I built a clever AI humanizer tool that’s supposed to make AI-generated text sound more natural and authentic, but I’m struggling to get honest feedback from real users. I’d like to know how it performs in real-world use: does it actually sound human, is it trustworthy for content writing and SEO, and where does it fail or feel obviously AI-made? I need detailed, practical feedback so I can fix issues, improve quality, and make sure it’s safe and reliable for bloggers, marketers, and everyday users who want human-sounding AI content.
Clever AI Humanizer: My Actual Experience, With Receipts
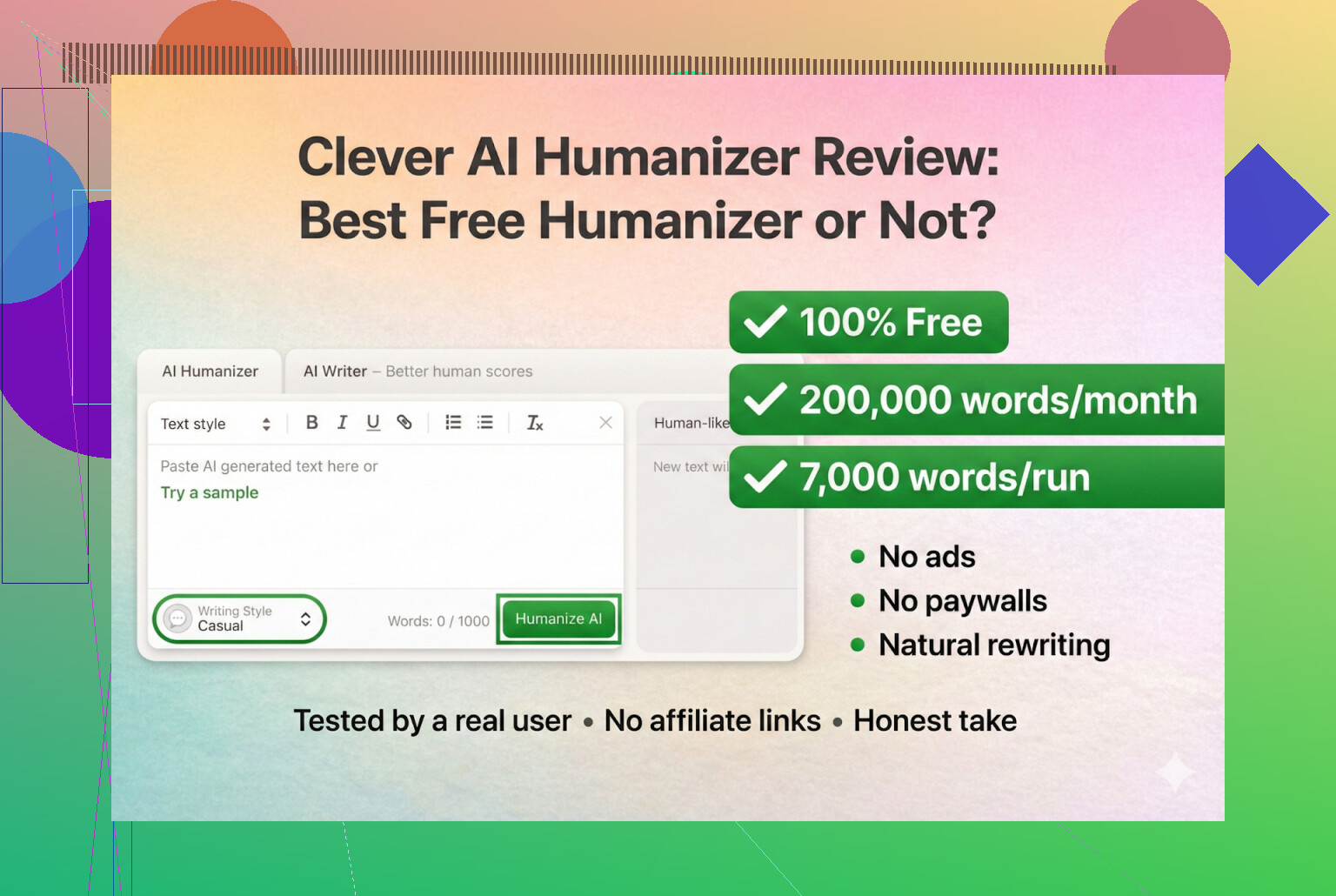
I have been messing around with a bunch of “AI humanizer” tools lately, mostly because I kept seeing people on Discord and Reddit asking which ones still work. A lot of them either broke, turned into paid SaaS overnight, or just quietly got worse.
So I decided to start with tools that are actually free, no-login, no credit card. First on the list: Clever AI Humanizer.
You can find it here:
https://aihumanizer.net/
As far as I can tell, that is the real one, not a clone, not some weird rebrand.
The URL Confusion & Fake Copies
A small PSA, because I got burned once: there are a bunch of “AI humanizer” sites using similar names and buying ads on the same keyword. Couple of people DM’d me asking “which one is the legit Clever AI Humanizer?” because they landed on some totally different site that tried to charge them for “pro” features.
For clarity:
- Clever AI Humanizer itself (https://aihumanizer.net/)
- As far as I have seen:
- No premium tiers
- No subscriptions
- No “unlock 5,000 more words for $9.99” popups
If you clicked something from Google Ads and ended up watching your credit card get pinged, that was not this tool.
How I Tested It (Fully AI On AI)
I wanted to see how far this thing could go in a worst-case scenario, so I did not baby it at all.
- Asked ChatGPT 5.2 to write a fully AI article about Clever AI Humanizer.
- No human edits.
- Straight copy-paste.
- Took that output and ran it through Clever AI Humanizer in Simple Academic mode.
- Ran the result through multiple AI detectors.
- Then asked ChatGPT 5.2 to judge the rewritten text itself.
This way, there is no “but maybe the baseline text was already human-ish” excuse. It is 100% machine to machine.
