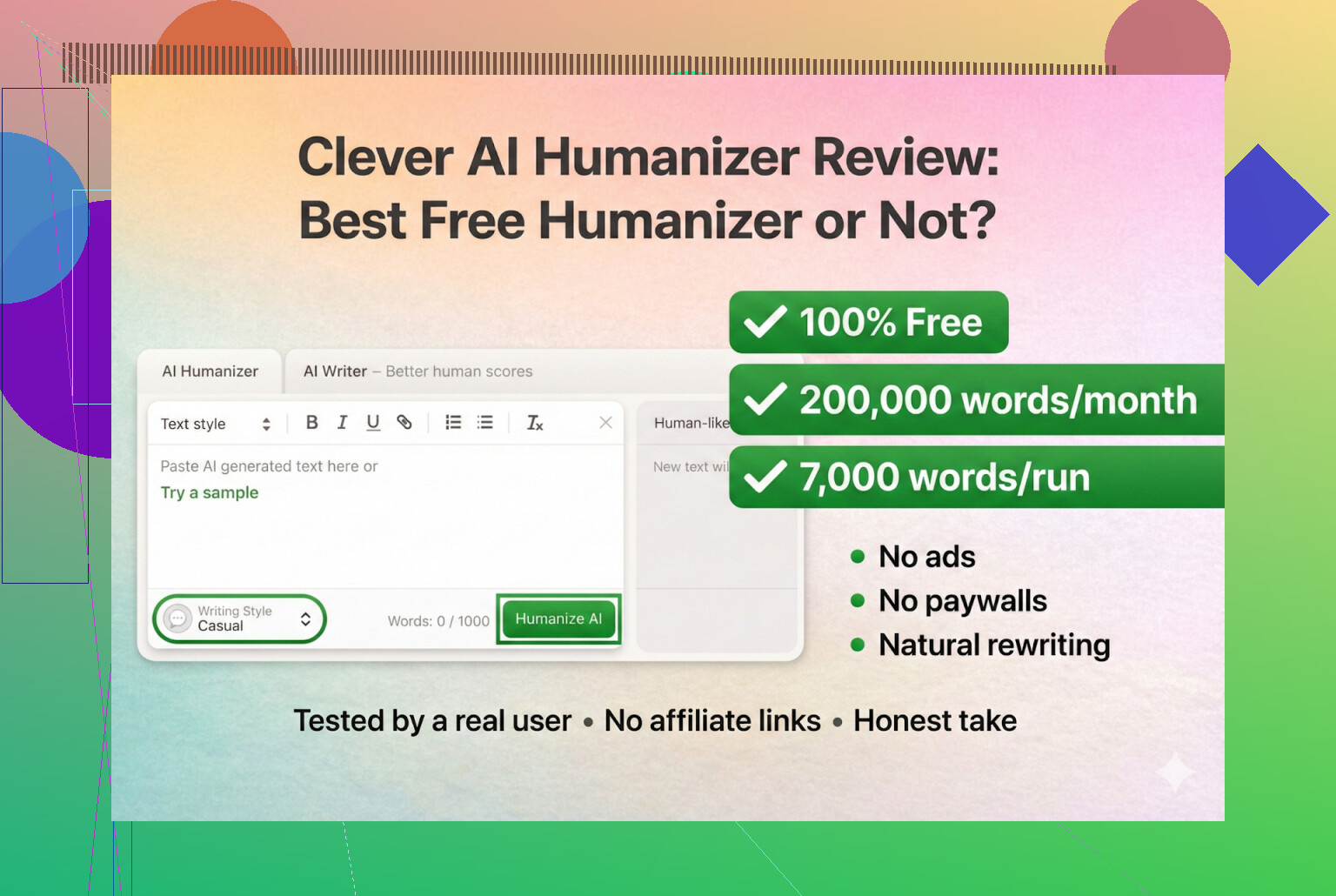
最近我一直在折腾各种“AI 人性化(AI humanizer)”工具,主要是因为在 Discord 和 Reddit 上老是看到有人问:现在到底还有哪些能用。很多工具要么挂了,要么一夜之间变成付费 SaaS,要么悄悄变得越来越差。
所以我干脆只从真正免费的工具开始测试:不用登录,不要信用卡。排在第一的就是:Clever AI Humanizer。
你可以在这里找到它:
Clever AI Humanizer — 最佳100%免费人性化工具
就我目前能确认的来看,这个应该是正主,不是克隆站,也不是奇怪换皮版本。
URL 混乱和“假冒同款”网站
先来一个小小的提醒,因为我自己就踩过坑:现在有一堆“AI humanizer”网站起着类似的名字,还买了同样的关键词广告。好几个人私信问我:“哪个才是真正的 Clever AI Humanizer?”因为他们点进去的是完全不同的站,还要收费解锁所谓“专业版”功能。
说清楚一点:
- Clever AI Humanizer 官方本体(https://aihumanizer.net/zh)
- 目前我看到的情况:
- 没有付费等级
- 没有订阅制
- 没有“9.99 美元再解锁 5000 字”这种弹窗
如果你是点了 Google 广告,然后发现信用卡开始被扣费,那就肯定不是这个工具在干的。
我的测试方式(纯 AI 对打)
我想看它在最糟糕场景下的表现,所以完全不手下留情。
- 让 ChatGPT 5.2 写一篇关于 Clever AI Humanizer 的纯 AI 文章。
- 不做任何人工修改。
- 直接复制粘贴。
- 把这篇内容丢进 Clever AI Humanizer,选择 Simple Academic 模式。
- 把人性化之后的内容拿去跑多个 AI 检测工具。
