Ik heb een slimme AI-humanizer tool gebouwd die AI-gegenereerde tekst natuurlijker en authentieker moet laten klinken, maar ik heb moeite om eerlijke feedback van echte gebruikers te krijgen. Ik wil weten hoe hij presteert in echt gebruik: klinkt de tekst daadwerkelijk menselijk, is hij betrouwbaar voor contentcreatie en SEO, en waar gaat het mis of voelt het duidelijk door AI gemaakt aan? Ik heb gedetailleerde, praktische feedback nodig zodat ik problemen kan oplossen, de kwaliteit kan verbeteren en ervoor kan zorgen dat de tool veilig en betrouwbaar is voor bloggers, marketeers en gewone gebruikers die mensklinkende AI-content willen.
Clever AI Humanizer: mijn echte ervaring, met bewijs
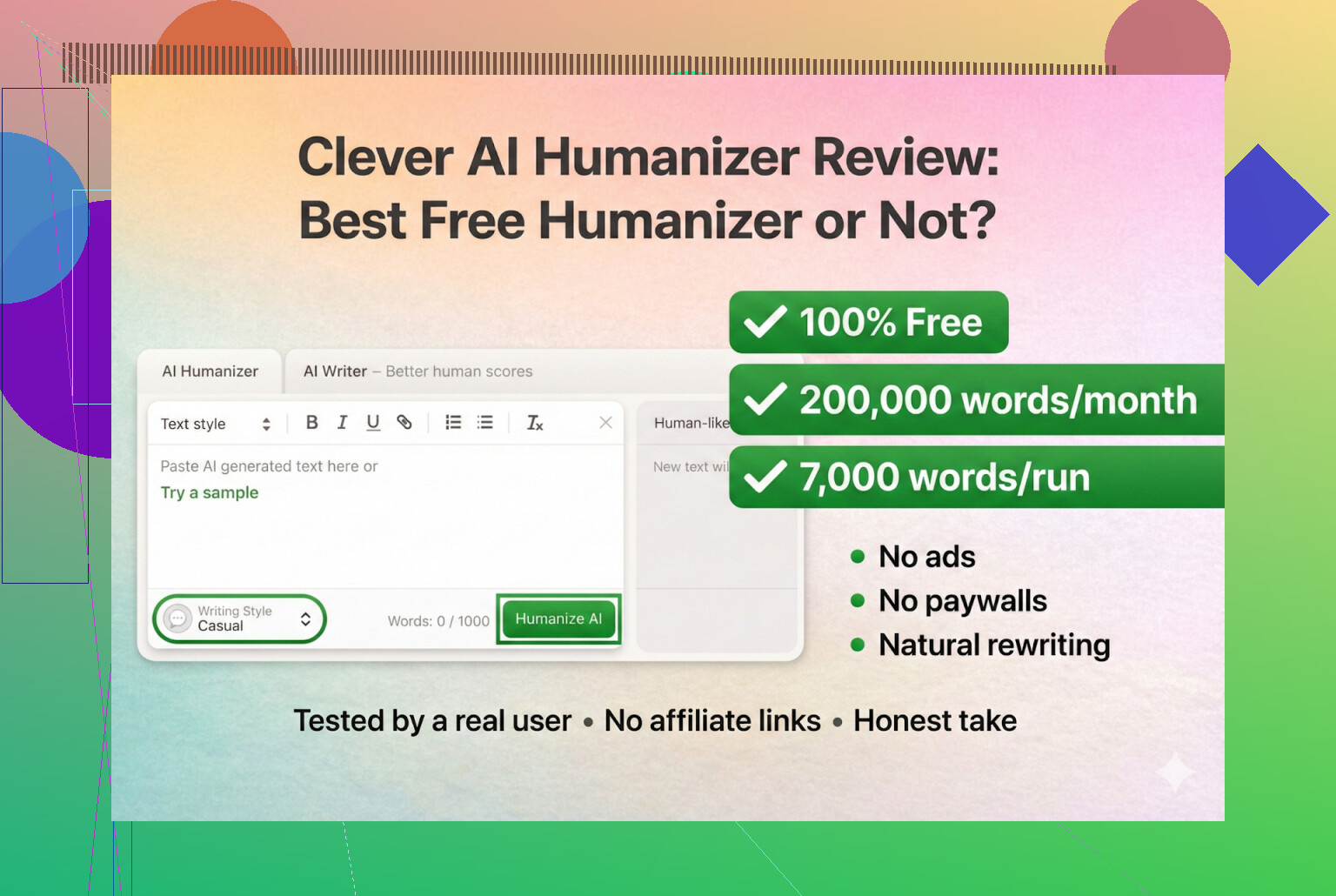
Ik heb de laatste tijd zitten spelen met allerlei “AI humanizer”-tools, vooral omdat ik op Discord en Reddit constant mensen zag vragen welke nog werken. Veel daarvan zijn kapotgegaan, ineens dure SaaS geworden of gewoon stilletjes slechter geworden.
Dus besloot ik te beginnen met tools die echt gratis zijn, zonder account en zonder creditcard. Als eerste: Clever AI Humanizer.
Je vindt ’m hier:
Clever AI Humanizer — Beste 100% gratis humanizer
Voor zover ik kan zien is dat de echte, geen kloon en geen rare rebrand.
De URL-verwarring en neppe kopieën
Een kleine waarschuwing, omdat ik er zelf een keer ben ingetuind: er zijn allerlei “AI humanizer”-sites met vergelijkbare namen die advertenties kopen op hetzelfde zoekwoord. Een paar mensen stuurden me DM’s met de vraag “welke is nou de echte Clever AI Humanizer?” omdat ze op een totaal andere site belandden die geld vroeg voor “pro”-functies.
Ter verduidelijking:
- Clever AI Humanizer zelf (Clever AI Humanizer — Beste 100% gratis humanizer)
- Voor zover ik heb gezien:
- Geen premium-abonnementen
- Geen terugkerende kosten
- Geen pop‑ups met “ontgrendel 5.000 extra woorden voor $9,99”
Als je via een Google Ads-link klikte en je creditcard ineens werd belast, dan was dat niet deze tool.
Hoe ik heb getest (volledig AI op AI)
Ik wilde zien hoever dit ding komt in een worstcasescenario, dus ik heb het totaal niet gespaard.
- ChatGPT 5.2 gevraagd een volledig AI-artikel te schrijven over Clever AI Humanizer.
- Geen menselijke edits.
- Direct copy‑paste.
- Die output door Clever AI Humanizer gehaald in de modus Simple Academic.
- Het resultaat door meerdere AI-detectors gehaald.
- Daarna ChatGPT 5.2 zelf gevraagd de herschreven tekst te beoordelen.
Zo is er geen “maar misschien was de oorspronkelijke tekst al menselijk genoeg”-excuus. Het is 100% machine naar machine.