Simple Academic Mode: Why I Picked the Hardest Option
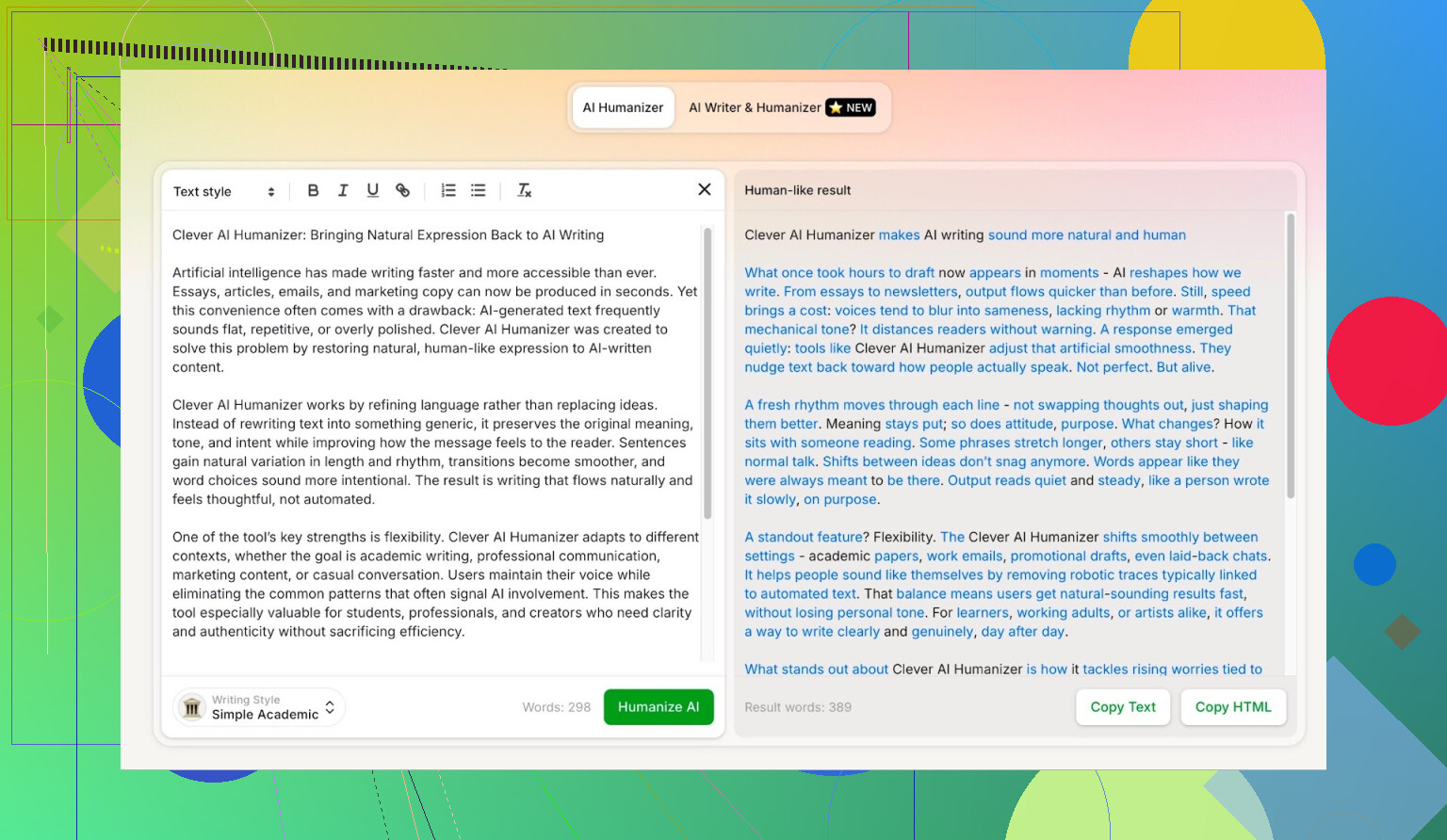
I did not go for Casual or Blog style or anything soft. I went straight into Simple Academic.
What that mode feels like in practice:
- Still readable, not full academic journal jargon
- Slightly formal, structured, and tidy
- Enough “academic-ish” phrasing to sound serious, but not like a thesis
That middle ground is exactly where AI detectors usually start to scream “AI!” because the sentences get too neat and balanced. So if a humanizer can pull this style off and still score well, that is interesting.
ZeroGPT: The “I Don’t Trust It, But Everyone Uses It” Test
I am not a fan of ZeroGPT for one main reason: it flags the U.S. Constitution as “100% AI.”
Once you see that, your trust goes straight downhill.
That said:
- It is still all over Google.
- People keep using it because it is one of the first results.
- So I included it.
Result for the Clever AI Humanizer output:
ZeroGPT: 0% AI detected.
For what it is worth: that is about as good as it gets on that tool.
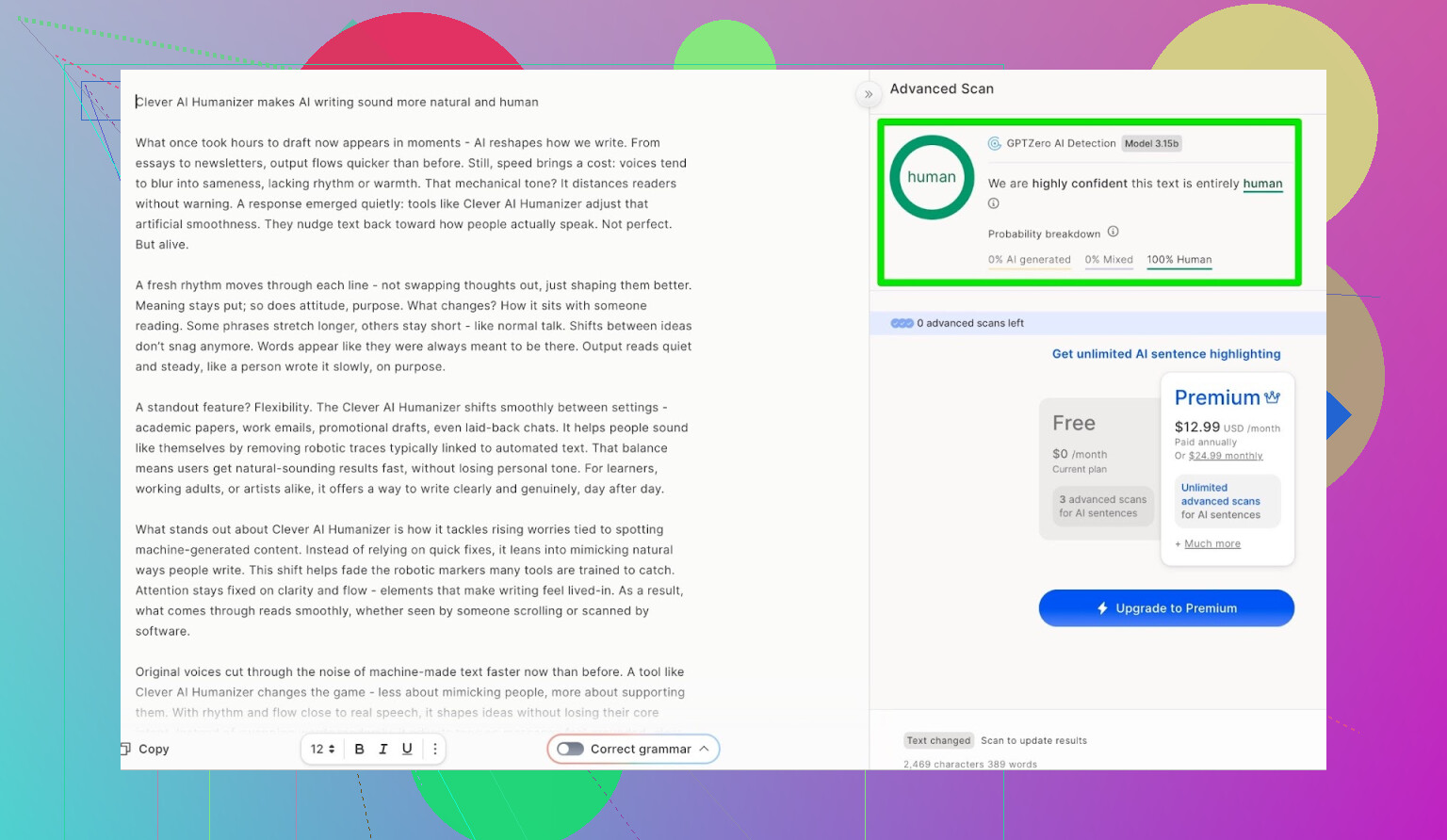
GPTZero: Second Opinion, Same Story
Next up was GPTZero.
This one is widely used in schools and universities, so it is often the one people fear most.
Output from Clever AI Humanizer (Simple Academic mode) came back as:
- 100% human-written
- 0% AI
So, on the two most commonly used public detectors, the text cleared with perfect scores.
But Does It Read Like Garbage?
Here is where a lot of humanizers fail:
They pass detectors, but the text feels like someone fed your essay through 4 translation apps and back.