- 再把结果丢回 ChatGPT 5.2,让它自己判断这段改写后的文本。
这样就不存在“也许原文本来就很像人写的”这种借口,整个流程完全是机器对机器。
Simple Academic 模式:我为什么选了最难伺候的选项
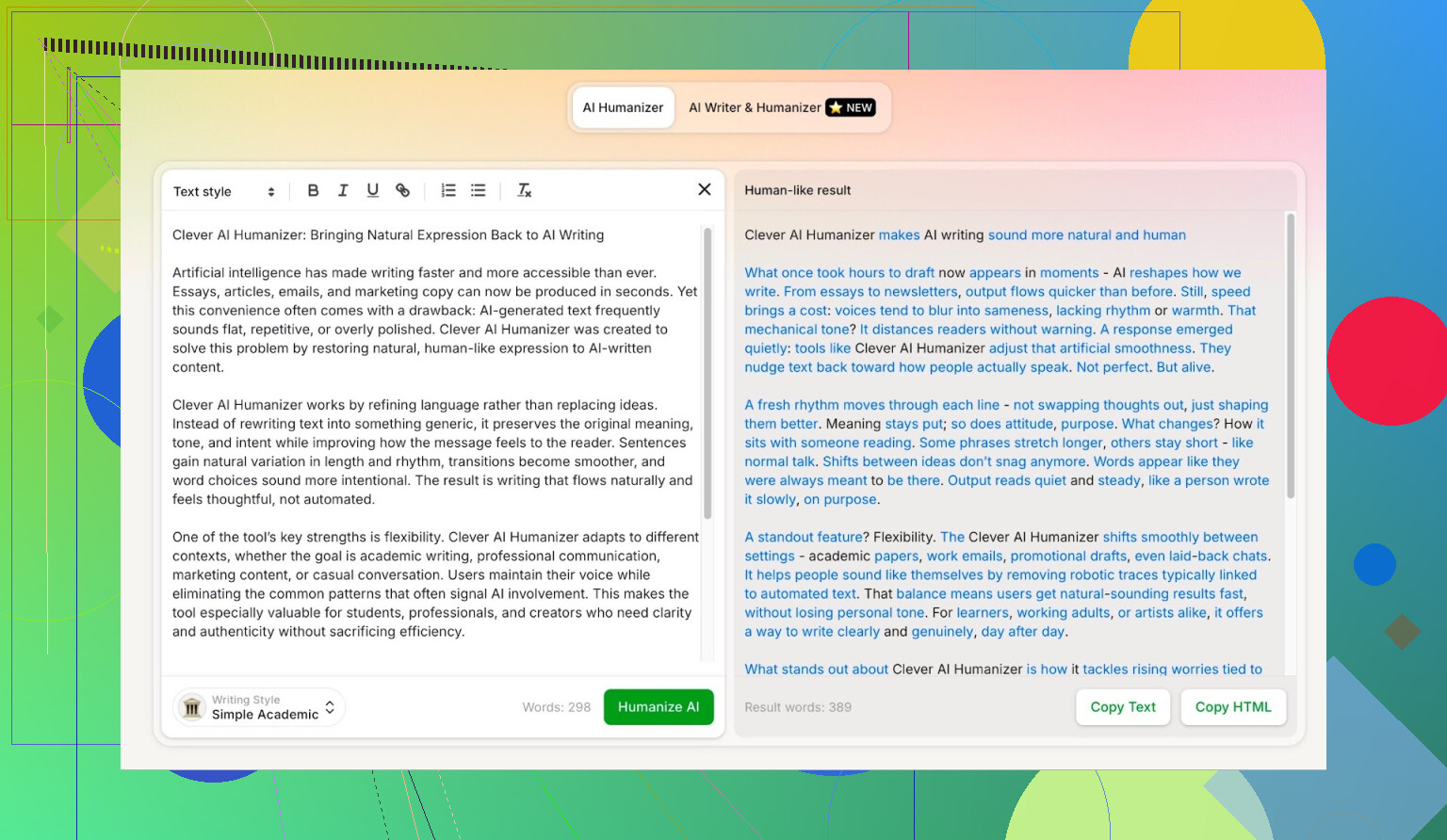
我没有选偏口语的 Casual、Blog 风格,而是直接上了Simple Academic。
实际感觉大概是:
- 依然好读,不是那种期刊级学术黑话
- 稍微正式、结构规整、条理清晰
- 有一点“学术味”,但还没严重到像论文
这种中间位,恰好就是很多 AI 检测器最容易狂喊“AI!”的风格,因为句子太整齐、结构太平衡。如果一个 humanizer 能在这种文风下还能拿到不错的检测分数,那就挺有意思。
ZeroGPT:我不太信,但大家都用,所以也测了
我对 ZeroGPT 的好感度不高,核心原因只有一个:它把美国宪法判成“100% AI”。
看到这种结果,你对它的信任值基本就掉到底了。
但问题在于:
- 它依旧牢牢占着 Google 搜索结果
- 很多人还是用它,因为它排在前面
- 所以我也把它纳入测试
Clever AI Humanizer 输出的检测结果:
ZeroGPT:检测到 0% AI。
就这个工具的标准来说,这已经是能拿到的最理想分数了。
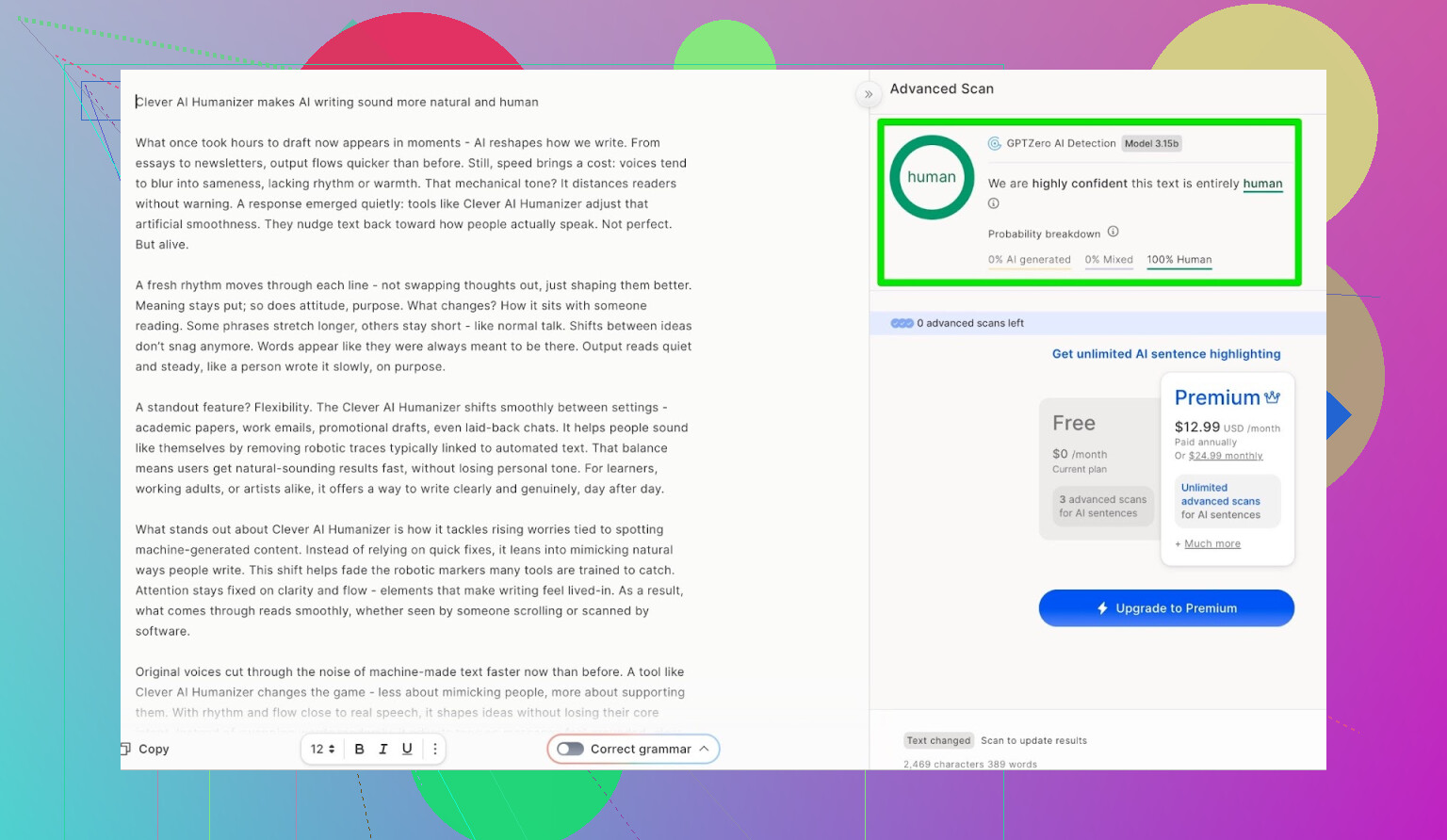
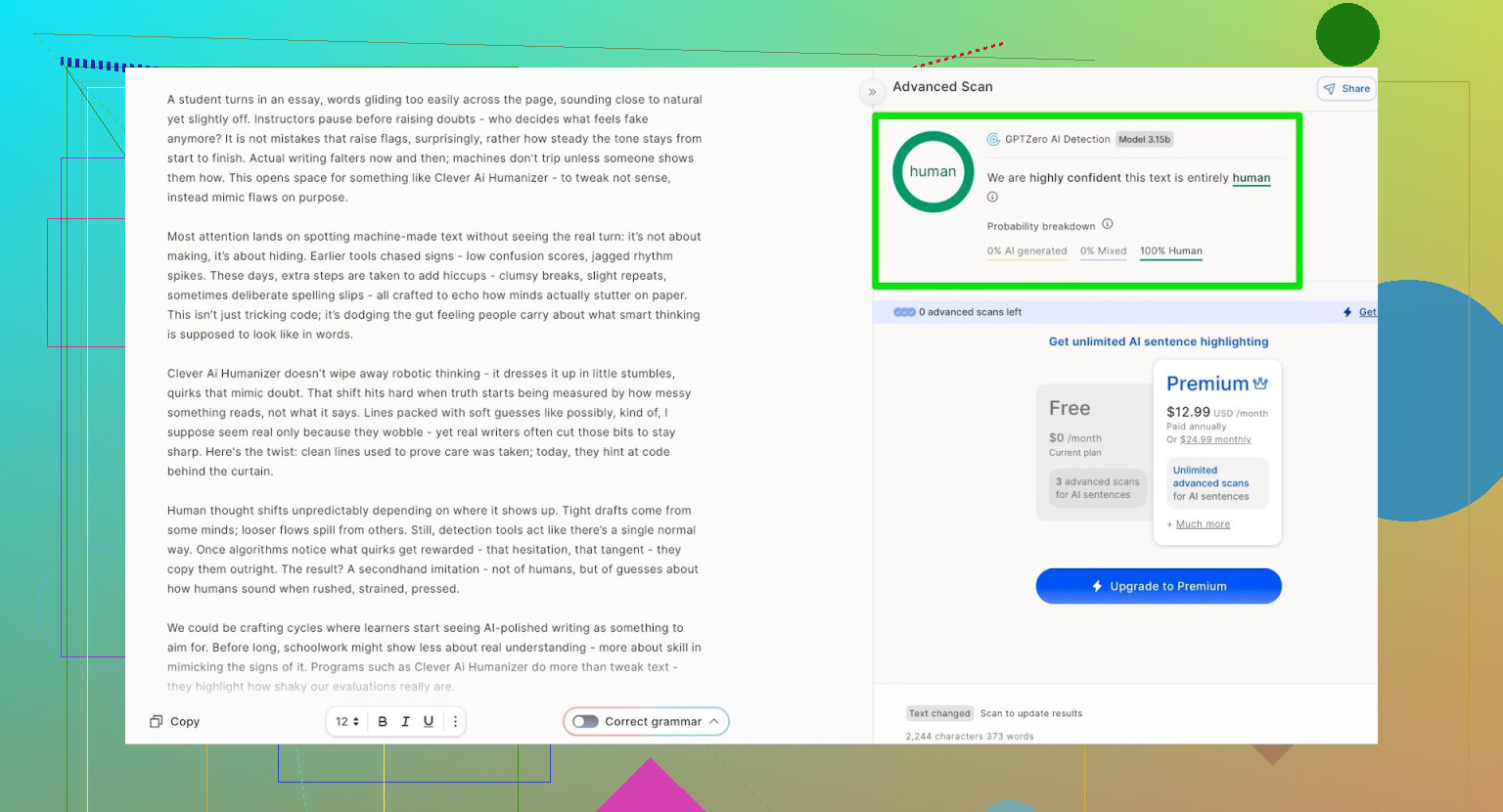
GPTZero:第二个意见,结论基本一样
下一站是 GPTZero。
这个在学校和大学里用得非常多,所以通常是大家最怕的那个。
Clever AI Humanizer(Simple Academic 模式)处理后的文本结果:
- 100% 人类写作
- 0% AI
所以在目前最常用的两款公开检测工具上,这段文本都是满分通关。
但它读起来会不会很烂?