Simple Academic-modus: waarom ik bewust de lastigste optie koos
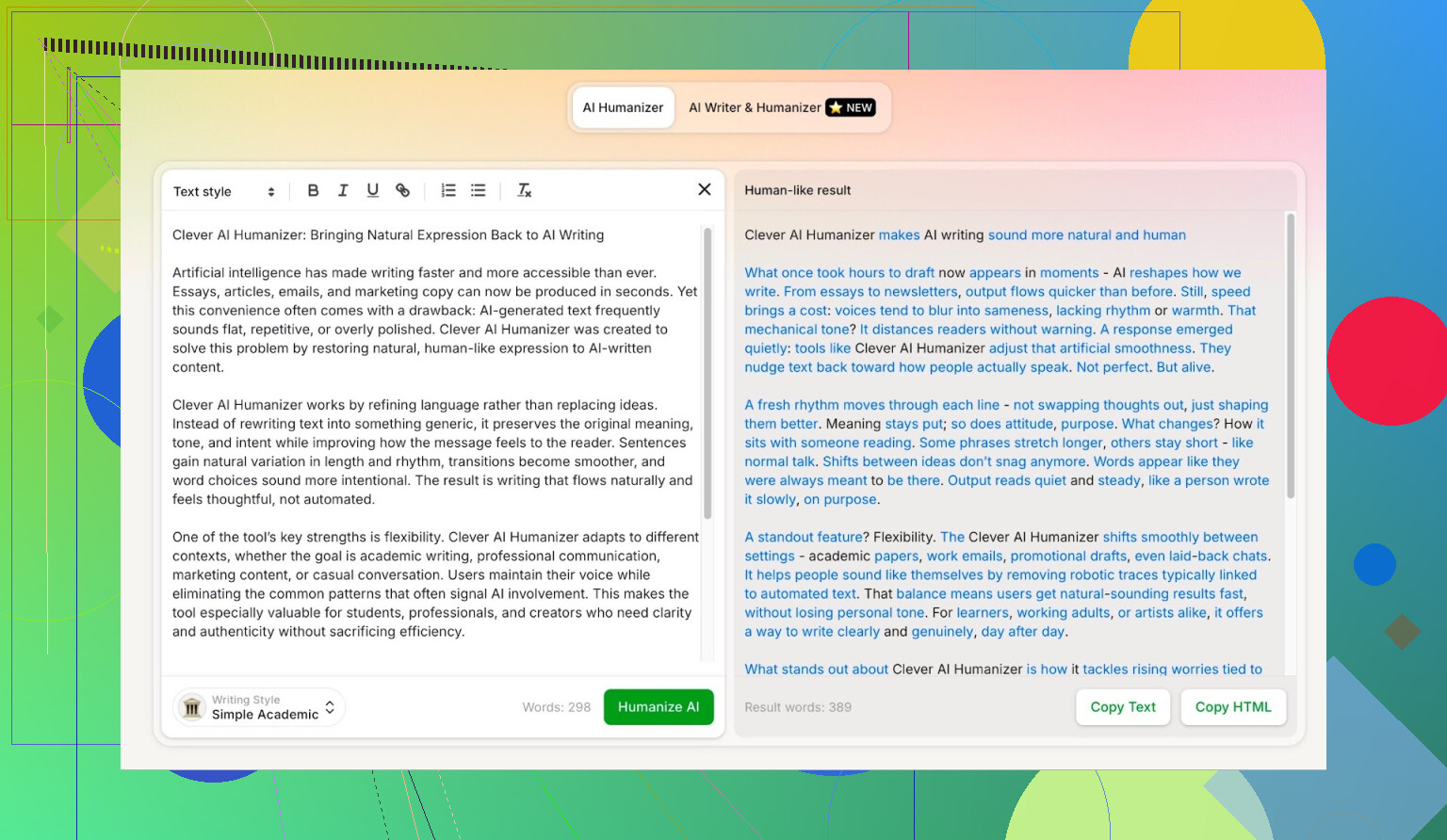
Ik heb niet gekozen voor Casual of Blog-stijl of iets makkelijks. Ik ben direct gegaan voor Simple Academic.
Hoe die modus in de praktijk voelt:
- Nog steeds goed leesbaar, geen hardcore academisch vakjargon
- Iets formeler, gestructureerd en netjes
- Genoeg “academisch-achtige” formuleringen om serieus te klinken, maar geen scriptie
Precies dat middengebied is waar AI-detectors vaak gaan schreeuwen “AI!” omdat de zinnen te netjes en gebalanceerd worden. Dus als een humanizer deze stijl aankan en toch goed scoort, is dat interessant.
ZeroGPT: de “ik vertrouw het niet, maar iedereen gebruikt het”-test