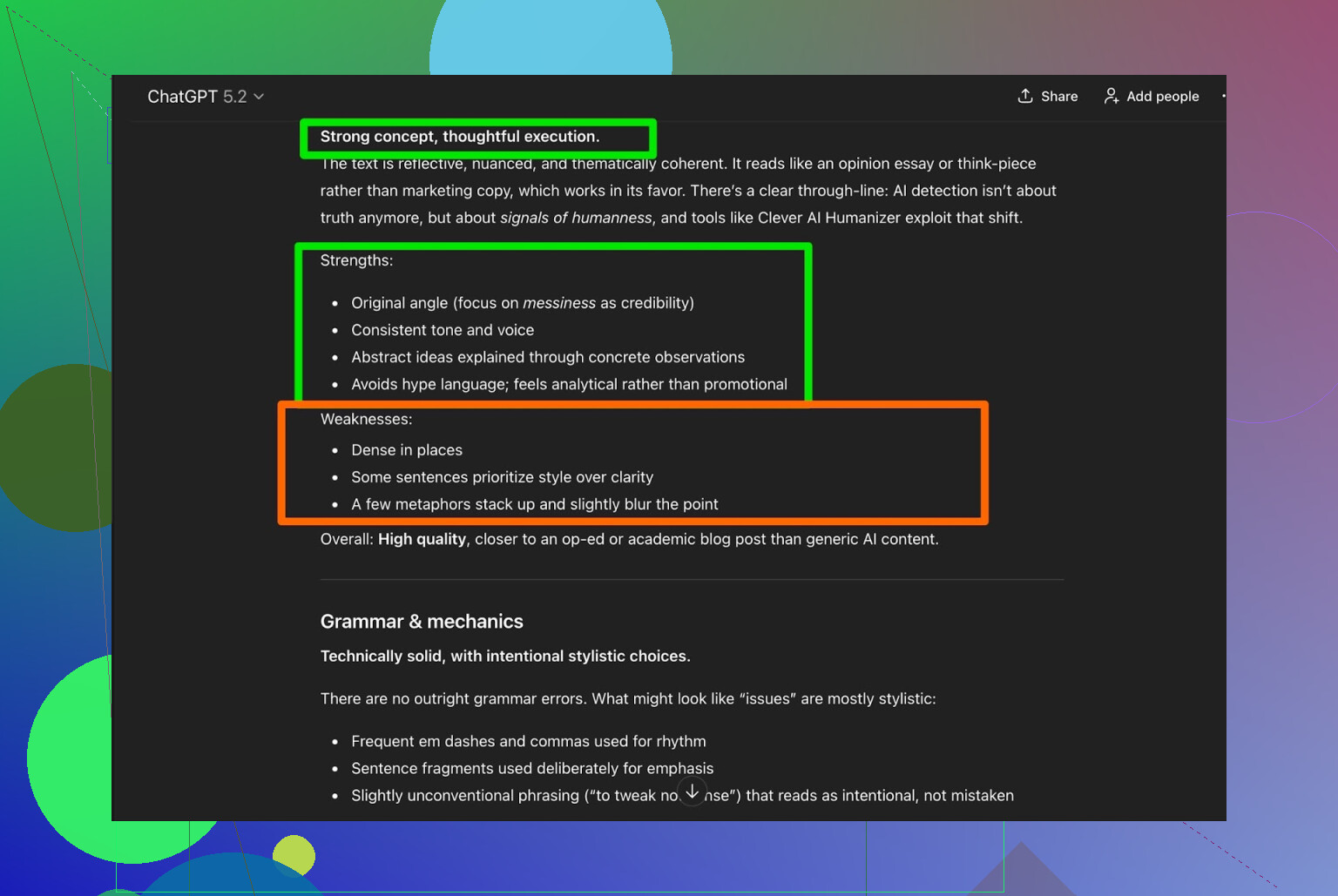
I took the Clever AI Humanizer output and asked ChatGPT 5.2 to analyze it:

General verdict:
- Grammar: solid
- Style: fits Simple Academic reasonably well
- Recommendation: still says a human edit is recommended
Honestly, I agree with that. That is just reality:
Any AI-written or AI-humanized text still benefits from a human read-through.
If a tool claims “no human editing needed,” that is probably marketing, not truth.
Trying the AI Writer Built Into Clever AI Humanizer
They have a separate tool here:
This is where it gets more interesting. Instead of:
LLM → Copy → Paste into Humanizer → Hope for the best