很多 humanizer 翻车的地方在这儿:
它们确实能骗过检测,但读起来像是被丢进翻译软件来回机翻了四遍。
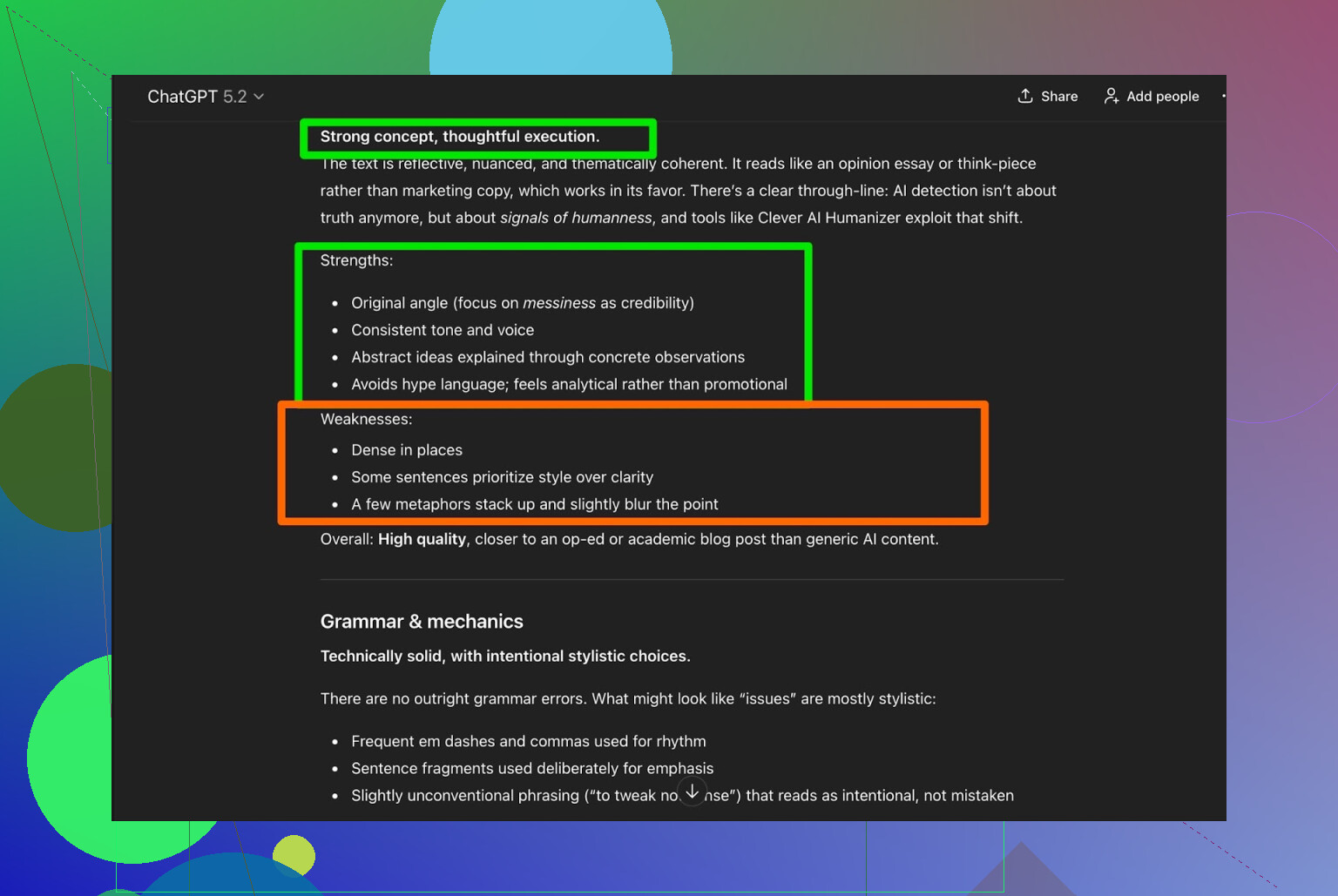
我把 Clever AI Humanizer 的输出交给 ChatGPT 5.2 做分析:

整体评价:
- **语法:**挺扎实
- **风格:**和 Simple Academic 要求基本匹配
- 建议:仍然认为需要人工润色
老实说,我赞同这一点,这就是现实情况:
任何 AI 生成或 AI 人性化的文字,最后都还是值得让人类再过一遍。
如果哪个工具宣称“完全不需要人工编辑”,那多半只是营销话术。
试用 Clever AI Humanizer 内置的 AI 写作功能
它还有一个独立工具:
https://aihumanizer.net/zhai-writer
这里就更有意思了。跟传统流程不同,以前是:
大模型 → 复制 → 丢进 humanizer → 祈祷别翻车
现在你可以:
- 在同一套系统里直接生成并人性化
- 从一开始就由它控制文章结构和风格
这点很关键,因为如果工具自己来生成内容,它就能从根上规避很多特别“AI 味”的写作模式。
我的测试方式:
- 选择 Casual(轻松随意)写作风格
- 主题:AI 人性化,并且要提到 Clever AI Humanizer
- 在提示词里故意塞了一个小错误,看它会不会傻乎乎照抄
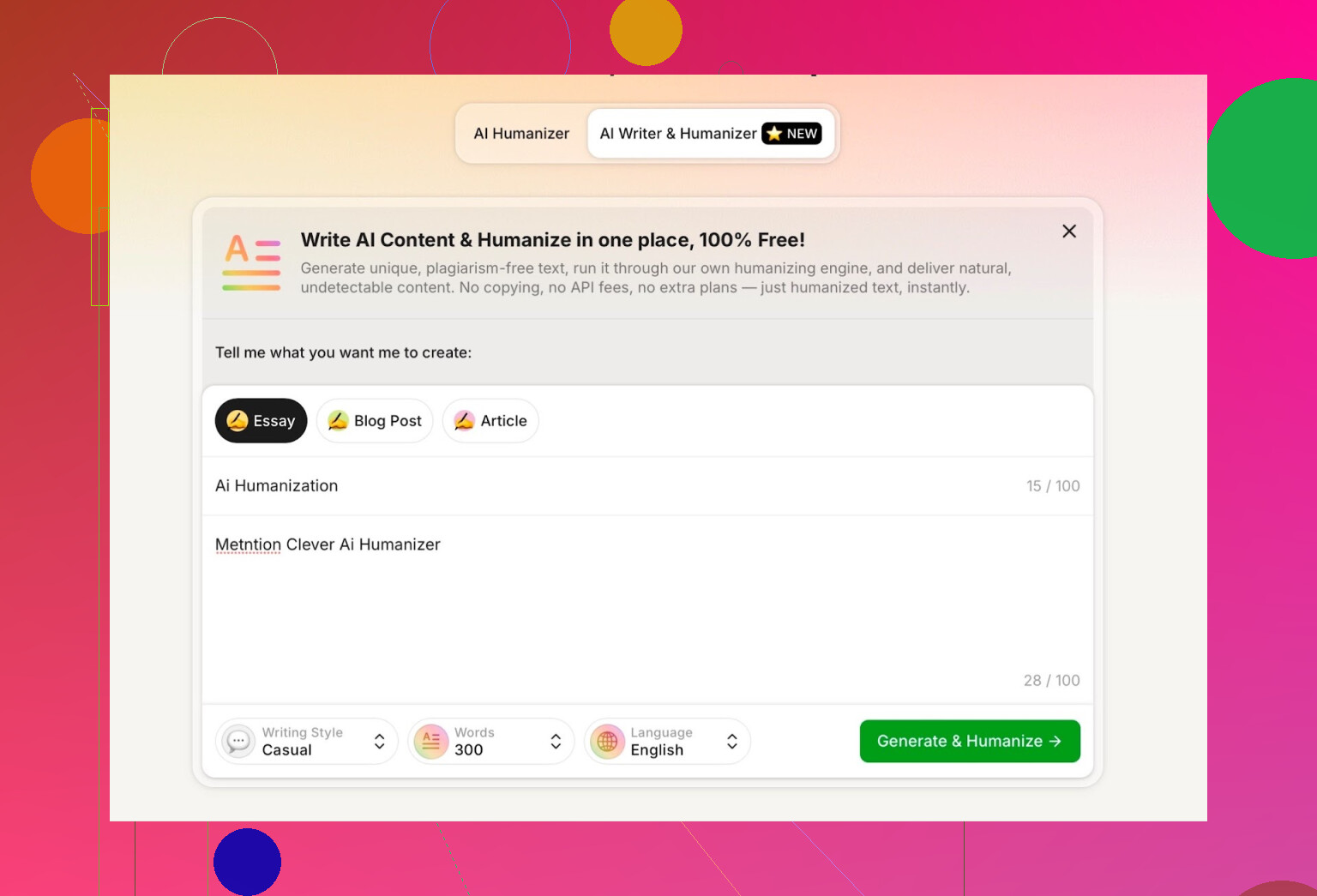
生成结果整体比较干净,口语化自然,也没有怪异地复刻我提示词里的错字。
唯一比较不爽的一点:
- 我要求 300 字
- 它给了我远超 300 的长度
我既然说 300,就希望是 300,而不是 412。要是你有严格字数要求、作业上限或者内容简报,这种偏差会很烦人。
这是我对它的第一个实质性吐槽。
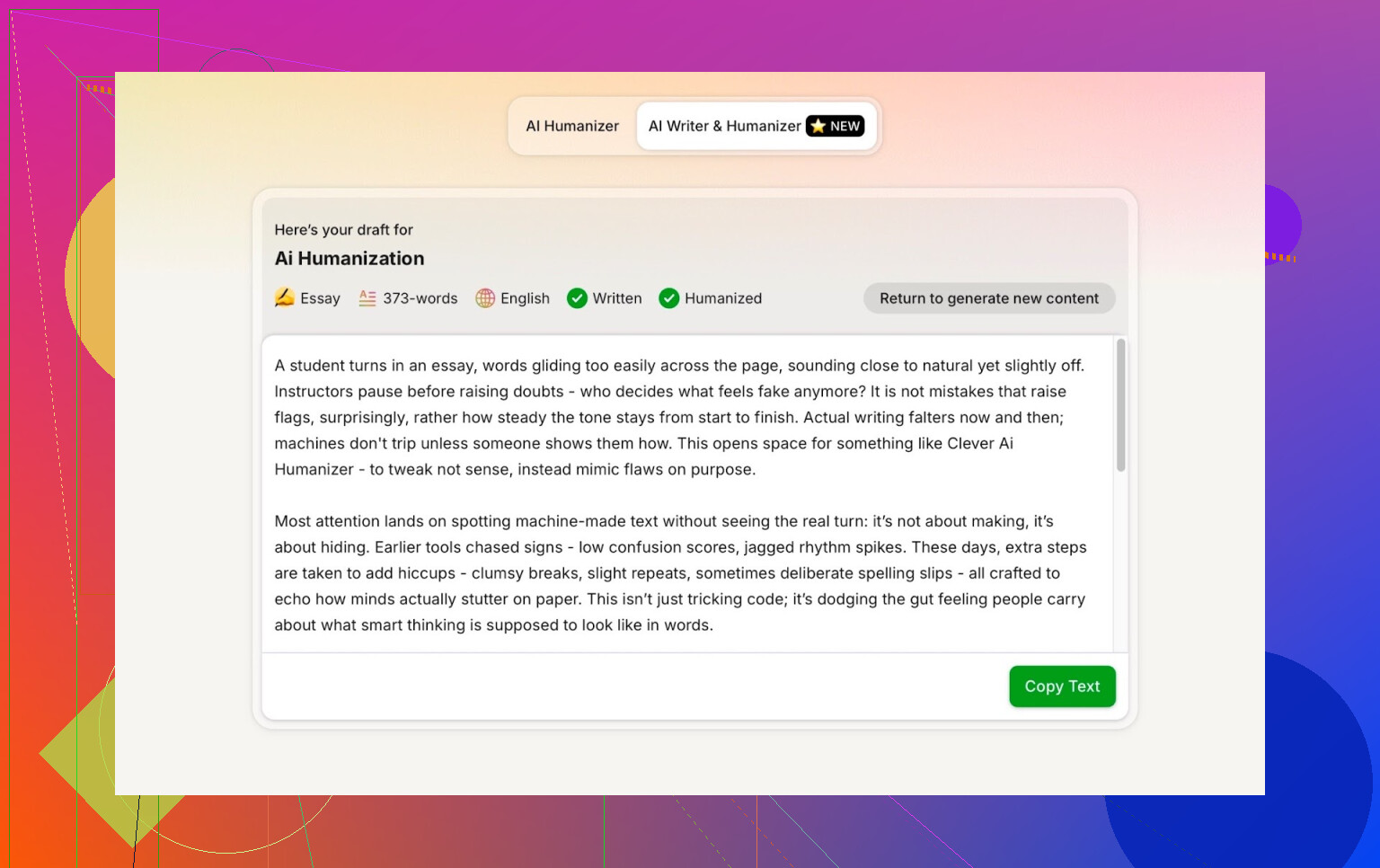
内置 AI Writer 产出的检测结果
我把 AI Writer 生成的文本拿去跑了:
- GPTZero
- ZeroGPT