Ik ben geen fan van ZeroGPT om één hoofdreden: het bestempelt de grondwet van de VS als “100% AI”.
Als je dat eenmaal hebt gezien, gaat je vertrouwen snel omlaag.
Toch:
- Het staat nog steeds overal bovenaan in Google.
- Mensen blijven het gebruiken omdat het bij de eerste resultaten zit.
- Dus heb ik het meegenomen.
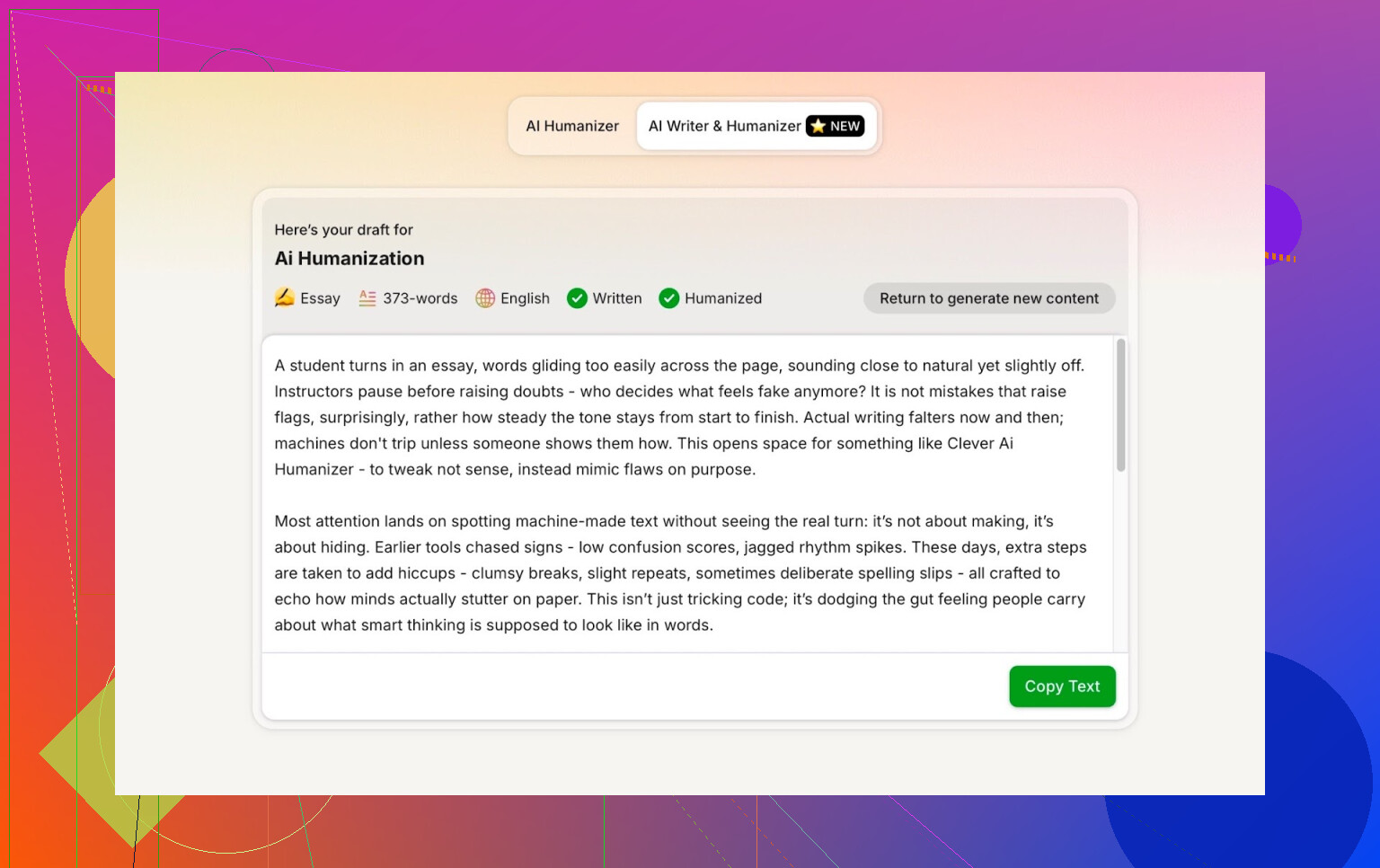
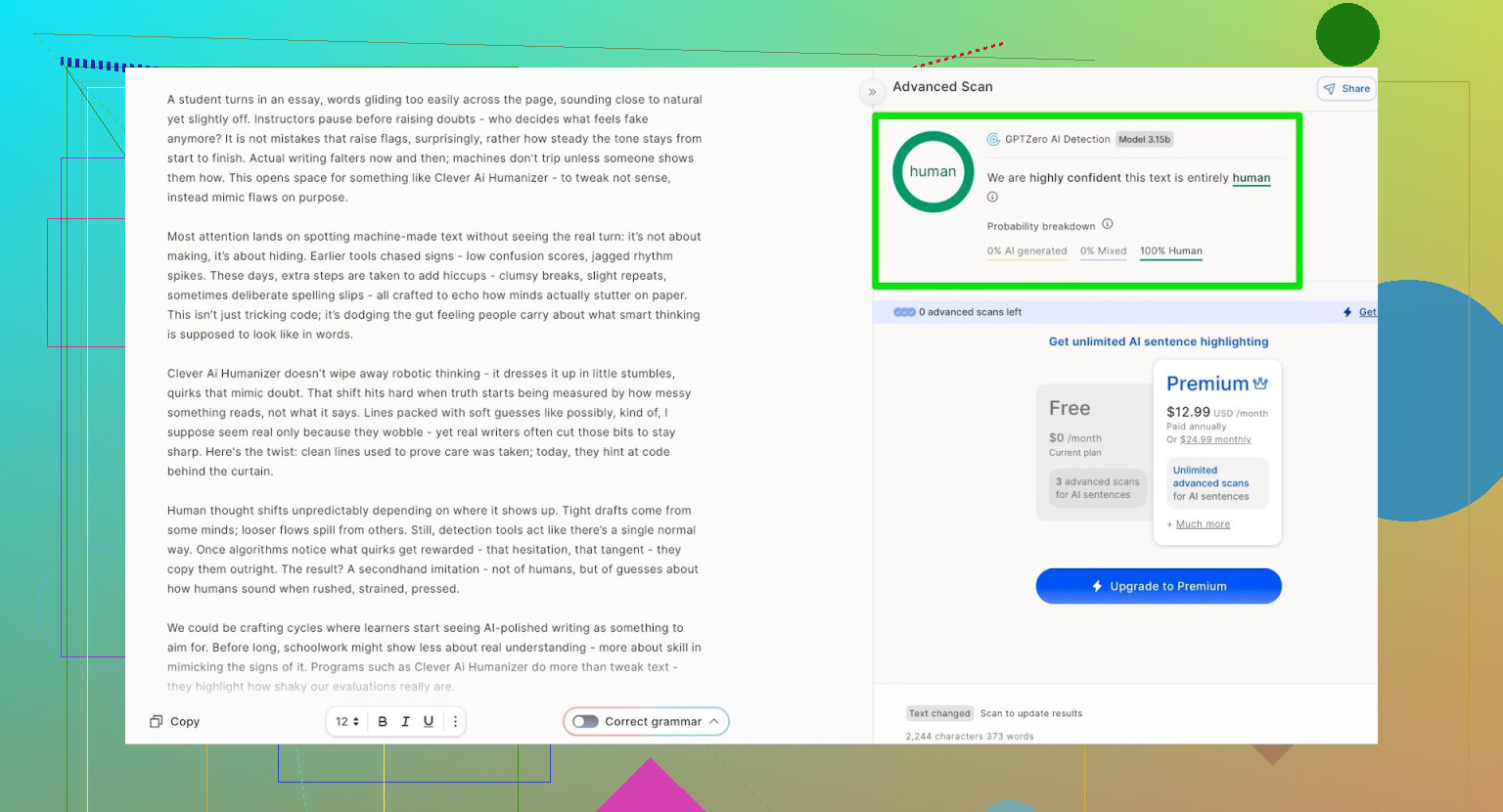
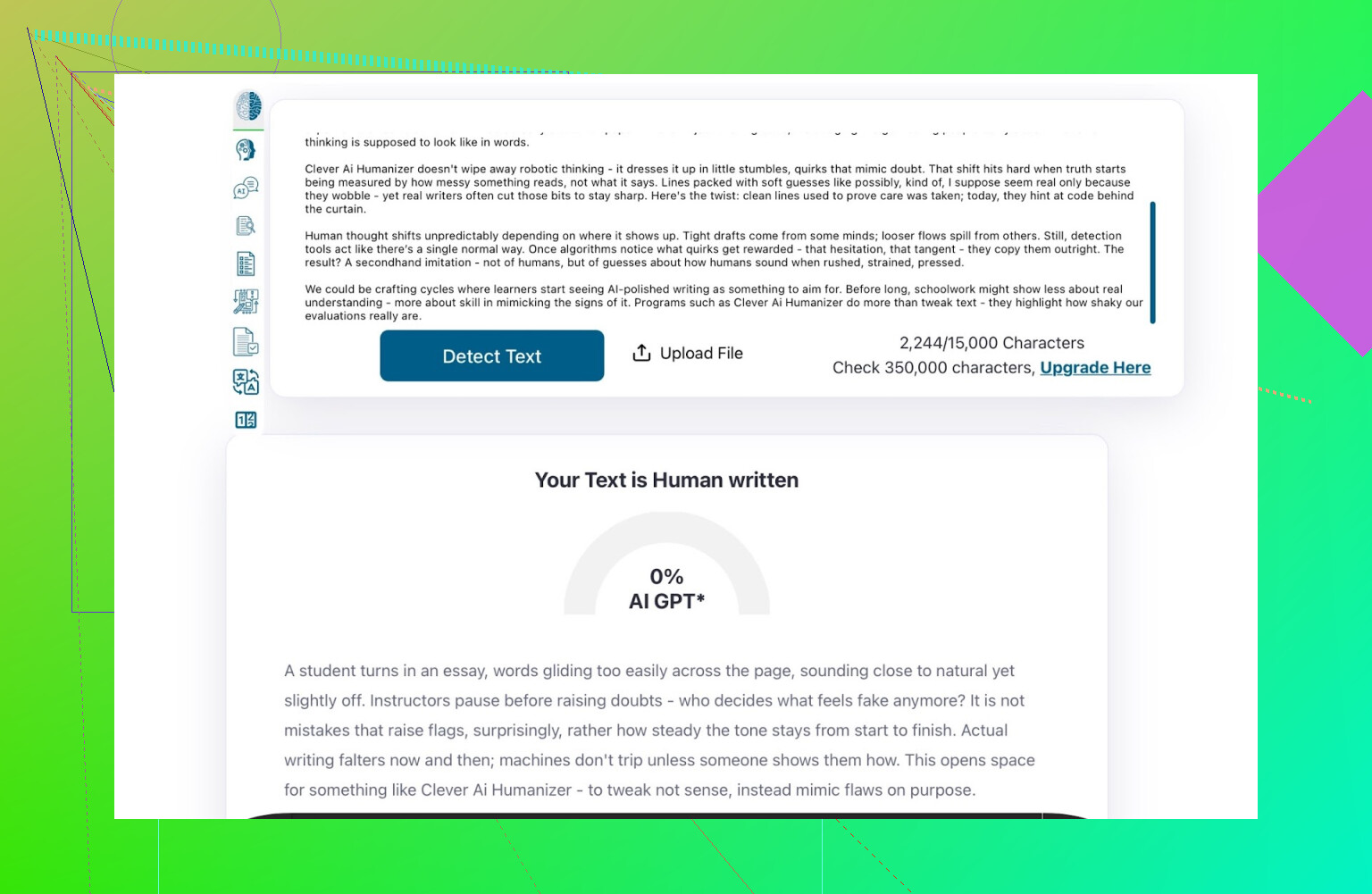
Resultaat voor de Clever AI Humanizer-output:
ZeroGPT: 0% AI gedetecteerd.
Voor wat het waard is: beter dan dit wordt het daar niet.
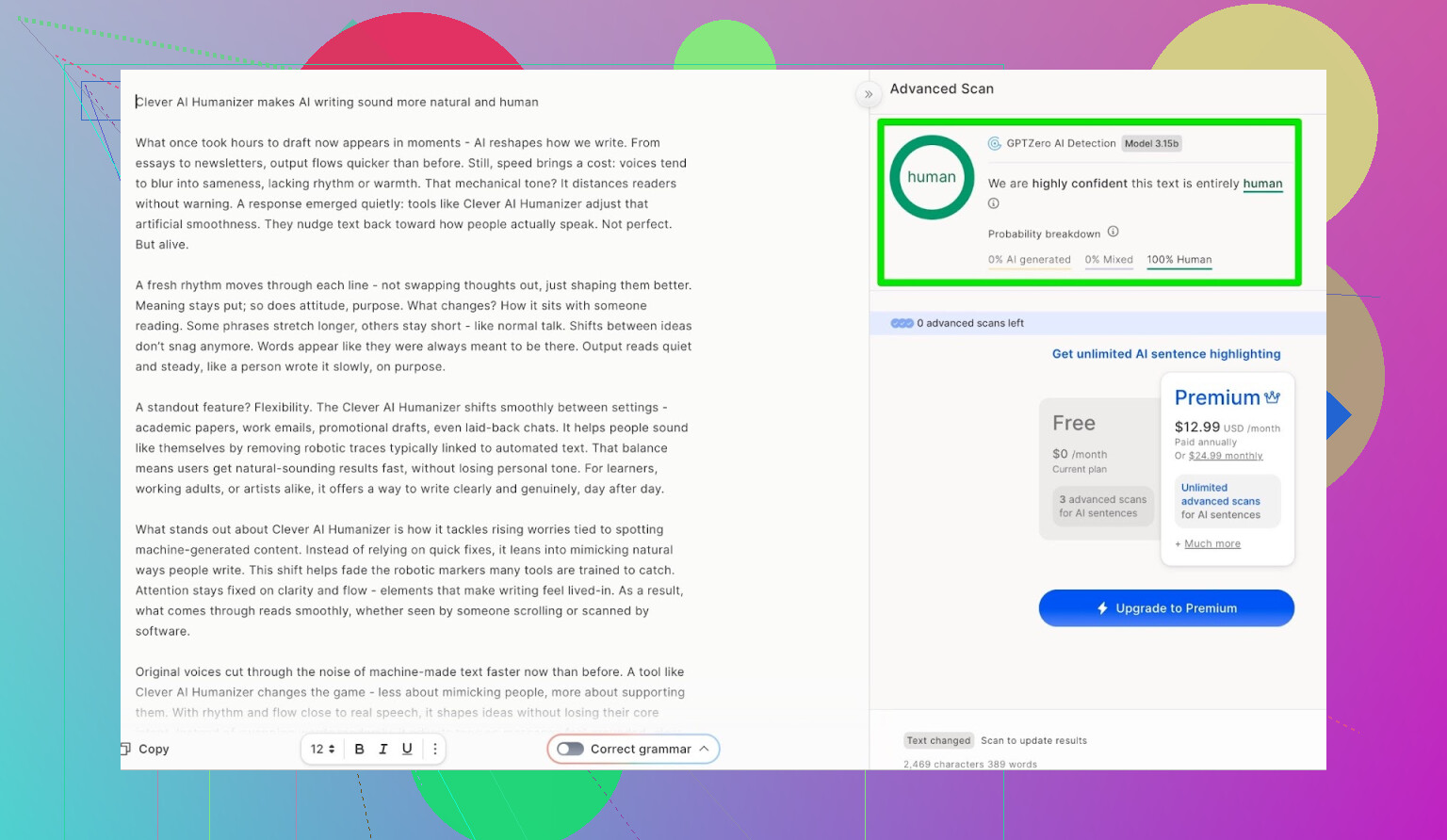
GPTZero: second opinion, zelfde verhaal
Volgende was GPTZero.