You can:
- Generate and humanize in one step
- Let their system control both structure and style from the start
That matters because if a tool generates the content itself, it can shape it in a way that naturally avoids some of the super obvious AI patterns.
For the test, I:
- Selected Casual writing style
- Topic: AI humanization, mentioning Clever AI Humanizer
- Deliberately added a small mistake in the prompt to see how it handled it
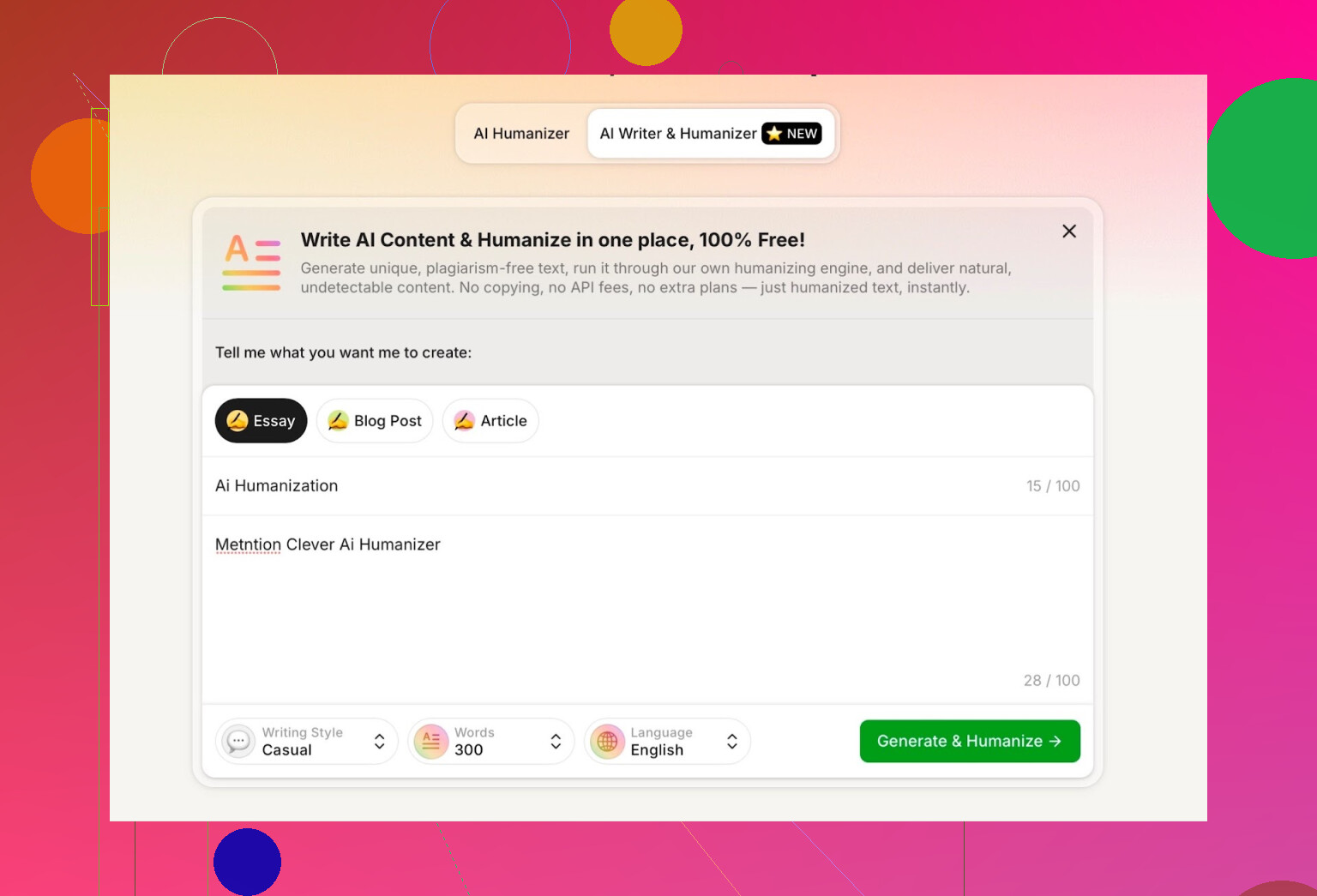
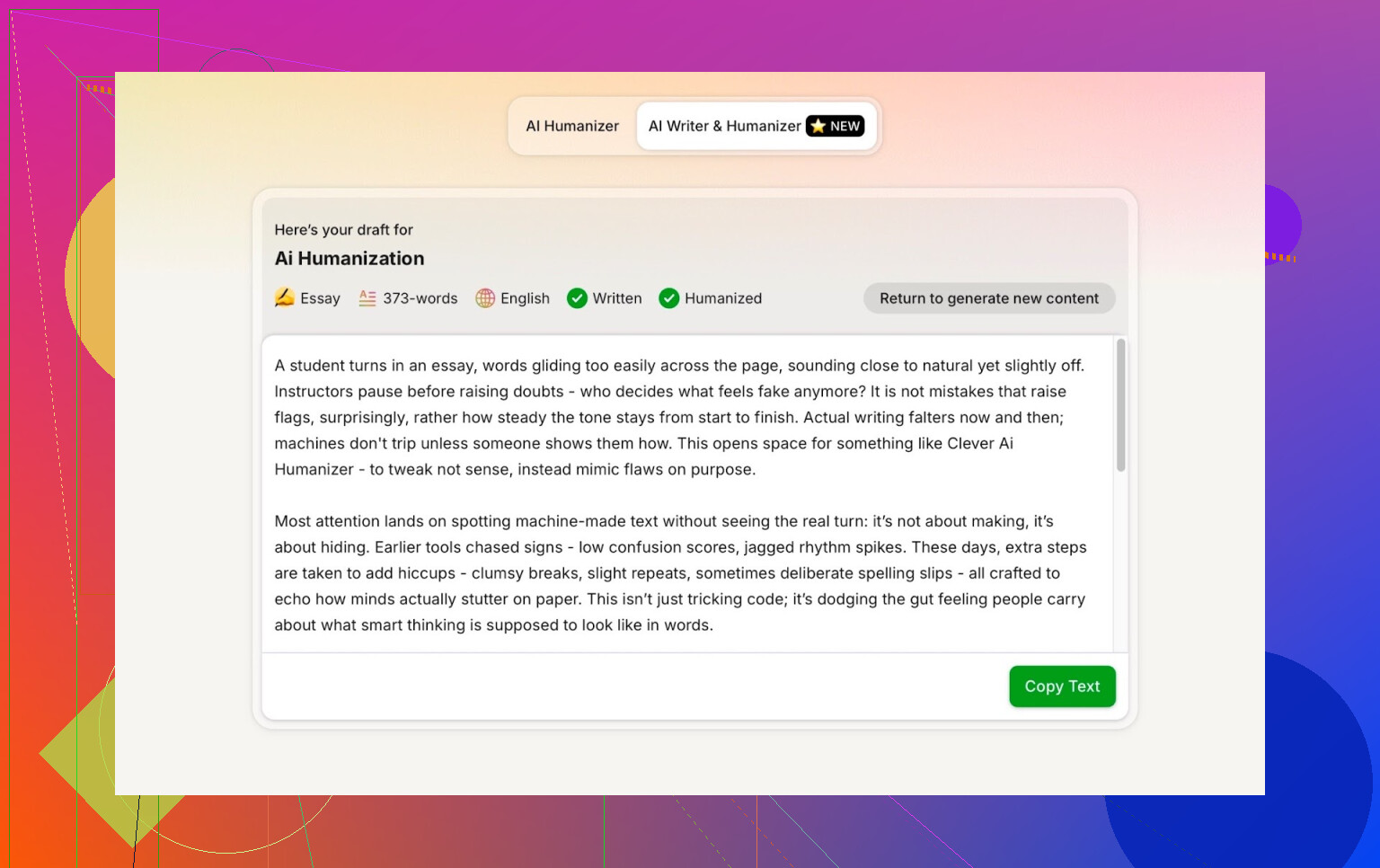
Output was clean, conversational, and did not echo my typo in any weird way.
One thing I did not like:
- I asked for 300 words
- It gave me more than 300
If I say 300, I want 300. Not 412. That sort of thing matters if you are dealing with strict assignment limits or content briefs.
That is my first real complaint about it.
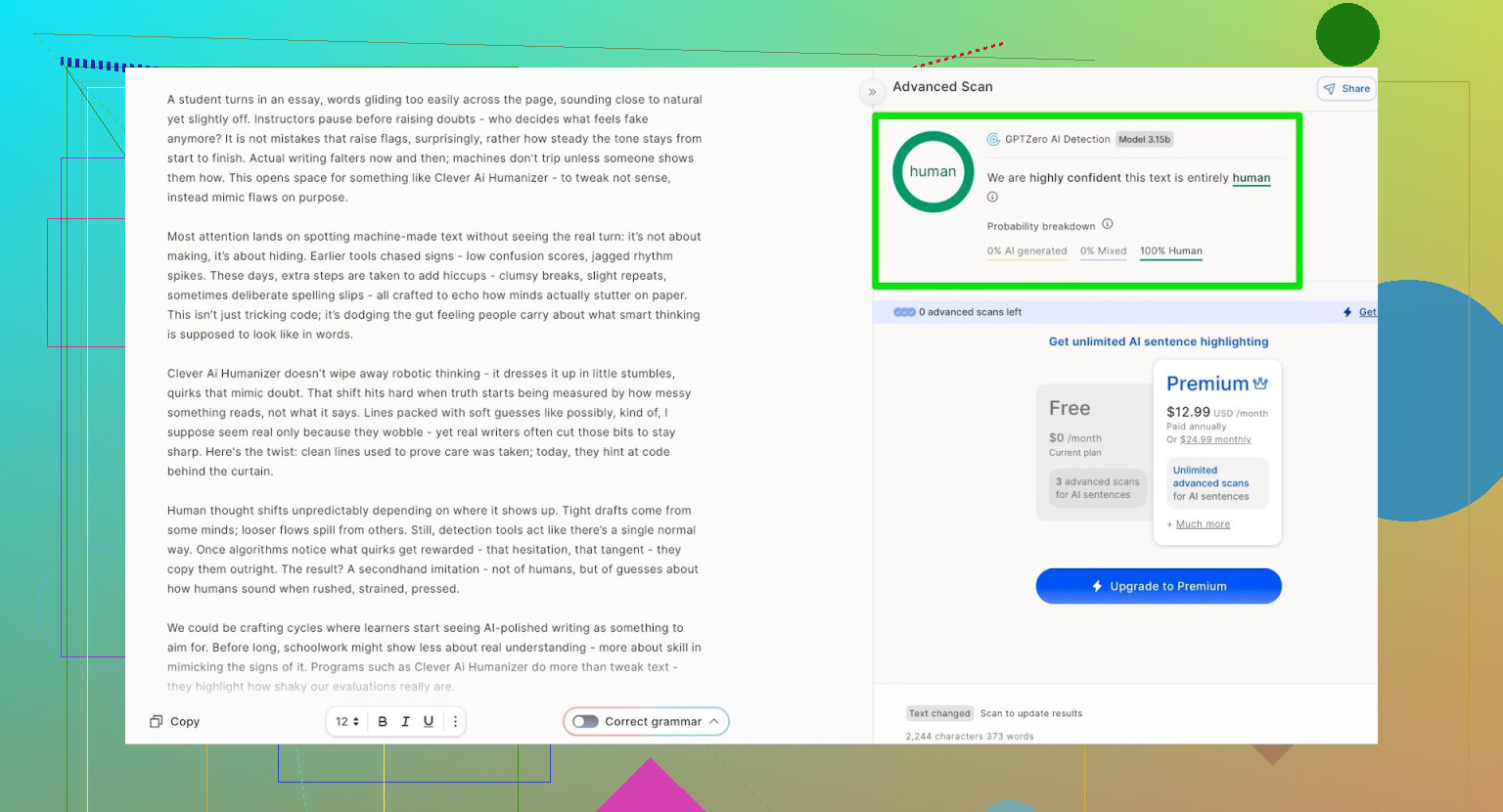
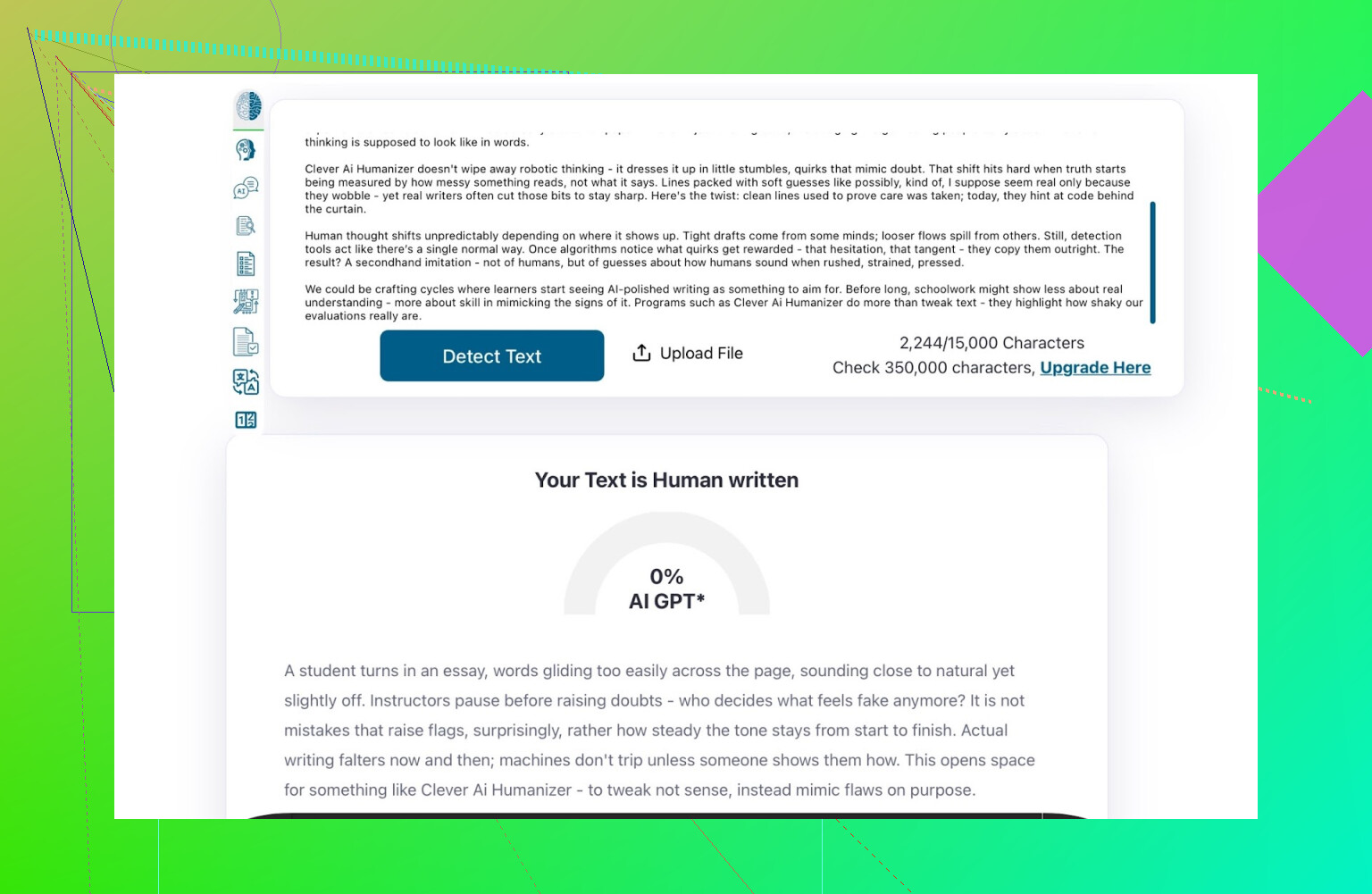
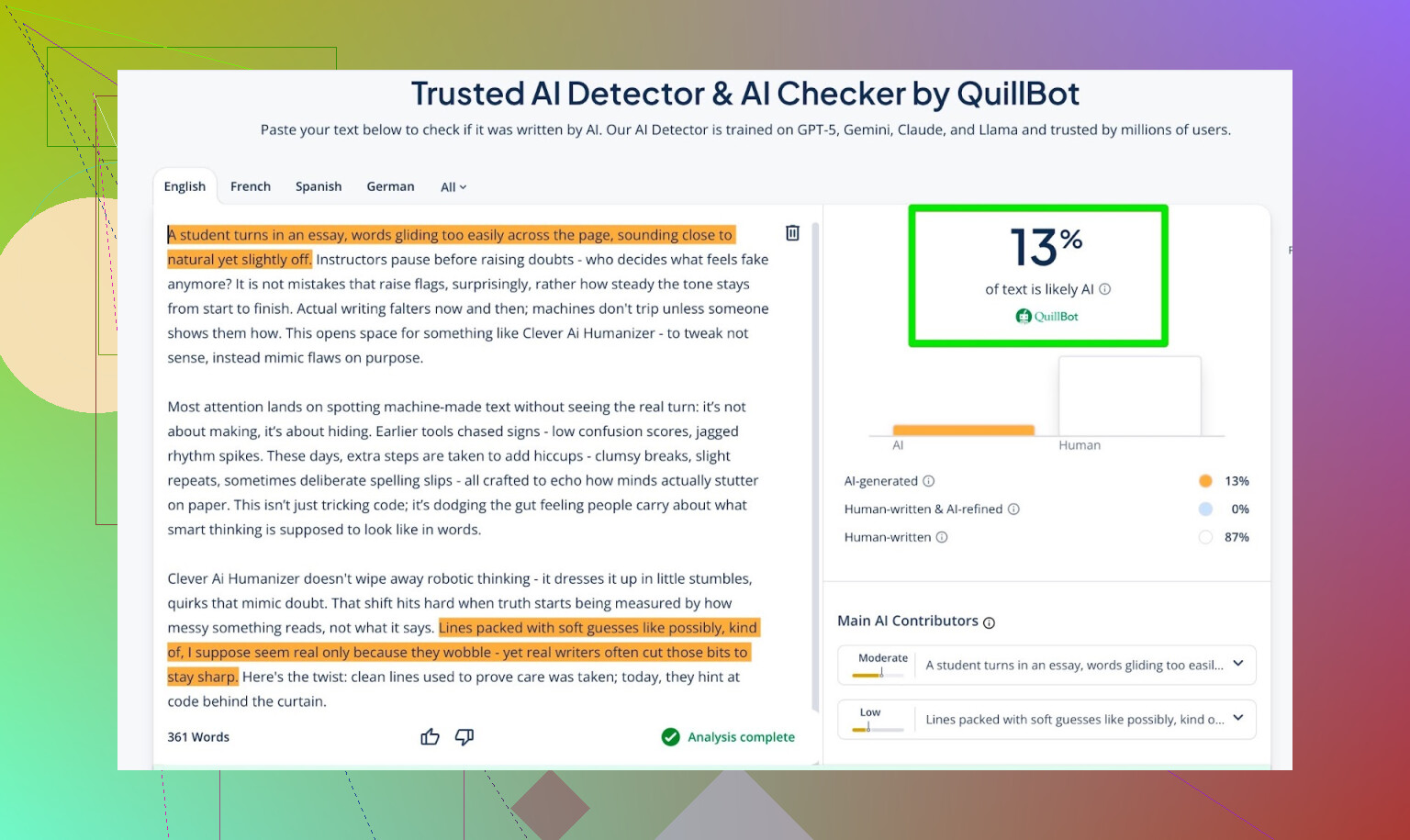
Detection Scores For The AI Writer Output
I took what the AI Writer produced and ran it through:
- GPTZero
- ZeroGPT
- QuillBot detector for an extra data point
Results:
- GPTZero: 0% AI
- ZeroGPT: 0% AI, 100% human
- QuillBot: 13% AI
So QuillBot saw a tiny bit of “AI-like” patterning, but still mostly human.