- QuillBot 检测器(多一个参考)
结果是:
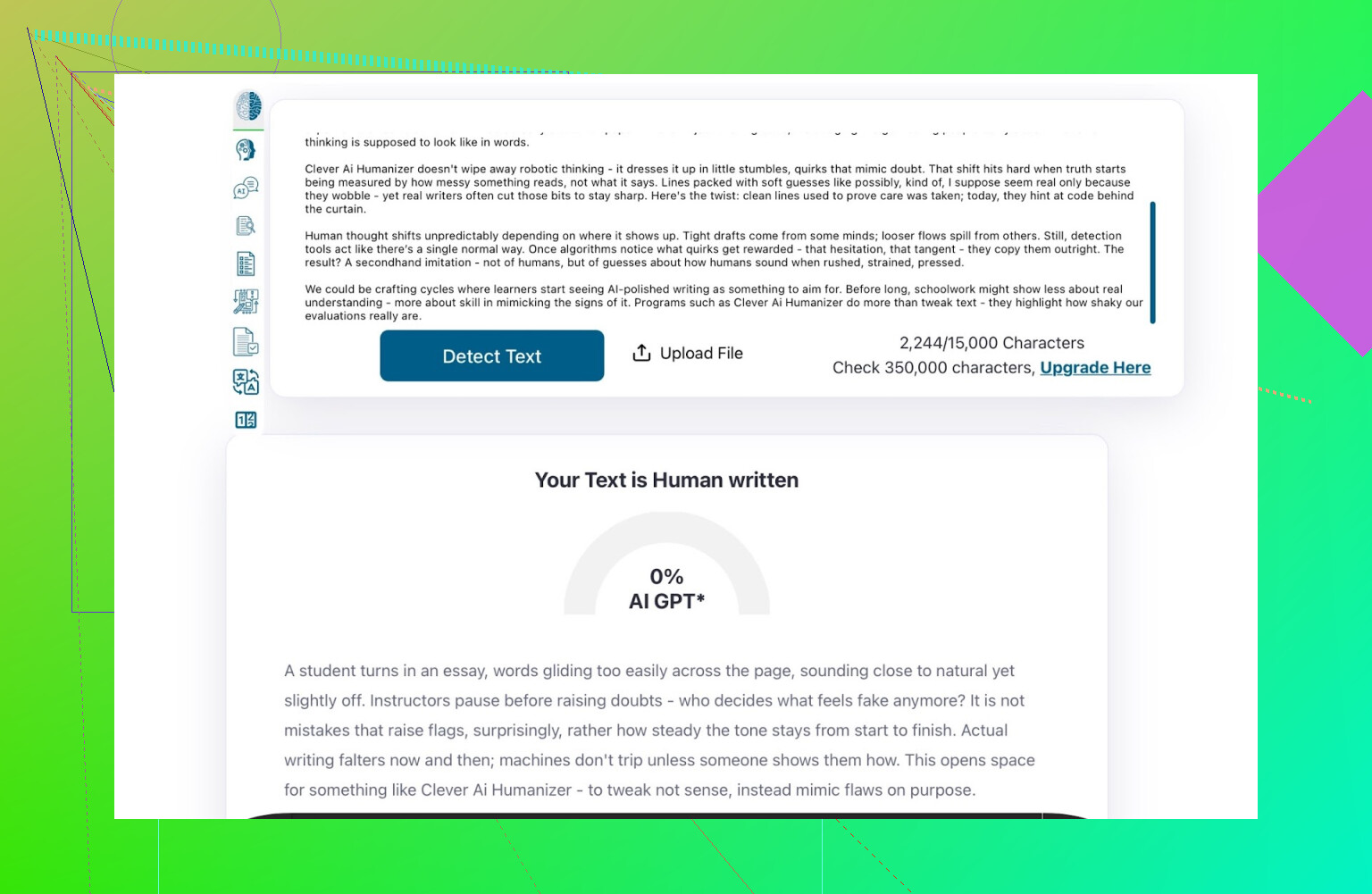
- GPTZero:0% AI
- ZeroGPT:0% AI,100% 人类
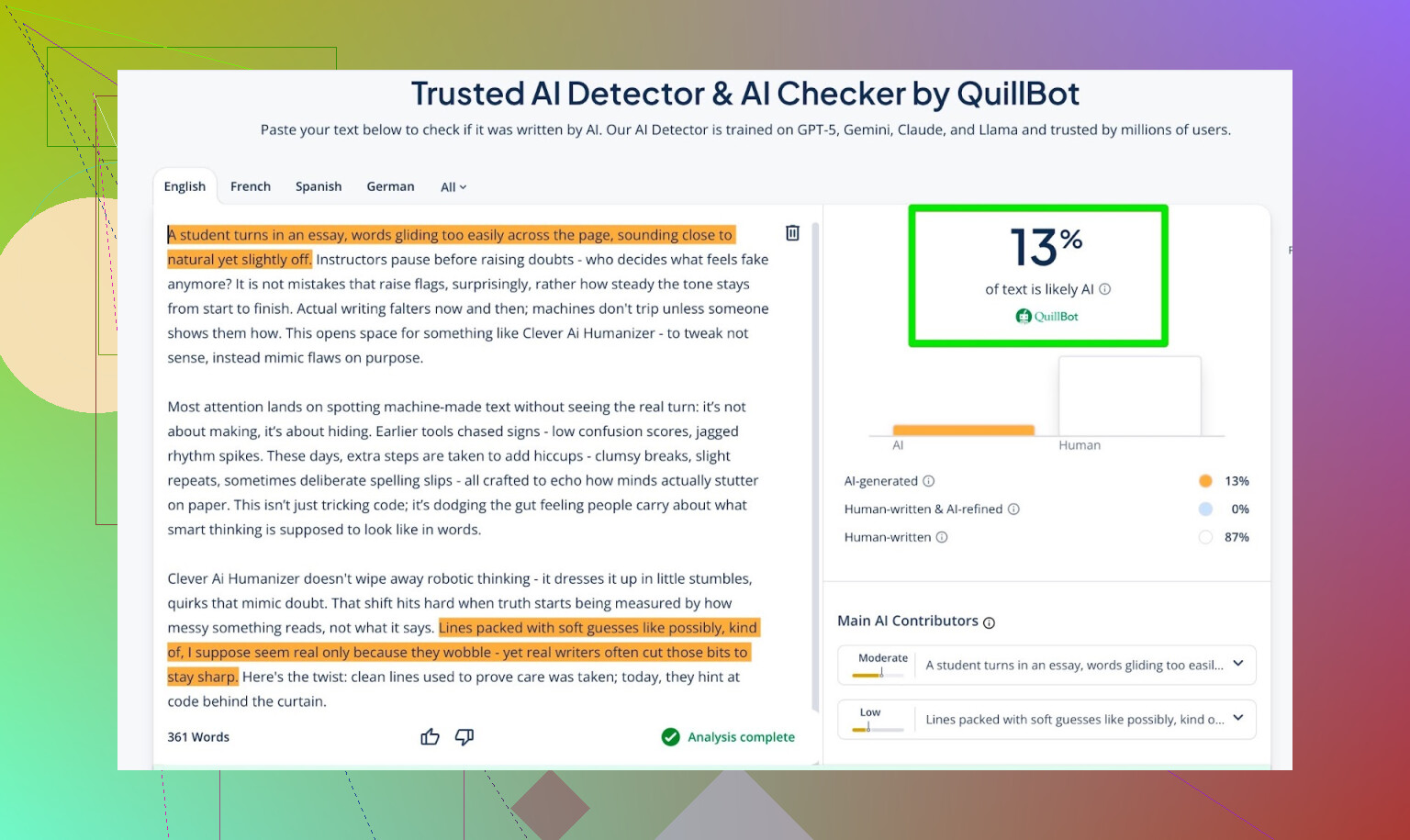
- QuillBot:13% AI
也就是说,QuillBot 觉得里面有一点点“AI 痕迹”,但整体仍然更像人类文本。
总体来看,这成绩算相当不错。
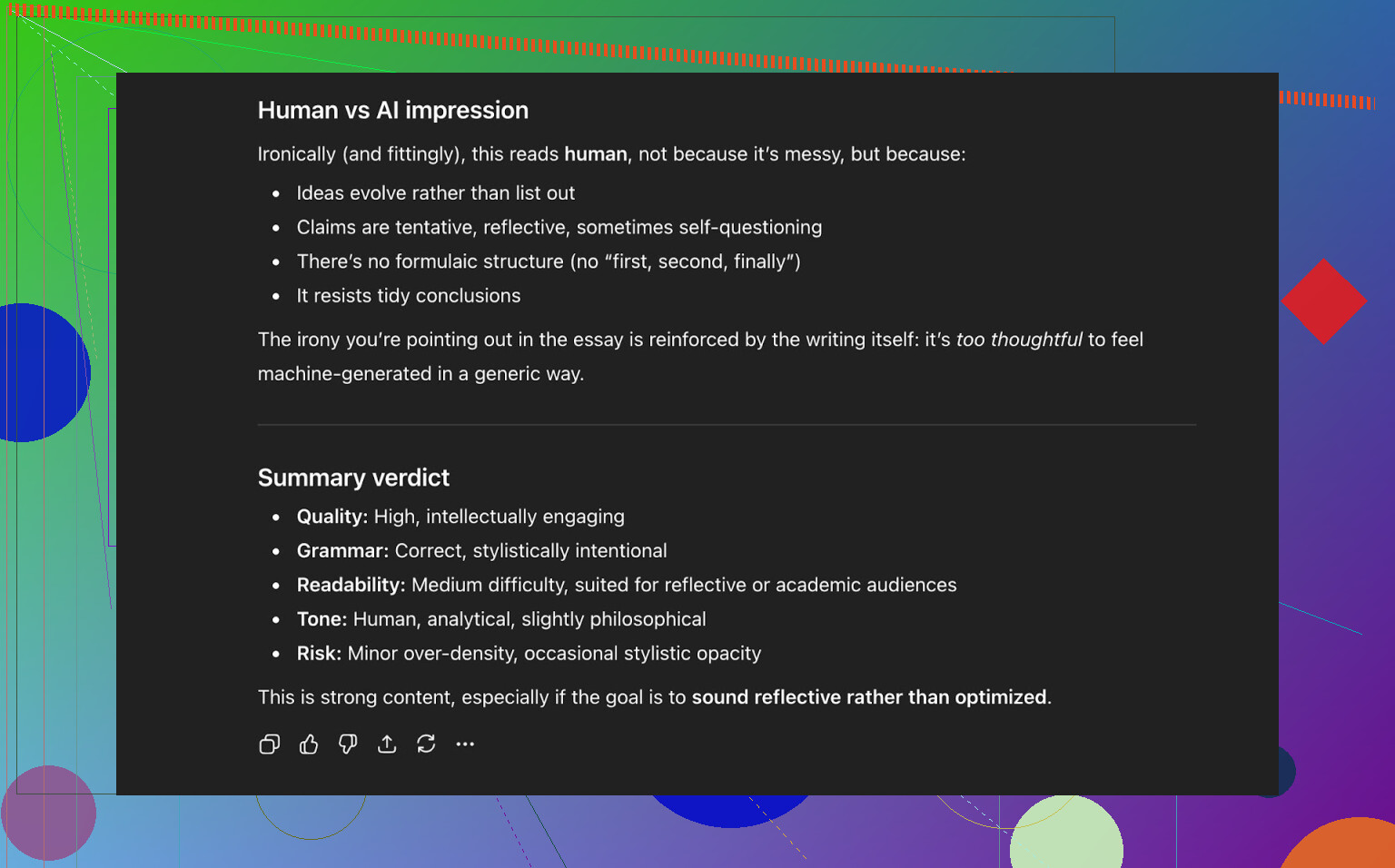
让 ChatGPT 5.2 来判定 AI Writer 的输出
接下来是我更在意的部分:不只是“能不能骗过检测器”,而是:
- 听起来像不像真人?
- 内容是否前后一致?
- 读起来自然不自然?
我把 AI Writer 的文本丢回 ChatGPT 5.2,问它觉得更像人类写的还是 AI 写的。
ChatGPT 5.2 的结论:
- 整体读感偏向人类写作
- 质量评价为较高
- 在语法和结构上没有明显问题
所以此时这段文字:
- 顺利通过了三款公开 AI 检测工具
- 也“骗过”了一款较新的大模型,让它判断为人类作品
和我测试过的其他 humanizer 对比
在我自己的一轮轮测试中,Clever AI Humanizer 的表现确实比很多常被提到的工具要好。
这是我根据当时测试整理的一张简表:
| 工具 | 是否免费 | AI 检测得分 |
| ⭐ Clever AI Humanizer | 是 | 6% |
| Grammarly AI Humanizer | 是 | 88% |
| UnAIMyText | 是 | 84% |
| Ahrefs AI Humanizer | 是 | 90% |
| Humanizer AI Pro | 限免 | 79% |
| Walter Writes AI | 否 | 18% |
| StealthGPT | 否 | 14% |
| Undetectable AI | 否 | 11% |
| WriteHuman AI | 否 | 16% |