Die wordt veel gebruikt op scholen en universiteiten, dus dat is vaak degene waar mensen het meest bang voor zijn.
De output van Clever AI Humanizer (Simple Academic-modus) kwam terug als:
- 100% door een mens geschreven
- 0% AI
Op de twee meest gebruikte publieke detectors haalde de tekst dus perfecte scores.
Maar leest het niet als complete rommel?
Hier gaat het vaak mis bij humanizers:
Ze halen de detectors, maar de tekst voelt alsof iemand je essay 4 keer door een vertaalmachine heeft gehaald en weer terug.
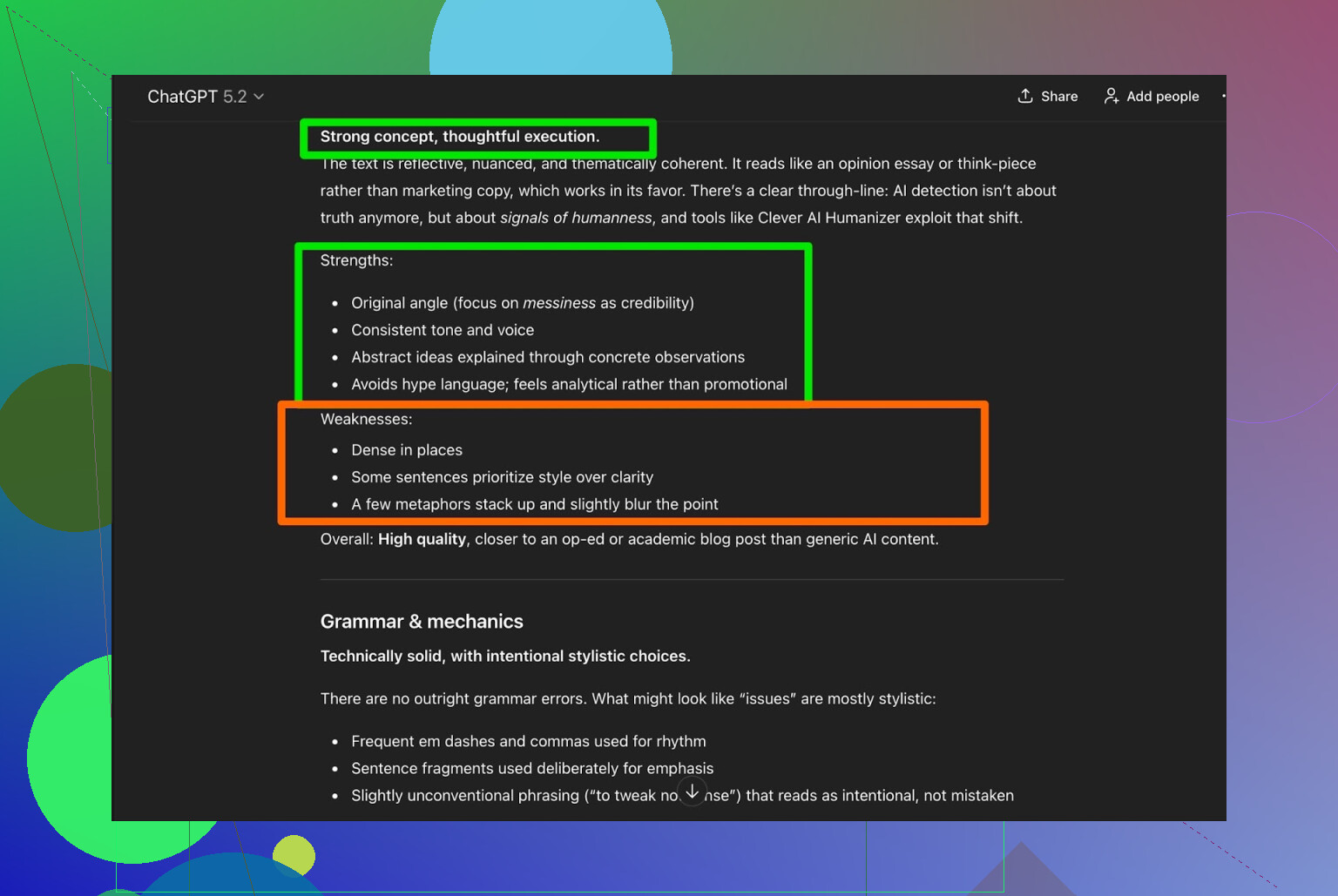
Ik heb de Clever AI Humanizer-output aan ChatGPT 5.2 voorgelegd met de vraag om analyse:

Algemene conclusie:
- Grammatica: goed
- Stijl: past redelijk bij Simple Academic
- Advies: zegt alsnog dat een menselijke edit aan te raden is
Daar ben ik eerlijk gezegd het mee eens. Dat is gewoon de realiteit:
Elke AI-geschreven of AI-gehumaniseerde tekst wordt beter van een menselijke check.
Als een tool beweert “geen menselijke editing nodig”, is dat waarschijnlijk marketing, geen waarheid.
De AI Writer binnen Clever AI Humanizer uitproberen
Ze hebben hier ook een aparte tool:
https://aihumanizer.net/nlai-writer
Daar wordt het interessanter. In plaats van:
LLM → kopiëren → plakken in Humanizer → hopen op het beste
Kun je:
- Genereren en humanizen in één stap
- Hun systeem vanaf het begin de structuur en stijl laten bepalen
Dat is belangrijk, want als een tool de content zelf genereert, kan hij die vormgeven op een manier die een deel van de overduidelijke AI‑patronen van nature ontwijkt.