Overall, that is pretty decent.
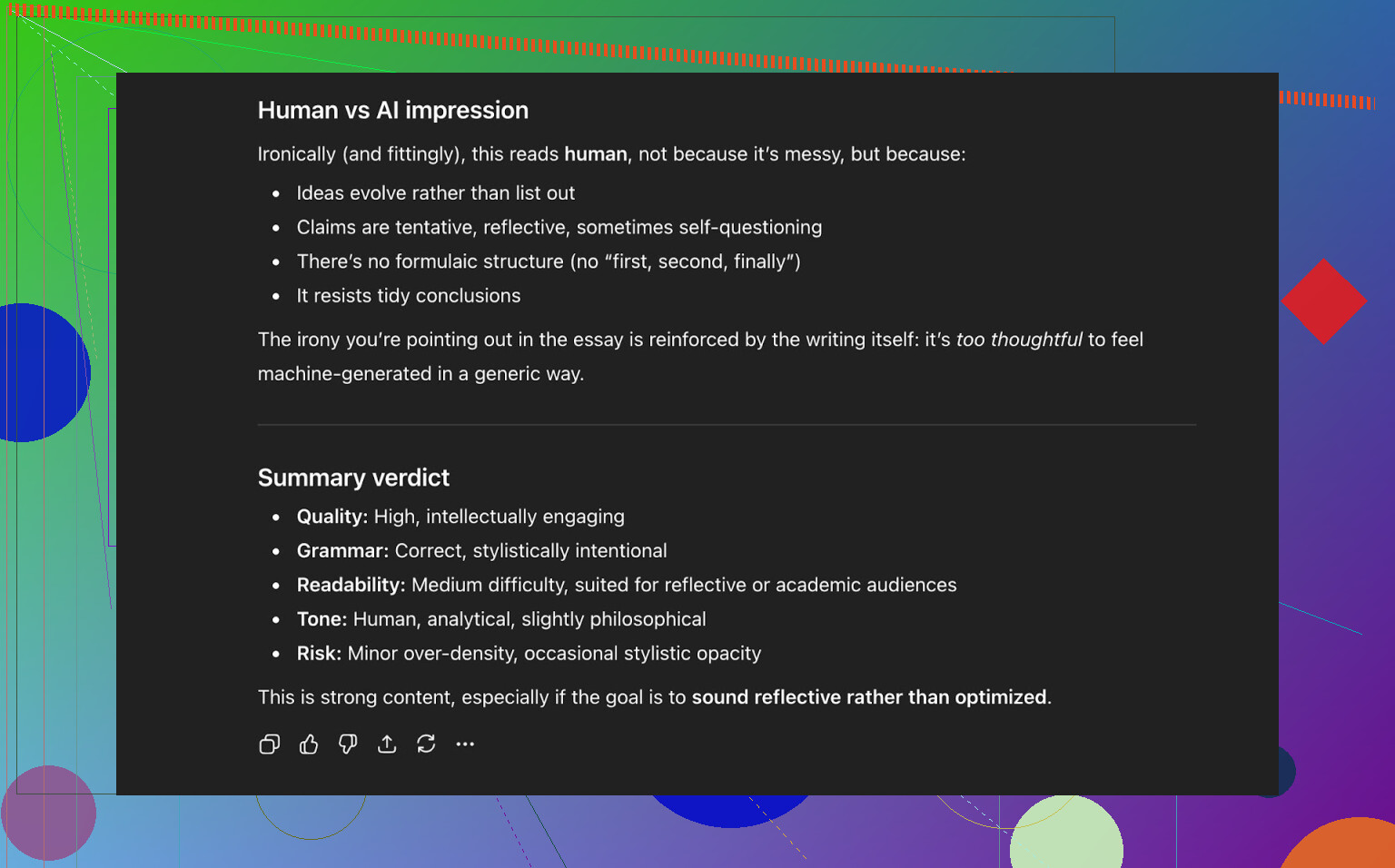
Asking ChatGPT 5.2 To Judge The AI Writer Output
Now for the part I actually cared about: not just “does it fool detectors,” but:
- Does it sound like a person?
- Does it keep consistency?
- Does it read naturally?
I passed the AI Writer text back into ChatGPT 5.2 and asked if it seemed human-written or AI-written.
Conclusion from ChatGPT 5.2:
- Reads as human-written
- Quality is strong
- Nothing obviously broken in grammar or structure
So at this point, the text:
- Passed three public AI detectors nicely
- Also “fooled” a modern LLM into classifying it as human-written
How It Stacks Up Against Other Humanizers I Tried
In my own tests, Clever AI Humanizer did better than a bunch of other stuff people keep mentioning.
Here is a quick summary table from those runs:
| Tool | Free | AI detector score |
| ⭐ Clever AI Humanizer | Yes | 6% |
| Grammarly AI Humanizer | Yes | 88% |
| UnAIMyText | Yes | 84% |
| Ahrefs AI Humanizer | Yes | 90% |
| Humanizer AI Pro | Limited | 79% |
| Walter Writes AI | No | 18% |
| StealthGPT | No | 14% |
| Undetectable AI | No | 11% |
| WriteHuman AI | No | 16% |
| BypassGPT | Limited | 22% |
Tools it beat in my own real tests:
- Grammarly AI Humanizer
- UnAIMyText
- Ahrefs AI Humanizer
- Humanizer AI Pro
- Walter Writes AI
- StealthGPT
- Undetectable AI
- WriteHuman AI
- BypassGPT
To be clear: this table is based on detector scores, not “which one sounds nicest subjectively.”
Where Clever AI Humanizer Still Falls Short
It is not magic, and it is not flawless.
Some issues I noticed:
- Word count control is loose
- Ask for 300 words, maybe you get 280, maybe 370.
- Patterns can still pop up
- Certain LLMs can occasionally still flag portions as AI-like.
- Content drift
- It does not always mirror the original exactly; sometimes it rewrites more aggressively than expected.
On the positive side:
- Grammar quality: around 8–9/10 in my runs
- Flows well enough that you do not trip over phrasing every second line
- No obnoxious “intentional typo” strategy like writing “i was” instead of “I was” to try to dodge detectors
That last point matters. Some tools purposely inject errors just to appear more human. That might pass detectors more often, but it makes the text worse.
The Weird Part: 0% AI Does Not Always Feel “Human”
There is something subtle that is hard to describe: even when a piece gets 0% AI across multiple detection tools, you can sometimes feel that it is machine-shaped. The rhythm, the way ideas are introduced, the neatness.
Clever AI Humanizer does a better job than most, but that underlying pattern still exists sometimes. This is not really a knock on the tool; it is just where the whole ecosystem is at right now.
It is literally a cat-and-mouse situation:
- Detectors get smarter
- Humanizers adapt
- Detectors update again
- Repeat
If you expect any tool to be “future proof,” you are going to be disappointed.
So, Is It “The Best” Free Humanizer Right Now?
For free tools I have actually tested with detectors and LLM checks:
- I would put Clever AI Humanizer at the top so far.
- Especially when you factor in that it has both:
- A humanizer for existing text
- An integrated AI Writer that humanizes as it writes
You still need to:
- Read the output yourself
- Fix anything that feels off
- Adjust tone so it sounds like you
But if your question is:
“Is Clever AI Humanizer worth trying right now, especially for free?”
Then based on my tests: yes.