| BypassGPT | 限免 | 22% |
在我自己实测里被它压过的工具包括:
- Grammarly AI Humanizer
- UnAIMyText
- Ahrefs AI Humanizer
- Humanizer AI Pro
- Walter Writes AI
- StealthGPT
- Undetectable AI
- WriteHuman AI
- BypassGPT
需要说明的是:这张表对比的是检测器得分,不是“谁读起来更好听”这种主观评价。
Clever AI Humanizer 的短板在哪里?
它并不是魔法棒,也绝对称不上完美。
我碰到的一些问题:
- 字数控制比较随缘
- 你要 300 字,可能给你 280,也可能 370。
- 依然可能出现模式感
- 某些大模型有时还是能抓到局部的 AI 味。
- 内容漂移
- 不总是紧贴原文,有时改写幅度比预期大。
但相对积极的一面是:
- **语法质量:**我个人测试大概能给 8–9/10
- 行文整体比较顺,不会每两行就被奇怪句子绊到
- 不会搞那种刻意注入错别字或小写“i was”来混淆检测器的骚操作
最后这点挺重要。有些工具会故意把错误塞进文章,好像更“像人”,但这虽然可能提高过检概率,却明显拉低文本质量。
比较怪的点:0% AI ≠ 真的“很有人味”
有个比较微妙又难讲清的感受:即使一段内容在多个检测工具里都是 0% AI,你有时候还是能感觉出一种“机器组织”的感觉——比如节奏太工整、信息引入太公式化、结构过于匀称。
Clever AI Humanizer 比大部分同类做得好,但这种底层模式感有时还是会露出来。这也不能完全算它的问题,而是整个技术环境的现状。
本质上,这就是一场猫鼠游戏:
- 检测器变聪明
- Humanizer 跟着进化
- 检测器再更新
- 如此循环
如果你指望有哪款工具是“永不过时、永远安全”,那终究会失望。
那么,它算不算现在最值得用的免费 humanizer?
就我实际用检测器和大模型反复验证过的免费工具里:
- 我会把 Clever AI Humanizer 暂时放在第一梯队。
- 尤其是它同时提供:
- 针对已有文本的人性化处理
- 自带写作并同步人性化的 AI Writer
你仍然需要:
- 自己完整读一遍输出
- 把不对劲的地方改掉
- 调整语气,让它更像你自己的表达方式
但如果你真正想问的是:
“现在这个时间点,Clever AI Humanizer 值得一试吗,尤其是在免费的前提下?”
结合我的测试结论:值得。
如果你想更深挖一点,这里有更多参考
Reddit 上有一些讨论和实测贴,附了更多截图和证据:
-
综合类:多款 AI humanizer 的检测结果对比:
https://www.reddit.com/r/DataRecoveryHelp/comments/1oqwdib/best_ai_humanizer/?tl=zh -
专门针对 Clever AI Humanizer 的测评贴:
https://www.reddit.com/r/DataRecoveryHelp/comments/1ptugsf/clever_ai_humanizer_review/?tl=zh
如果你打算试用 Clever AI Humanizer,我个人会把它定位为:
- 一个辅助工具,而不是替代品
- 能帮你完成大概 70–90% 的初稿工作
- 最终效果仍然取决于最后审稿的那个人
最后站在文字背后的,还是你自己。
简短结论:如果你只是盯着检测器分数,或者去问别的 AI“感觉如何”,是完全拿不到你想要的那种“真实用户的诚实反馈”的。这些只能算是整个故事里的一小块,而且还是最偷懒的那块。
你已经看过 @mikeappsreviewer 做的各种检测器对比和结构化测试了,这些有用,但依然不能告诉你:一个人凌晨一点累到不行、赶论文时用你的工具是什么感受,或者一个内容运营在批量处理 20 篇文章、快要崩溃时,用起来是什么体验。
如果你想要真实世界的信号,可以做这些事:
-
把反馈嵌进使用当下
- 每次运行后:3 次点击就能完成的小调查:
- “听起来: [太像机器人] [比较自然] [非常像真人]”
- “这个输出可以直接提交吗?[可以/不可以]”
- 然后一个很小的可选文本框:“最让你烦的是哪一点?”