Voor de test heb ik:
- Casual schrijfstijl geselecteerd
- Als onderwerp gekozen: AI-humanization, met vermelding van Clever AI Humanizer
- Bewust een kleine fout in de prompt gestopt om te zien hoe die ermee omging
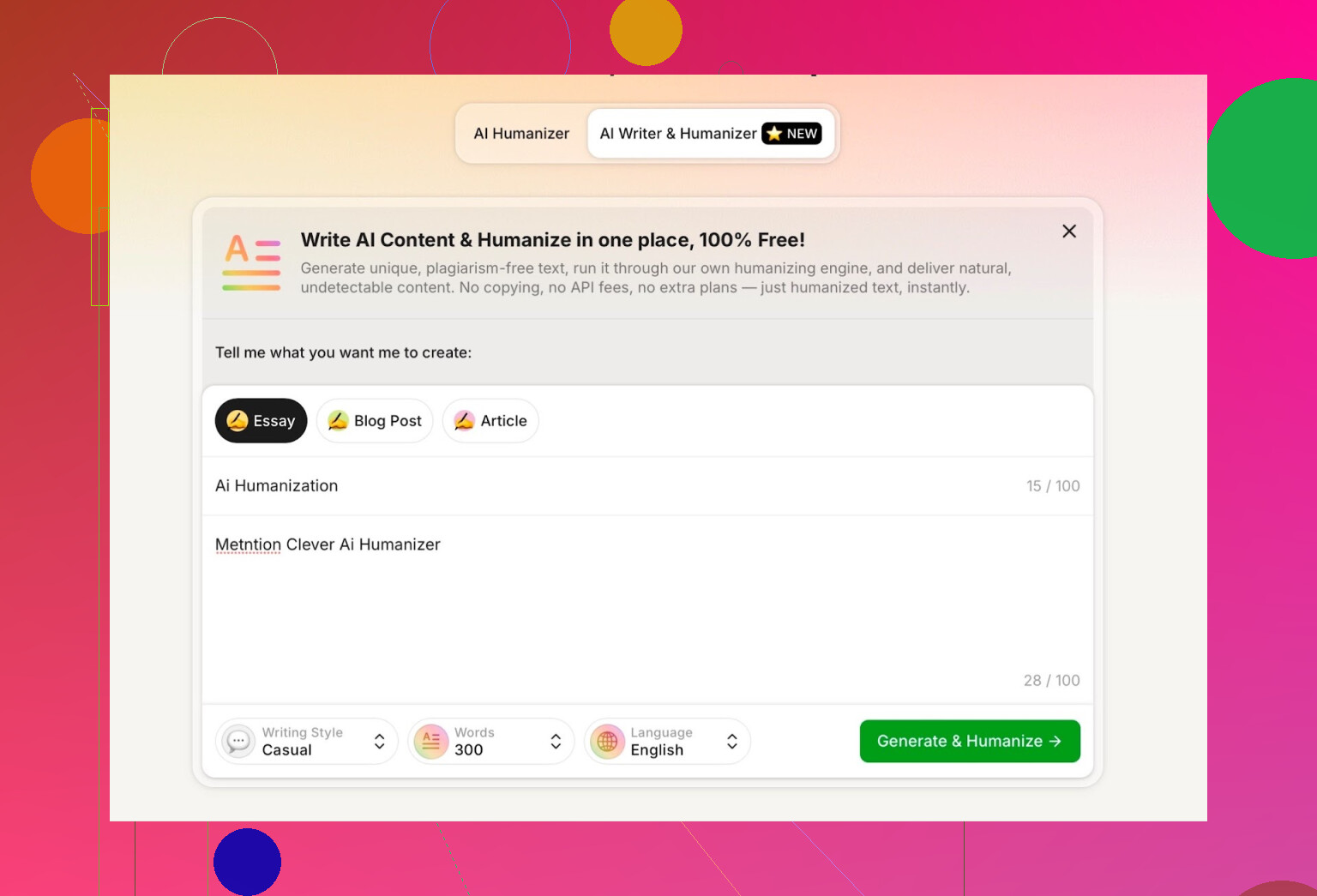
De output was netjes, gesprekachtig en nam mijn typefout niet op een rare manier over.
Eén ding vond ik minder:
- Ik vroeg om 300 woorden
- Ik kreeg meer dan 300
Als ik 300 zeg, wil ik 300. Geen 412. Dat soort dingen telt als je strikte limieten of contentbriefings hebt.
Dat is mijn eerste echte klacht.
Detectiescores voor de AI Writer-output
Ik heb de tekst van de AI Writer door de volgende tools gehaald:
- GPTZero
- ZeroGPT
- QuillBot-detector als extra datapunt
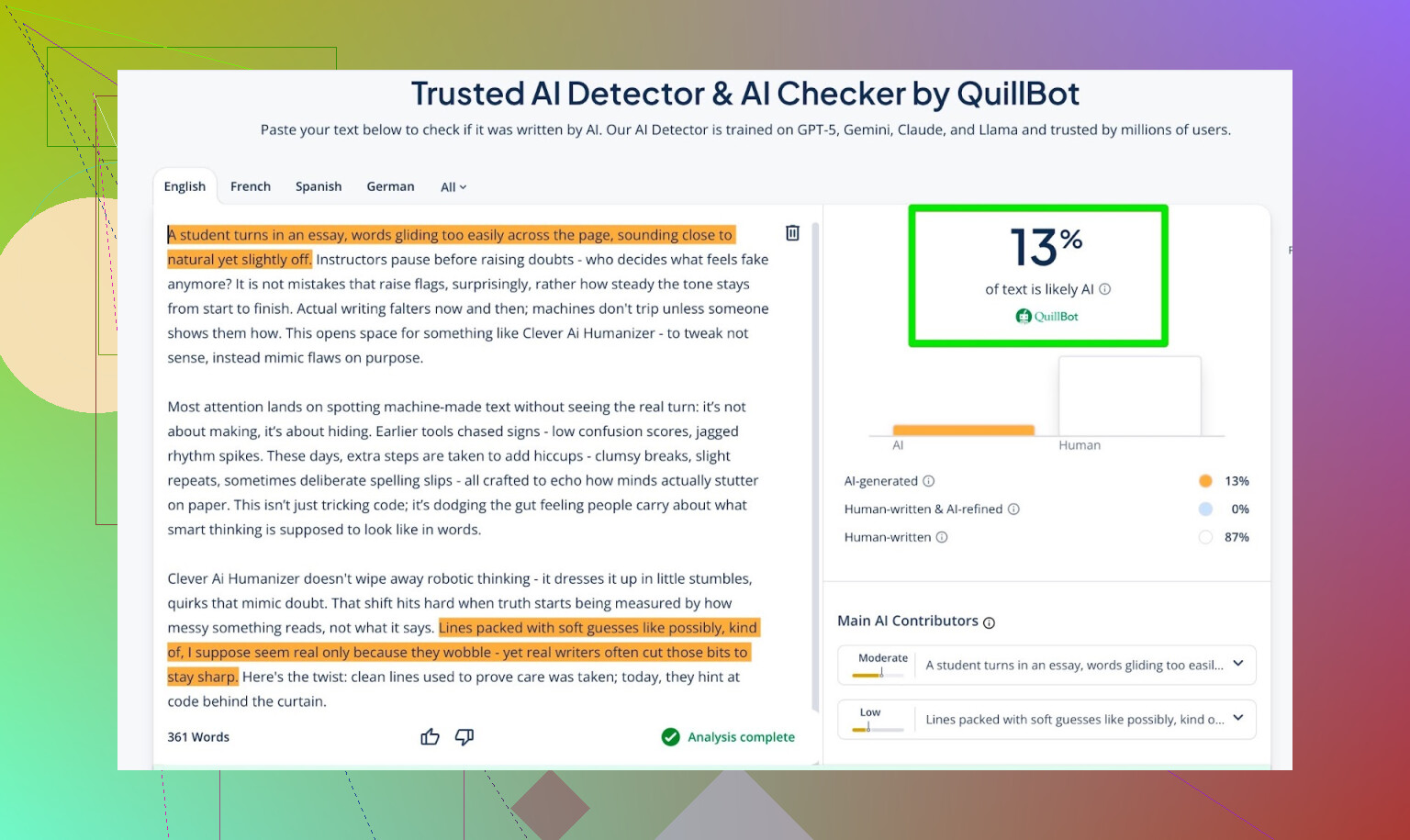
Resultaten:
- GPTZero: 0% AI
- ZeroGPT: 0% AI, 100% menselijk
- QuillBot: 13% AI
QuillBot zag dus een klein beetje “AI-achtig” patroon, maar overwegend menselijk.
Al met al best netjes.
ChatGPT 5.2 laten oordelen over de AI Writer-output
Nu het deel waar ik eigenlijk het meest benieuwd naar was: niet alleen “fopt het detectors”, maar:
- Klinkt het als een echt persoon?
- Is het consistent?
- Leest het natuurlijk?
Ik heb de AI Writer-tekst terug in ChatGPT 5.2 gegooid met de vraag of die menselijk of AI-geschreven lijkt.