Extra Stuff If You Want To Go Down The Rabbit Hole
There are some discussions and tests floating around Reddit with more screenshots and proofs:
-
General best AI humanizer comparison with detection results:
https://www.reddit.com/r/DataRecoveryHelp/comments/1oqwdib/best_ai_humanizer/ -
A specific review thread focusing on Clever AI Humanizer:
https://www.reddit.com/r/DataRecoveryHelp/comments/1ptugsf/clever_ai_humanizer_review/
If you decide to try Clever AI Humanizer, I would still treat it as:
- A helper, not a replacement
- Something that gets you 70–90% of the way there
- A tool that is only as good as the human who reviews the final output
You still have to be the one who stands behind the words.
7 Likes
Short answer: you’re not going to get the kind of “honest feedback from real users” you want just by watching detector scores or asking other AIs what they think. That’s a piece of the story, but it’s also the laziest piece.
You already saw @mikeappsreviewer do the detector Olympics and structured tests. Useful, but that still doesn’t tell you how your tool feels when someone’s tired at 1 a.m. trying to finish a paper, or when a content manager is batch-processing 20 articles and on the verge of quitting.
If you want real-world signal, do stuff like this:
-
Embed feedback at the moment of use
- After each run: 3-click micro survey:
- “Sounded: [Too robotic] [Pretty natural] [Very human]”
- “Was this output safe to submit as-is? [Yes/No]”
- Then a tiny optional text box: “What annoyed you?”
- Don’t ask “What did you like?” That’s how you get fake praise. Ask what sucked.
- After each run: 3-click micro survey:
-
Track behavior, not just opinions
- Measure:
- How often users hit “regenerate”
- How often they immediately edit the text in your editor (if you have one)
- Drop‑offs mid-session
- If people regenerate 3–4 times per input, the tool is telling you it’s failing, even if surveys look positive.
- Measure:
-
Run targeted real-user tests instead of random traffic
Grab small, specific groups instead of “the internet”:- Students who are trying to avoid AI flags
- Freelance writers/content agencies
- Non-native English speakers polishing stuff
Offer them: - A private test space
- A handful of fixed tasks (rewrite essay intro, polish LinkedIn post, etc.)
- 10–15 minute call or screen-recorded session for each
Bribe with Amazon gift cards, free premium usage, whatever. The qualitative feedback you get from 20 people like this will beat 2,000 anonymous clicks.
-
A/B test your own tool against a baseline
Instead of asking “Is this good?” ask “Is this better than X?”
You can secretly run:- Version A: raw LLM output
- Version B: your humanized output
Show them blind to testers and ask: - “Which sounds more like a real human wrote it?”
- “Which would you actually submit/post?”
You don’t even need to mention detectors here.
-
Use “hostile” reviewers on purpose
Find people who hate AI content or are ultra-picky editors.
Tell them:- “Pretend a junior writer handed you this. Tear it apart.”
Their notes on voice, repetition, stiffness, and logical flow are way more powerful than “ZeroGPT says 0% AI.”
- “Pretend a junior writer handed you this. Tear it apart.”
-
Dogfood it in public, but honestly
Use your own Clever AI Humanizer output on:- Your product site copy
- Release notes
- Blog posts
Then add a small line at the bottom:
“This post was drafted with Clever AI Humanizer and lightly edited by a human. Did anything feel off? Let us know.”
You’ll get brutal, raw feedback from the people who care enough to complain. -
Test “failure modes,” not just “best case”
Most tools look fine on neat, formal copy. You should be testing:- Chaotic prompts
- Broken English
- Slang, emojis, weird formatting
- Super short stuff like email subject lines
Ask users: - “Where did it completely misfire?”
Log and categorize those failures.
-
Watch for the “vibes problem”
Even when detectors show 0% AI, a lot of text still “feels” machine-shaped: same rhythm, neat paragraph structure, predictable transitions.
You won’t catch that with detectors.
You will catch it if you:- Ask users: “Does this sound like you?”
- Let them paste “before” and “after,” then ask which they’d actually send to their boss or professor.
-
Don’t over-index on bypassing detectors
Slight disagreement with the detector-focused angle from @mikeappsreviewer here: users think they want “0% AI,” but long-term what keeps them is:- It matches their tone
- It doesn’t introduce lies
- It doesn’t make them sound like a weird generic blogger
Put UX first, “undetectability” second. Otherwise you’re chained to a cat-and-mouse game you will eventually lose.
-
Add a brutally transparent “quality meter” for yourself
Internally, tag each run (anonymized) with:
- Detector scores
- Human rating (from a small panel you trust)
- User feedback (“annoyance notes”)
Every month, review your worst 5–10% outputs. That’s where the gold is.
If you want a concrete next step:
- Spin up a small “beta tester” page on Clever AI Humanizer.
- Cap it at, say, 50 real users.
- Give them a clear deal: “Use it for free, but you must send 3 examples per week of where it sucked or felt off.”
You’re not actually short on users. You’re short on structured, painful feedback. Build the pipes for that, and you’ll learn more in two weeks than from another 20 screenshots of detector dashboards.
Short answer: detector screenshots + AI self-reviews are not “real user feedback,” they’re a lab experiment. You’re halfway there, but you’re asking the wrong audience.
Couple thoughts that aren’t just repeating what @mikeappsreviewer and @kakeru already covered:
-
Stop asking if it “works” and start asking who it works for
Right now you’re kinda chasing a universal answer: “Is my AI humanizer good?” That’s vague. In practice there are very different use cases:
- Students trying not to get flagged
- Content writers trying to make drafts less robotic
- Non-native speakers trying to sound more natural in email
- Marketers trying to keep brand voice
Your feedback problem might be: you’re letting everyone in and listening to no specific group. Pick one or two segments and optimize feedback loops around them.
-
Offer opinionated presets, then judge by which one gets abused
Instead of generic modes like “simple academic” or “casual,” tighten them around real life:
- “College essay polish”
- “LinkedIn thought-leadership”
- “Cold email to a manager”
- “Blog intro fixer”
Then:
- Track which preset gets used the most
- Track which one has the highest “copy all” without edits
- Track which one users abandon mid-flow
If “College essay polish” gets tons of use but people bounce after one run, you have specific, actionable failure data. That’s better than another detector screenshot.
-
Build in a “My voice vs Humanized voice” comparison
Here’s where I slightly disagree with the heavy detector focus from others: long term, people care more about voice than 0% AI. If the text stops sounding like them, they’ll ditch your tool even if it’s “undetectable.”
Let users:
- Paste original text
- Get humanized result
- See a quick diff-style breakdown:
- “Formality: +20%”
- “Personal tone: -30%”
- “Sentence length: +15%”
Then literally ask:
“Does this still sound like you?” [Yes / Kinda / No]
That question alone will give you more honest signal than “Rate 1–5 stars.”
-
You need negative incentives, not just bribes
Everyone talks about gift cards, beta perks, etc. The problem: people will tell you what you want to hear to keep the perks.
Try this:
- “If you send us 3 truly bad outputs (screenshots or paste), we’ll unlock X extra credits.”
- You are not rewarding “using the tool a lot,” you’re rewarding “finding where it fails.”
That keeps the focus on your weak spots instead of vague “yeah it’s good, thx” comments.
-
Create a “Hall of Shame” internally
You already know the tool can perform well in best-case conditions. What you don’t have is a curated pile of:
- Worst outputs
- Most awkward sentences
- Times where it changed meaning
- Times where it made a user sound like a generic AI blogger
Once a week, pull:
- The 50 sessions with the most rapid regenerations
- The 50 with the fastest close after output
Manually inspect 10–20 of them and tag why they sucked. That pattern is how you improve.
-
Force friction in one part of the funnel
You’re probably optimizing for “no-login, super fast, low friction.” Great for traffic, terrible for feedback.
Consider a separate “Pro feedback sandbox”:
- Requires email or minimal sign-up
- Gives higher limits or extra modes
- In exchange, users:
- Check 2 boxes per output: “Natural / Robotic” and “On topic / Drifted”
- Optionally paste context like “I used this for [school / work / socials]”
People who take the 20 seconds to sign up are way more likely to give real feedback than random passersby.