- 不要问“你喜欢什么?”,那只会收集一堆假夸奖。要问“哪里很糟”。
- 每次运行后:3 次点击就能完成的小调查:
-
跟踪真实行为,而不只是主观意见
- 重点看这些:
- 用户点“重新生成”的频率
- 用户是不是一生成就立刻在你的编辑器里改(如果你有编辑器)
- 中途流失
- 如果大家每次输入都要重生成 3–4 次,即使问卷反馈看上去不错,你的工具也已经在“用行为告诉你它在失败”。
- 重点看这些:
-
做有针对性的真实用户测试,而不是放给随机流量
抓小而具体的群体,而不是“全网”:- 想要躲过 AI 检测的学生
- 自由撰稿人 / 内容工作室
- 想润色英文、但不是母语者的人
给他们这些: - 一个私密的测试空间
- 一小套固定任务(重写论文开头、润色 LinkedIn 帖子等)
- 每人一场 10–15 分钟的通话或录屏使用 session
用亚马逊礼品卡、免费高级版额度之类的去“贿赂”他们。20 个这类用户给出的定性反馈,远胜过 2000 个匿名点击。
-
把你的工具拿去做 A/B 测试,对比一个基线
不要问“这好不好?”,要问“它比 X 更好吗?”
你可以在背后悄悄跑:- 版本 A:原始大模型输出
- 版本 B:你的人性化处理后的输出
盲测给测试者,然后问: - “哪一段更像真人写的?”
- “哪一段是你真的会拿去提交 / 发布的?”
完全不需要提检测器。
-
刻意找“敌对型”评审
找那些讨厌 AI 内容、或者极度挑剔的编辑。
跟他们说:- “假装这是一个初级写手给你的稿子,尽情挑刺。”
他们在语气、重复、僵硬度、逻辑流畅性上的批注,比“某某检测器显示 0% AI”有用得多。
- “假装这是一个初级写手给你的稿子,尽情挑刺。”
-
公开自用(dogfood),但要诚实
把 Clever AI Humanizer 的输出直接用在:- 产品官网文案
- 更新说明
- 博客文章
然后在底部加一句小字:
“本文由 Clever AI Humanizer 起草,并由人工做了轻度编辑。如果有任何让你觉得不对劲的地方,请告诉我们。”
那些愿意吐槽你的人,给出的会是最直接、最真实的反馈。 -
测试“失败场景”,而不只是“完美场景”
大多数工具在规整、正式的文本上看起来都不错。你真正应该测试的是:- 混乱提示
- 破碎的英语
- 俚语、表情符号、奇怪的排版
- 非常短的内容,比如邮件标题
问用户: - “在哪些情况下它完全搞砸了?”
把这些失败记录并分类。
-
留意“氛围问题”
即便检测器显示 0% AI,很多文本读起来还是有明显“机器形状”:节奏一样、段落整整齐齐、过渡句套路化。
这些是检测器抓不到的。
但你可以这样抓:- 问用户:“这段听起来像是你自己会写的吗?”
- 让他们贴“前后对比”,再问哪一版是他们真的会发给老板或老师的。
-
不要把绕过检测器当成唯一方向
在这里稍微不同意一下 @mikeappsreviewer 那种过度聚焦检测器的视角:用户“以为”自己想要的是“0% AI”,但长期真正能留住他们的是:- 风格和他们自己匹配
- 不胡编乱造
- 不让他们听起来像千篇一律的流水线博主
把用户体验放在第一,绕过检测器放在第二。否则你就被锁在一场注定会输的“猫鼠游戏”里。
-
给自己做一个“残酷诚实的质量仪表盘”
在内部,对每次运行(匿名化)打上这些标签:
- 各种检测器分数
- 你信任的小型人工评审团给的主观评分
- 用户反馈里提到的“烦点”
每个月都去回顾表现最差的那 5–10% 输出。那里面才是真正的金矿。
如果你想要一个可以立刻执行的下一步:
- 在 Clever AI Humanizer 上建一个小型“内测用户”页面。
- 把名额限制在,比如 50 个真实用户。
- 给他们一个清晰的约定:“免费使用,但你必须每周提交 3 个它表现很差或感觉怪怪的示例。”
你并不是真的缺用户,你缺的是“有结构的、刺痛人的反馈”。把这一整套反馈管道搭起来,你在两周内收获到的东西,会远远超过再多 20 张检测器仪表盘截图。
简短结论:检测器截图和让 AI 自己点评输出,都不算“真实用户反馈”,那只是实验室里的测试。你现在做到一半了,但你在问错的人。
下面是几条不只是重复 @mikeappsreviewer 和 @kakeru 已经说过的话:
-
别再问“好不好用”,先问清楚“对谁”好用
你现在有点在追一个通用结论:“我的 AI 人性化工具好不好?”这个问题太虚。实际场景差别非常大:
- 学生想避免被查重或 AI 检测标记
- 内容作者想让初稿不那么像机器人
- 非母语用户想在邮件里听起来更自然
- 市场人员想保持品牌语气
你的反馈问题可能是:你让所有人都能用,却没有针对任何一个具体人群认真听。先选一两个细分人群,把反馈闭环围绕他们来优化。
-
提供有“主见”的预设模式,然后看哪一个被“滥用”
别再用“简单学术”“轻松语气”这种很泛的模式,把它们收紧到真实场景里:
- “大学论文润色”
- “LinkedIn 思想领袖风格”
- “给经理发冷邮件”
- “博客开头优化”
然后:
- 统计哪个预设使用次数最多
- 统计哪个被“全选复制”且几乎不被改动
- 统计哪个用户中途放弃不用了
如果“大学论文润色”使用量很高,但用户跑一轮就退出,你就得到了一条非常具体、可执行的失败信号。这比再多一张检测器截图有用多了。
-
做一个“原始语气 vs 人性化后语气”的对比
这里我和其他人强调“检测器”那一派稍微有点分歧:长期来看,用户更在意的是语气,而不是 0% AI。如果文本不再像他们自己,他们会弃用你的工具,即使它“完全不可检测”。
让用户可以:
- 粘贴原始文本
- 得到人性化结果
- 看到一个简短的差异分析,比如:
- “正式程度:+20%”
- “个人化语气:-30%”
- “句子长度:+15%”
然后直接问:
“这听起来还像是你吗?” [是 / 有点像 / 不太像]
这个问题本身,比“1–5 星打分”能给你更真实的信号。
-
你需要“负向激励”,不只是奖励
大家都在说礼品卡、内测福利之类。问题是:为了继续拿福利,用户会更倾向告诉你你想听的话。
试试这样:
- “如果你发给我们 3 个真正糟糕的输出(截图或粘贴),我们给你解锁 X 额外额度。”
- 你奖励的不是“多用工具”,而是“主动发现工具哪里不好用”。
这样能让注意力集中在你的弱点上,而不是模糊的“挺好用,谢谢”。
-
在内部做一个“黑历史陈列架”
你已经知道这个工具在理想条件下能表现得不错了。你现在缺的是一个经过整理的集合,里面装着:
- 最差的输出
- 最别扭的句子
- 改变了原意的地方
- 把用户写成了“典型 AI 博客腔”的案例
每周拉取:
- 50 个“疯狂连点重新生成”的会话
- 50 个“生成后秒关页面”的会话
手动检查其中 10–20 个,并标记它们糟糕的原因。你要靠这些模式来迭代产品。
-
在漏斗的某一环“主动制造一点摩擦”
你现在大概率在追求“免登录、超快、零阻力”。对流量很好,对反馈很糟。
可以做一个单独的“专业反馈沙盒”:
- 需要邮箱或极简注册
- 提供更高额度或额外模式
- 作为交换,用户需要:
- 每次输出勾选 2 个选项:“自然 / 像机器人”和“在点上 / 跑题了”
- 可选:粘贴场景,比如“我用在 [学校 / 工作 / 社交]”
愿意花 20 秒注册的人,比路过随手用一下的人更有可能给你真正有价值的反馈。
-
在 UI 里直接写明预期
有一个你可能没意识到的假设需要打破:“如果工具足够好,用户应该能一键复制直接用。”现实是,用户对这类工具通常不会这么用。
直接在界面上写类似的话:
“这会帮你完成 70–90%,你必须自己再快速读一遍再提交。”
然后直接问:
- “你最后还改了很多吗?” [稍微改了下 / 改了不少 / 基本重写]
这种问题能给你真实反馈,又不用用户写长问卷。
- “你最后还改了很多吗?” [稍微改了下 / 改了不少 / 基本重写]
-
利用和竞品的对比,但不要很“尬吹自己”
既然大家显然也在试 Grammarly 的 humanizer、Ahrefs、Undetectable 等工具,你不如顺势而为,而不是装作它们不存在。
加一个小勾选框:
- “你用过类似工具吗(比如 Grammarly 或 Ahrefs 的 AI 人性化)?