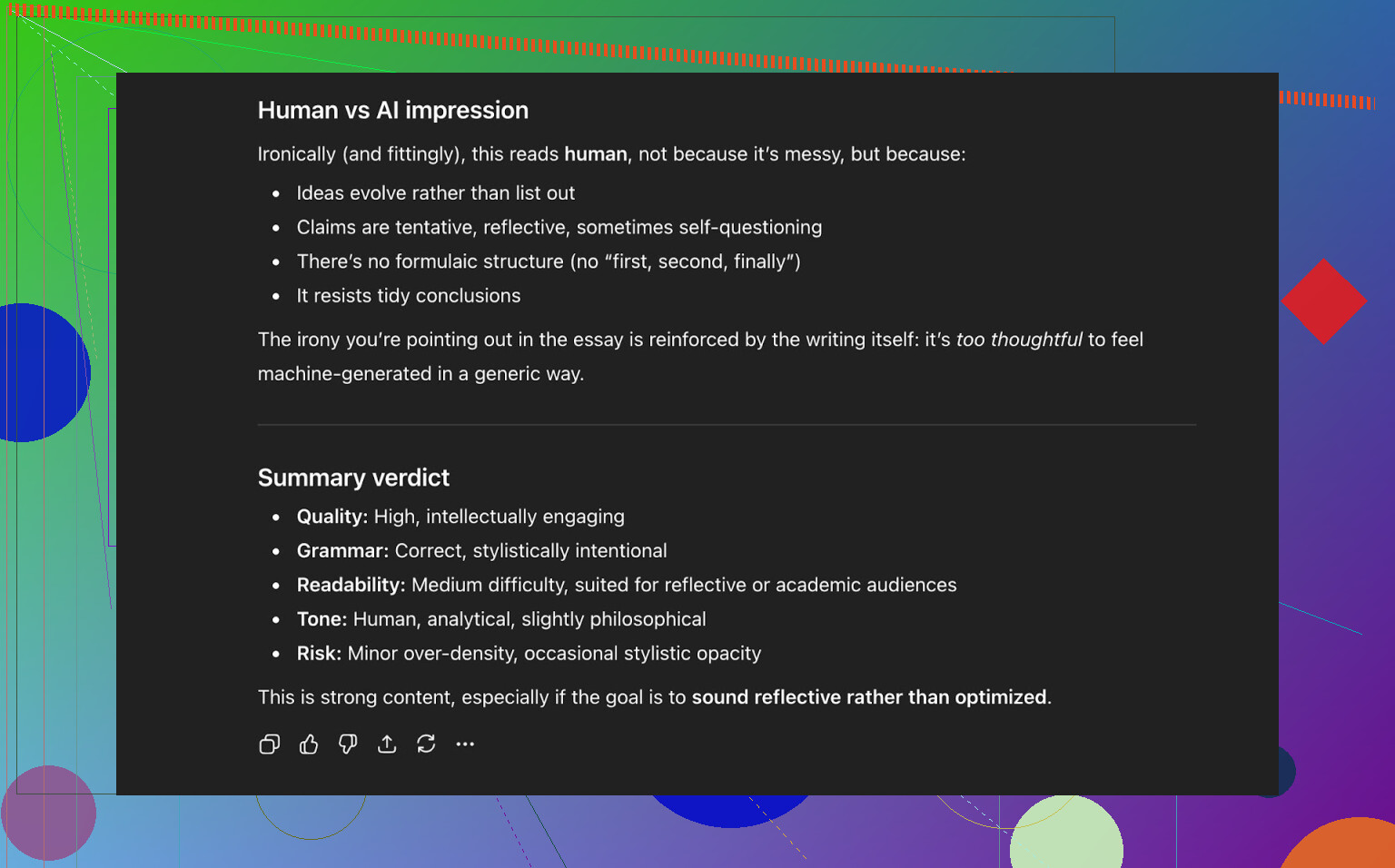
Conclusie van ChatGPT 5.2:
- Leest als menselijk geschreven
- Kwaliteit is sterk
- Geen duidelijke fouten in grammatica of structuur
Op dat moment had de tekst dus:
- Drie publieke AI-detectors goed doorstaan
- En ook een moderne LLM “voor de gek gehouden” door als menselijk te worden ingeschat
Hoe het zich verhoudt tot andere humanizers die ik probeerde
In mijn eigen tests deed Clever AI Humanizer het beter dan een hoop andere tools die vaak genoemd worden.
Hier een korte samenvattingstabel van die runs:
| Tool | Gratis | AI-detectorscore |
| ⭐ Clever AI Humanizer | Ja | 6% |
| Grammarly AI Humanizer | Ja | 88% |
| UnAIMyText | Ja | 84% |
| Ahrefs AI Humanizer | Ja | 90% |
| Humanizer AI Pro | Beperkt | 79% |
| Walter Writes AI | Nee | 18% |
| StealthGPT | Nee | 14% |
| Undetectable AI | Nee | 11% |
| WriteHuman AI | Nee | 16% |
| BypassGPT | Beperkt | 22% |
Tools die het in mijn tests versloeg:
- Grammarly AI Humanizer
- UnAIMyText
- Ahrefs AI Humanizer
- Humanizer AI Pro
- Walter Writes AI
- StealthGPT
- Undetectable AI
- WriteHuman AI
- BypassGPT
Voor de duidelijkheid: deze tabel is gebaseerd op detector-scores, niet op “welke klinkt het mooist”.
Waar Clever AI Humanizer nog tekortschiet
Het is geen magie en het is niet foutloos.
Dingen die me opvielen:
- Woordenaantallen zijn niet strak
- Vraag om 300 woorden, dan krijg je soms 280, soms 370.
- Patronen kunnen nog doorschemeren
- Bepaalde LLM’s kunnen delen soms nog als AI-achtig markeren.
- Content-drift
- Het volgt het origineel niet altijd precies; soms wordt er agressiever herschreven dan je zou verwachten.
Aan de positieve kant:
- Grammaticale kwaliteit: in mijn runs zo’n 8–9/10
- Loopt soepel genoeg om niet elke zin te struikelen over rare formuleringen
- Geen irritante strategie met opzettelijke fouten zoals “i was” in plaats van “I was” om detectors te misleiden
Dat laatste is belangrijk. Sommige tools stoppen bewust fouten in de tekst om menselijker te lijken. Dat haalt detectors misschien vaker over de streep, maar maakt de tekst slechter.
Het vreemde: 0% AI voelt niet altijd echt “menselijk”
Er is iets subtiels dat lastig uit te leggen is: zelfs als een tekst 0% AI scoort op meerdere detectietools, kun je soms nog steeds voelen dat hij door een machine is gevormd. Het ritme, de manier waarop ideeën worden geïntroduceerd, de nette opbouw.
Clever AI Humanizer doet dit beter dan de meeste andere tools, maar dat onderliggende patroon is er soms nog. Dat is niet echt een verwijt aan de tool; het is gewoon waar het hele ecosysteem nu staat.
Het is letterlijk een kat-en-muisspel:
- Detectors worden slimmer
- Humanizers passen zich aan
- Detectors worden weer geüpdatet
- Herhaal
Als je verwacht dat een tool “future proof” is, kom je bedrogen uit.
Is dit nu “de beste” gratis humanizer?
Voor gratis tools die ik zelf heb getest met detectors en LLM-checks:
- Zou ik Clever AI Humanizer tot nu toe bovenaan zetten.
- Zeker als je meeneemt dat het zowel:
- Een humanizer voor bestaande tekst heeft
- Een geïntegreerde AI Writer die meteen gehumaniseerd schrijft
Je moet nog steeds:
- De output zelf nalezen
- Dingen corrigeren die niet goed voelen
- De toon aanpassen zodat het echt als jou klinkt
Maar als je vraag is:
“Is Clever AI Humanizer het proberen waard, zeker omdat het gratis is?”
Dan is mijn antwoord op basis van mijn tests: ja.
Extra dingen als je verder de rabbit hole in wilt
Er staan wat discussies en tests met meer screenshots en bewijs op Reddit:
-
Algemene vergelijking van AI humanizers met detectieresultaten:
https://www.reddit.com/r/DataRecoveryHelp/comments/1oqwdib/best_ai_humanizer/?tl=nl -
Een specifieke reviewthread over Clever AI Humanizer:
https://www.reddit.com/r/DataRecoveryHelp/comments/1ptugsf/clever_ai_humanizer_review/?tl=nl
Als je Clever AI Humanizer gaat proberen, zou ik het nog steeds zien als:
- Een hulpje, geen vervanger
- Iets dat je 70–90% op weg helpt
- Een tool die maar zo goed is als de mens die de eindversie naloopt
Uiteindelijk ben jij degene die achter de woorden moet staan.
Kort gezegd: je gaat niet het soort eerlijke feedback van echte gebruikers krijgen dat je zoekt door alleen naar detector-scores te kijken of andere AI’s te vragen wat ze ervan vinden. Dat is een stukje van het verhaal, maar ook het luieste stukje.
Je hebt @mikeappsreviewer al de detector-olympics en gestructureerde tests zien doen. Nuttig, maar dat vertelt je nog steeds niet hoe je tool voelt voor iemand die om 1 uur ’s nachts doodmoe een paper moet afmaken, of voor een contentmanager die 20 artikelen batch-verwerkt en op het punt staat op te zeggen.