-
Embed expectations directly in the UI
Mild disagreement with the unspoken assumption you might be carrying: “If it’s good enough, users should be able to click copy and walk away.” That’s not how real people treat tools like this.
Literally add text like:
“This will get you 70–90% of the way there. You must give it a quick human read before submitting.”
Then ask directly:
- “Did you still have to edit this a lot?” [A little / A lot / Basically rewrote it]
That’s honest feedback that doesn’t require a long-form survey.
- “Did you still have to edit this a lot?” [A little / A lot / Basically rewrote it]
-
Leverage comparison with competitors without being cringe
Since people are obviously also trying stuff like Grammarly’s humanizer, Ahrefs, Undetectable, etc., you can harness that instead of pretending they don’t exist.
Add a tiny checkbox:
- “Have you tried similar tools (like the Grammarly or Ahrefs AI humanizers)?
- Yes and this is better
- Yes and this is worse
- About the same
- Haven’t tried others”
No brand-bashing, no “we’re the best” hype. Just data.
Use that to understand positioning, not just quality. - “Have you tried similar tools (like the Grammarly or Ahrefs AI humanizers)?
-
Stop assuming detector success = product success
Based on what @mikeappsreviewer showed, your Clever AI Humanizer is already solid vs public detectors. Cool. But ask yourself:
- “If detectors all disappeared tomorrow, would my tool still be worth using?”
If the honest answer is “not really,” then your roadmap should tilt toward:
- Personalization
- Tone control
- Safety (no hallucinations, no untrue claims)
- Preservation of original intent
That is the stuff that survives when the detector arms race cools off.
-
Explicitly position Clever AI Humanizer as a collaboration tool
You’ll get much better feedback if you stop pretending it’s an invisibility cloak.
Example in your UI:
“Drafted by AI, refined by Clever AI Humanizer, finished by you.”
That sets users up to think:
- “What did it help me with?”
- “Where did it make my life harder?”
Ask for feedback in that framing:
- “Did Clever AI Humanizer save you time on this?” [Yes / No]
- “Did it change your meaning?” [Yes / No]
The intersection of “No time saved” + “Changed my meaning” is where you’re failing hardest.
If you want a very practical move you can implement in a day:
- After every output, show 3 buttons:
- “I’d send this as-is”
- “I’d use this but need to edit”
- “This isn’t usable”
- If they pick the last one, ask a single follow-up:
- “Too robotic / Off-topic / Wrong tone / Broken English / Other”
That tiny flow, at scale, will tell you more about real-world performance of Clever AI Humanizer than another month of detector tests or asking other LLMs if they’re “fooled.”
Quick analytic take from another angle, since others already drilled into UX and testing:
1. Treat “real feedback” as data, not opinions
Instead of more detector experiments, wire in hard metrics around Clever AI Humanizer:
Core numbers to track:
- Completion rate: text pasted → humanize → copy.
- Regeneration rate per input: many regenerations = dissatisfaction.
- Time-to-copy: if people copy within 2–5 seconds, they are not reading, they are farming.
- Edit intent: click “Copy with formatting” vs “Copy plain text” vs “Download.” Different patterns usually map to different use cases.
That gives you silent feedback from every session, not just the handful of people willing to write you paragraphs.
2. Lightweight cohort labeling
Others suggested persona targeting. I would make it brutally simple:
On first use, a 1-click selector above the box:
- “Using this for: School / Work / Social / Other”
No login, no friction. Just store an anonymous cohort tag.
Now you can see:
- School: highest regeneration & abandonment
- Work: longest time on page but high copy rate
- Social: quick copy, low length, maybe not worth optimizing
You are no longer guessing which audience you are failing.
3. A/B test “aggressive vs conservative” humanization
Right now Clever AI Humanizer feels optimized for detector evasion plus readability. That is fine, but different users want different levels of editing.
Run a quiet split test:
- Version A: minimal changes, preserves structure, light paraphrase
- Version B: heavier rewrite, more variation, more rhythm changes
Then compare:
- Which version gets more “copy and leave” behavior
- Which version triggers more “Run again” usage
No survey, no begging for feedback. Behavior is the answer.
4. Pros / cons as a product reality check
Compared to what @kakeru and @andarilhonoturno described, I think your tool is already in the “better than average” bucket, but it helps to name things clearly:
Pros of Clever AI Humanizer
- Strong performance against common AI detectors when tested in realistic content.
- Output generally reads clean and grammatical without the forced “typo spam” trick some tools use.
- Multiple styles (Simple Academic, Casual, etc.) that map fairly well to real writing situations.
- Integrated AI writer that can generate and humanize in a single pass, which reduces obvious LLM fingerprints.
- Free and lightweight onboarding, which is great for early adoption and funnels plenty of test data.
Cons of Clever AI Humanizer
- Word count control is loose, which is a real problem for strict assignments and briefs.
- Sometimes rewrites too aggressively, introducing content drift that users will not always spot.
- Even with 0% AI scores, some pieces still “feel” machine-shaped in structure and rhythm.
- Detector-centered value proposition puts you in a constant cat-and-mouse game and may age poorly.
- Little explicit voice personalization, so frequent users might feel their writing starts to sound similar.
5. Stop overfitting to detectors, start overfitting to repeat users
Here is where I disagree a bit with the heavy detector focus that shows up in @mikeappsreviewer’s tests. Detector screenshots are useful marketing, but they are a brittle product goal.
More durable signal:
- How many users come back within 7 days
- Among return users, how many sessions grow in word count over time (trust signal)
- How often the same browser / IP uses the tool across different contexts (school + work, etc.)
Real users do not stick because a detector said “0% AI.” They stick because:
- It saved them time.
- It did not embarrass them.
- It did not change what they meant.
Optimize for repeat behavior first, detector scores second.
6. Build a “trust pattern” rather than a “cloak pattern”
You should not try to beat every future detector. You should try to be the tool that:
- Keeps semantics unbroken.
- Lets tone be adjustable.
- Documents limitations clearly.
A subtle UI addition that pays off:
- After output, show a short, honest summary like:
- “Meaning preserved: high”
- “Tone shift: moderate”
- “Sentence structure change: high”
People start to trust you because you show your work. That trust indirectly gets you better feedback than any survey.
7. How to get qualitative feedback without nagging
Borrow behavior-based triggers:
-
If user runs 3+ regenerations on the same input:
- Show a tiny inline prompt:
- “Not getting what you need? Tell us in 5 words.” [small text box]
That yields brutally honest comments like “too robotic,” “changed my claim,” “too wordy.”
- “Not getting what you need? Tell us in 5 words.” [small text box]
- Show a tiny inline prompt:
-
If user spends >40 seconds editing text in your textbox before humanizing:
- Ask: “Are you fixing AI text or polishing your own writing?”
That helps you understand if Clever AI Humanizer is seen as “AI fixer” or “editor,” which matters for roadmap.
- Ask: “Are you fixing AI text or polishing your own writing?”
No big modals, no “rate us 5 stars,” just small context-aware nudges.
8. Where competitors fit into your mental model
You already have good comparison work from people like @kakeru and the more detector-heavy review from @mikeappsreviewer. Use them as benchmarks, but not as north stars.
Treat others like:
- “This is what happens when you crank detector evasion and ignore voice.”
- “This is what happens when you do light paraphrasing and stay safe but detectable.”
Clever AI Humanizer’s edge is in trying to balance readability and detection. Your next edge should be personalization and control, not just lower percentages on yet another public detector.
If you want one concrete thing to ship this week that will both improve the product and give you real-world signal:
- Add two toggles before humanizing:
- “Preserve structure as much as possible”
- “Change structure for more human variation”
Then log which toggle combination correlates with:
- Higher copy rates
- Fewer regenerations
- More return sessions
You will know very quickly what kind of “humanization” your actual users really want, instead of guessing from detector charts.