- 用过,这个更好
- 用过,这个更差
- 差不多
- 没用过别的”
不贬低品牌,不搞“我们是最强”宣传,只要数据。
拿这些信息来理解你的定位,而不只是质量。 - “你用过类似工具吗(比如 Grammarly 或 Ahrefs 的 AI 人性化)?
-
别再假定“检测器过关 = 产品成功”
从 @mikeappsreviewer 提供的内容看,你的 Clever AI Humanizer 在公开检测器面前已经很不错了。很好。但你得问自己:
- “如果明天所有检测器都消失,我这工具还有没有价值?”
如果你诚实的答案是“那就没啥用了”,那你的路线图现在就该更多倾向:
- 个性化
- 语气/风格控制
- 安全性(不胡编、不造假)
- 保留原始意图
这些东西,才是在“检测器军备竞赛”冷却之后,仍然会留下来的价值。
-
把 Clever AI Humanizer 明确定位成“协作工具”
如果你不再把它包装成“隐身斗篷”,你会得到更好的反馈。
比如在界面里写:
“由 AI 起草,经 Clever AI Humanizer 打磨,最终由你定稿。”
这会让用户自然而然去思考:
- “它帮了我什么?”
- “它又在哪些地方拖了后腿?”
然后在这个框架下提问反馈:
- “Clever AI Humanizer 有帮你节省时间吗?”[有 / 没有]
- “它有改变你的原意吗?”[有 / 没有]
同时选中“没省时间”+“改了原意”的那些场景,就是你目前最惨烈的失败区。
如果你想要一个一天之内就能上线的非常实用的动作:
- 每次输出后,给用户 3 个按钮:
- “我可以直接这样发”
- “我会用,但还得改一改”
- “这个没法用”
- 如果他们点最后一个,再追问一个单选问题:
- “太像机器人 / 跑题了 / 语气不对 / 英语太差 / 其他”
这个极小的流程,在规模放大之后,会比你再做一个月检测器实验,或者继续问其它大模型“你被骗到了吗”更能反映 Clever AI Humanizer 的真实使用表现。
从另一个角度做一个简短的分析性拆解,因为其他人已经详细谈了 UX 和测试:
1. 把「真实反馈」当成数据,而不是意见
与其继续做更多检测器实验,不如给 Clever AI Humanizer 接入硬指标:
核心要追踪的数字:
- 完成率:粘贴文本 → humanize → 复制。
- 单次输入的重生次数:重生次数多 = 不满意。
- 复制用时:如果用户在 2–5 秒内复制,他们没在读,只是在刷。
- 编辑意图:点击「复制带格式」vs「复制纯文本」vs「下载」。不同选择通常对应不同使用场景。
这样你能从每一次会话中获得静默反馈,而不是只依赖那少数愿意给你写长文的用户。
2. 轻量的分群标记
别人提到用户画像定向,我会把它做得非常简单粗暴:
首次使用时,在输入框上方放一个一键选择器:
-「用途:学校 / 工作 / 社交 / 其他」
不用登录,无摩擦。只需存一个匿名分群标签。
接下来你就能看到:
- 学校:最高重生率和放弃率
- 工作:停留时间最长,但复制率也高
- 社交:快速复制、文本短,也许不值得重点优化
你不再是凭空猜,究竟是对哪一类用户掉链子。
3. A/B 测「激进 vs 保守」的人性化程度
现在 Clever AI Humanizer 给人的感觉是更偏向检测器规避 + 可读性。这没问题,但不同用户要的改写力度不同。
做一个安静的分流测试:
- 版本 A:改动最小,保留结构,轻度改写
- 版本 B:改写更重,变化更多,节奏差异更大
然后比较:
- 哪个版本更多是「复制然后离开」的行为
- 哪个版本更容易触发「再来一次」的使用
不用问卷,不用求着别人给反馈。行为就是答案。
4. 用优缺点做一次产品现实检视
对比 @kakeru 和 @andarilhonoturno 说的东西,我觉得你的工具已经在「好于平均水平」这一档,但把问题说清楚会更有帮助:
Clever AI Humanizer 的优点
- 在真实内容测试中,对常见 AI 检测器有不错表现。
- 输出整体干净、语法自然,不靠某些工具常用的「故意拼写错误」那套。
- 多种风格(简单学术、轻松等),跟真实写作场景的对应度还不错。
- 集成 AI 写作,一次就能生成并人性化,减少明显的 LLM 指纹。
- 免费且上手轻量,对早期获客和获取大量测试数据很友好。
Clever AI Humanizer 的缺点
- 字数控制比较松散,对有严格字数要求的作业和简报是个真问题。
- 有时改写太激进,会引入内容偏移,而用户未必能察觉。
- 即便检测结果显示 0% AI,有些文本结构和节奏仍然「机器感」明显。
- 以检测器为核心卖点,会把你放进长期的猫鼠游戏里,未来可能吃亏。
- 几乎没有显式的「个人文风」定制,常用用户会觉得自己的文字开始都一个味儿。
5. 别再对检测器过拟合,开始对复访用户过拟合
我在这里和 @mikeappsreviewer 那种强检测器导向的思路有点分歧。检测器截图适合做营销,但作为产品目标很脆弱。
更耐用的信号是:
- 有多少用户在 7 天内回来
- 在回访用户中,会话的字数是否随时间增加(信任信号)
- 同一浏览器 / IP 在不同场景(学校 + 工作等)下使用工具的频率
真实用户留下来并不是因为检测器说「0% AI」,而是因为:
- 它帮他们省了时间。
- 它没有让他们出丑。
- 它没有改变他们真正想说的东西。
先优化复访行为,其次再考虑检测器得分。
6. 打造「信任模式」,而不是「隐身模式」
你的目标不该是打败所有未来的检测器,而是成为这样一个工具:
- 语义保持不被破坏。
- 语气可以调节。
- 限制讲清楚、写明白。
一个细微但有价值的 UI 增加:
- 在输出后展示一个简短、诚实的小总结,比如:
-「含义保留:高」
-「语气变化:中等」
-「句子结构变化:高」
用户开始信任你,是因为你展示了自己的「工作痕迹」。这种信任,比任何问卷都更能带来高质量反馈。
7. 如何在不打扰用户的前提下拿到「质性」反馈
借用基于行为的触发方式:
-
如果用户对同一输入连续重生 3 次以上:
- 显示一个很小的内联提示:
-「没得到你想要的?用 5 个字告诉我们。」[小输入框]
你会收到非常直接的评论,比如「太机械」、「改了我观点」、「太啰嗦」。
- 显示一个很小的内联提示:
-
如果用户在人性化前,在文本框里编辑超过 40 秒:
- 询问:「你是在修 AI 文本,还是在润色自己的写作?」
这样可以判断 Clever AI Humanizer 在他们心目中是「AI 修复器」还是「写作编辑」,这对产品路线很关键。
- 询问:「你是在修 AI 文本,还是在润色自己的写作?」
不需要大弹窗,不需要「给我们 5 星好评」,只要小而合时的提醒。
8. 把竞品放进你的认知框架里
你已经有了来自 @kakeru 之类的好对比,还有 @mikeappsreviewer 那种更偏检测器的评测。把它们当作基准,而不是北极星。
把别人当成:
-「这就是一味追求检测器规避、完全不管写作声音的结果。」
-「这就是只做轻度改写,安全但容易被检测到的结果。」
Clever AI Humanizer 的当下优势,是在可读性和检测之间找平衡。下一步的优势,应当是个性化和控制度,而不是在某个公开检测器上再刷出更低的百分比。
如果要挑一个「这周就能上线」的具体改动,既能提升产品,又能带来真实世界信号:
- 在人性化前加两个开关:
-「尽量保留原有结构」
-「改变结构以增加人类化多样性」
然后记录不同开关组合对应的:
- 更高的复制率
- 更少的重生次数
- 更多的复访会话
你会很快知道,真实用户想要的「人性化」究竟是哪一种,而不是靠检测器图表去猜。