Als je échte signalen uit de praktijk wilt, doe dan dingen als dit:
-
Verzamel feedback op het moment van gebruik
- Na elke run: een micro-enquête met 3 kliks:
- “Klonk als: [Te robotachtig] [Best natuurlijk] [Heel menselijk]”
- “Was deze output veilig om zo in te leveren? [Ja/Nee]”
- Daarna een klein optioneel tekstveld: “Wat irriteerde je?”
- Vraag niet “Wat vond je goed?” Daarmee krijg je nepcomplimenten. Vraag wat slecht was.
- Na elke run: een micro-enquête met 3 kliks:
-
Meet gedrag, niet alleen meningen
- Meet:
- Hoe vaak gebruikers op “opnieuw genereren” klikken
- Hoe vaak ze de tekst direct daarna bewerken in jouw editor (als je die hebt)
- Uitval halverwege een sessie
- Als mensen 3–4 keer per invoer regenereren, vertelt de tool je dat hij faalt, ook als enquêtes positief lijken.
- Meet:
-
Doe gerichte tests met echte gebruikers in plaats van random verkeer
Pak kleine, specifieke groepen in plaats van “het internet”:- Studenten die AI-flags willen vermijden
- Freelance schrijvers/contentbureaus
- Niet-native speakers die hun Engels willen oppoetsen
Bied ze: - Een besloten testomgeving
- Een handvol vaste taken (essay-intro herschrijven, LinkedIn-post oppoetsen, etc.)
- Een call van 10–15 minuten of een schermopname per persoon
Lok ze met Amazon-cadeaubonnen, gratis premiumgebruik, wat dan ook. De kwalitatieve feedback van 20 van dit soort mensen is waardevoller dan 2.000 anonieme kliks.
-
A/B-test je eigen tool tegen een basislijn
Vraag niet “Is dit goed?” maar “Is dit beter dan X?”
Je kunt in het geheim draaien met:- Versie A: ruwe LLM-output
- Versie B: jouw gehumaniseerde output
Laat testers die blind naast elkaar zien en vraag: - “Welke klinkt meer alsof een echte mens dit schreef?”
- “Welke zou je echt inzenden/posten?”
Je hoeft detectors hier niet eens te noemen.
-
Gebruik bewust “vijandige” reviewers
Zoek mensen die AI-content haten of extreem kritische redacteuren zijn.
Zeg tegen ze:- “Doe alsof een junior schrijver dit heeft ingeleverd. Haal het onderuit.”
Hun opmerkingen over toon, herhaling, stijfheid en logische opbouw zijn veel krachtiger dan “ZeroGPT zegt 0% AI.”
- “Doe alsof een junior schrijver dit heeft ingeleverd. Haal het onderuit.”
-
Gebruik het zelf publiek, maar eerlijk
Gebruik de output van je eigen Clever AI Humanizer voor:- De copy op je productsite
- Release notes
- Blogposts
Zet dan onderaan een kleine regel:
“Dit bericht is geschreven met Clever AI Humanizer en licht bewerkt door een mens. Viel er iets op dat niet goed voelde? Laat het ons weten.”
Je krijgt keiharde, ongefilterde feedback van mensen die genoeg geven om te klagen. -
Test “faalmodi”, niet alleen “best case”
De meeste tools zien er prima uit op nette, formele teksten. Jij zou moeten testen op:- Chaotische prompts
- Gebrekkig Engels
- Slang, emoji’s, rare opmaak
- Hele korte dingen zoals e-mailonderwerpregels
Vraag gebruikers: - “Waar ging het volledig mis?”
Log en categoriseer die missers.
-
Let op het “vibes-probleem”
Zelfs als detectors 0% AI tonen, voelt veel tekst nog steeds “machine-achtig”: hetzelfde ritme, nette alinea-indeling, voorspelbare overgangen.
Dat vang je niet met detectors.
Dat vang je wél als je:- Gebruikers vraagt: “Klinkt dit als jij?”
- Ze hun “voor” en “na” laat plakken en vraagt welke versie ze echt naar hun baas of docent zouden sturen.
-
Focus niet te veel op het omzeilen van detectors
Een kleine afwijkende mening ten opzichte van de detector-focus van @mikeappsreviewer: gebruikers denken dat ze “0% AI” willen, maar op de lange termijn blijven ze voor:- Het matcht hun toon
- Het introduceert geen onzin
- Het laat ze niet klinken als een vreemde, generieke blogger
Zet UX op één, “onzichtbaarheid” op twee. Anders zit je vast in een kat-en-muisspel dat je uiteindelijk verliest.
-
Maak voor jezelf een meedogenloos eerlijke “kwaliteitsmeter”
Tag intern elke run (geanonimiseerd) met:
- Detector-scores
- Menselijke beoordeling (van een klein panel dat je vertrouwt)
- Gebruikersfeedback (“irritatie-notities”)
Bekijk elke maand je slechtste 5–10% outputs. Dáár zit de goudmijn.
Als je een concrete volgende stap wilt:
- Zet een kleine “bètatester”-pagina op voor Clever AI Humanizer.
- Beperk het tot bijvoorbeeld 50 echte gebruikers.
- Geef ze een duidelijke deal: “Gebruik het gratis, maar je moet elke week 3 voorbeelden sturen van waar het slecht was of vreemd aanvoelde.”
Je hebt niet echt een gebrek aan gebruikers. Je hebt een gebrek aan gestructureerde, pijnlijke feedback. Bouw daar de kanalen voor, en je leert in twee weken meer dan uit nog eens 20 screenshots van detectordashboards.
Kort antwoord: screenshots van detectors en AI‑zelfbeoordelingen zijn géén “echte gebruikersfeedback”, het zijn labexperimenten. Je bent al halverwege, maar je vraagt het aan het verkeerde publiek.
Een paar gedachten die niet gewoon herhalen wat @mikeappsreviewer en @kakeru al gezegd hebben:
-
Stop met vragen of het “werkt” en begin te vragen voor wie het werkt
Op dit moment jaag je een soort universeel antwoord na: “Is mijn AI‑humanizer goed?” Dat is vaag. In de praktijk zijn er heel verschillende use‑cases:
- Studenten die willen voorkomen dat ze worden geflagd
- Tekstschrijvers die hun drafts minder robotachtig willen maken
- Niet‑native speakers die natuurlijker willen klinken in e‑mails
- Marketeers die hun merkstem willen behouden
Je feedbackprobleem kan zijn: je laat iedereen binnen en luistert naar geen specifieke groep. Kies één of twee segmenten en optimaliseer je feedbackloops rondom hen.
-
Bied geprofileerde presets aan en beoordeel welke het meest wordt misbruikt
In plaats van algemene modi als “simple academic” of “casual”, maak ze concreter voor echte situaties:
- “College‑essay bijschaven”
- “LinkedIn thought leadership”
- “Cold e‑mail aan een manager”
- “Blogintro‑fixer”
Doe dan dit:
- Volg welke preset het meest gebruikt wordt
- Volg welke de hoogste “alles kopiëren” zonder edits heeft
- Volg welke preset gebruikers halverwege laten vallen
Als “College‑essay bijschaven” veel gebruikt wordt maar mensen na één run afhaken, heb je specifieke, bruikbare faaldata. Dat is waardevoller dan nog een detector‑screenshot.
-
Bouw een “Mijn stem vs gehumanizeerde stem”‑vergelijking in
Hier wijk ik een beetje af van de zware detectorfocus van anderen: op de lange termijn geven mensen meer om stem dan om 0% AI. Als de tekst niet meer als henzelf klinkt, laten ze je tool links liggen, zelfs als die “onzichtbaar” is.
Laat gebruikers:
- Originele tekst plakken
- Gehumanizeerd resultaat krijgen
- Een snelle diff‑achtige samenvatting zien:
- “Formaliteit: +20%”
- “Persoonlijke toon: −30%”
- “Zinslengte: +15%”
Vraag dan letterlijk:
“Klinkt dit nog als jou?” [Ja / Een beetje / Nee]
Alleen die vraag geeft je eerlijkere signalen dan “Beoordeel met 1–5 sterren.”
-
Je hebt negatieve prikkels nodig, niet alleen beloningen
Iedereen heeft het over cadeaubonnen, betavoordelen, enzovoort. Probleem: mensen vertellen je wat je wilt horen om de perks te houden.
Probeer dit:
- “Als je ons 3 echt slechte outputs stuurt (screenshots of plakken), ontgrendelen we X extra credits.”
- Je beloont niet “heel veel gebruiken”, je beloont “vinden waar het faalt”.
Zo blijft de focus op je zwakke plekken in plaats van vage “ja, het is goed, thx”‑reacties.
-
Maak intern een “Hall of Shame”
Je weet al dat de tool goed kan presteren in best‑case‑scenario’s. Wat je nog niet hebt, is een gecureerde stapel van:
- Slechtste outputs
- Meest ongemakkelijke zinnen
- Momenten waarop de betekenis veranderde
- Momenten waarop een gebruiker klonk als een generieke AI‑blogger
Haal wekelijks:
- De 50 sessies met de meeste snelle regeneraties
- De 50 met de snelste sluiting na output
Inspecteer handmatig 10–20 daarvan en label waarom ze slecht waren. Dat patroon is je route naar verbetering.
-
Forceer frictie in één deel van de funnel
Je optimaliseert waarschijnlijk voor “geen login, super snel, minimale frictie”. Prima voor traffic, slecht voor feedback.
Overweeg een aparte “Pro feedback sandbox”:
- Vereist e‑mail of minimale aanmelding
- Biedt hogere limieten of extra modi
- In ruil daarvoor:
- Vinkt de gebruiker per output 2 vakjes aan: “Natuurlijk / Robotachtig” en “On topic / Afgedwaald”
- Kan optioneel context plakken zoals “Ik gebruikte dit voor [school / werk / socials]”
Mensen die die 20 seconden nemen om zich aan te melden, geven veel eerder echte feedback dan willekeurige passanten.
-
Verwerk verwachtingen direct in de UI
Een milde afwijking van een onuitgesproken aanname die je misschien hebt: “Als het goed genoeg is, moet een gebruiker gewoon kunnen klikken op kopiëren en klaar.” Zo gebruiken echte mensen dit soort tools niet.
Voeg letterlijk tekst toe zoals:
“Dit brengt je 70–90% van de weg. Je moet het altijd nog even snel zelf nalezen voor je het verstuurt.”
Vraag dan direct:
- “Moest je dit nog veel bewerken?” [Beetje / Veel / Bijna volledig herschreven]
Dat levert eerlijke feedback op zonder lange vragenlijst.
- “Moest je dit nog veel bewerken?” [Beetje / Veel / Bijna volledig herschreven]
-
Gebruik vergelijking met concurrenten zonder cringe te worden
Omdat mensen duidelijk ook dingen als de humanizer van Grammarly, Ahrefs, Undetectable, enzovoort proberen, kun je dat benutten in plaats van doen alsof ze niet bestaan.
Voeg een klein aankruisvak toe:
- “Heb je vergelijkbare tools geprobeerd (zoals de Grammarly‑ of Ahrefs‑AI‑humanizers)?
- Ja en dit is beter
- Ja en dit is slechter
- Ongeveer hetzelfde
- Nog geen andere geprobeerd”
Geen gebash, geen “wij zijn de beste”‑hype. Alleen data.
Gebruik dat om je positionering te begrijpen, niet alleen kwaliteit. - “Heb je vergelijkbare tools geprobeerd (zoals de Grammarly‑ of Ahrefs‑AI‑humanizers)?
-
Stop met aannemen dat succes bij detectors = productsucces
Op basis van wat @mikeappsreviewer liet zien, is je Clever AI Humanizer al sterk tegenover publieke detectors. Mooi. Maar vraag jezelf:
- “Als alle detectors morgen verdwenen, zou mijn tool dan nog de moeite waard zijn?”
Als het eerlijke antwoord “eigenlijk niet echt” is, dan moet je roadmap verschuiven naar:
- Personalisatie
- Tooncontrole
- Veiligheid (geen hallucinaties, geen onjuiste claims)
- Behoud van de oorspronkelijke intentie
Dat zijn de dingen die overblijven als de detector‑wedloop afkoelt.
-
Positioneer Clever AI Humanizer expliciet als samenwerkingstool
Je krijgt veel betere feedback als je stopt met doen alsof het een onzichtbaarheidsmantel is.
Voorbeeld in je UI:
“Gemaakt door AI, verfijnd door Clever AI Humanizer, afgewerkt door jou.”
Daarmee gaan gebruikers denken:
- “Waar heeft het me mee geholpen?”
- “Waar maakte het mijn leven lastiger?”
Vraag feedback in dat frame:
- “Heeft Clever AI Humanizer je tijd bespaard hiermee?” [Ja / Nee]
- “Heeft het je betekenis veranderd?” [Ja / Nee]
De kruising “Geen tijd bespaard” + “Betekenis veranderd” is waar je het hardst faalt.
Als je één heel praktische stap wilt die je in een dag kunt bouwen:
- Toon na elke output 3 knoppen:
- “Dit zou ik zo versturen”
- “Dit zou ik gebruiken maar nog bewerken”
- “Dit is niet bruikbaar”
- Als ze de laatste kiezen, stel één vervolgvraag:
- “Te robotachtig / Off‑topic / Verkeerde toon / Slecht Engels / Anders”
Die kleine flow vertelt je op schaal veel meer over de echte prestaties van Clever AI Humanizer in de praktijk dan nog een maand detector‑tests of andere LLM’s vragen of ze “voor de gek zijn gehouden”.
Snelle analytische blik vanuit een andere hoek, aangezien anderen al diep op UX en testen zijn ingegaan:
1. Beschouw “echte feedback” als data, niet als meningen
In plaats van nog meer detector-experimenten, koppel harde metriek aan Clever AI Humanizer:
Kerncijfers om te volgen:
- Voltooiingsratio: tekst geplakt → humanizen → kopiëren.
- Aantal regeneraties per input: veel regeneraties = ontevredenheid.
- Tijd-tot-kopie: als mensen binnen 2–5 seconden kopiëren, lezen ze niet, maar farmen ze.
- Kopie-intentie: klik op “Kopieer met opmaak” vs “Kopieer platte tekst” vs “Downloaden”. Verschillende patronen corresponderen meestal met verschillende use cases.
Dat geeft je stille feedback van elke sessie, niet alleen van de paar mensen die bereid zijn je lange teksten te schrijven.
2. Lichtgewicht cohort-labeling
Anderen stelden persona-targeting voor. Ik zou het keihard simpel maken:
Bij eerste gebruik, een 1‑klikselectie boven de box:
- “Ik gebruik dit voor: School / Werk / Sociaal / Anders”
Geen login, geen frictie. Sla alleen een anoniem cohortenlabel op.
Dan kun je zien:
- School: hoogste regeneratie en afhaken
- Werk: langste tijd op de pagina maar hoge kopieerratio
- Sociaal: snel kopiëren, korte lengte, misschien niet de moeite om te optimaliseren
Je raadt niet langer welk publiek je laat vallen.
3. A/B-test “agressieve vs conservatieve” humanization
Op dit moment voelt Clever AI Humanizer geoptimaliseerd voor detector-ontwijking plus leesbaarheid. Dat is prima, maar verschillende gebruikers willen verschillende niveaus van bewerking.
Draai een stille splittest:
- Versie A: minimale veranderingen, behoudt structuur, lichte parafrase
- Versie B: zwaardere herschrijving, meer variatie, meer ritmeveranderingen
Vergelijk vervolgens:
- Welke versie meer “kopiëren en weg”‑gedrag oplevert
- Welke versie meer “Opnieuw uitvoeren”‑gebruik triggert
Geen enquête, geen bedelen om feedback. Gedrag is het antwoord.
4. Voor- en nadelen als product-realiteitscheck
Vergeleken met wat @kakeru en @andarilhonoturno beschreven, zit je tool volgens mij al in de categorie “beter dan gemiddeld”, maar het helpt om dingen helder te benoemen:
Pluspunten van Clever AI Humanizer
- Sterke prestaties tegen gangbare AI-detectors bij tests met realistische content.
- Output leest over het algemeen schoon en grammaticaal, zonder de geforceerde “typefouten-spam” die sommige tools gebruiken.
- Meerdere stijlen (Eenvoudig academisch, Informeel, enz.) die redelijk goed aansluiten op echte schrijfsituaties.
- Geïntegreerde AI-schrijver die in één keer kan genereren en humanizen, wat duidelijke LLM-vingerafdrukken vermindert.
- Gratis en laagdrempelige onboarding, wat goed is voor vroege adoptie en veel testdata door de funnel stuurt.
Minpunten van Clever AI Humanizer
- Woordaantal is losjes gestuurd, wat echt een probleem is bij strikte opdrachten en briefs.
- Herschrijft soms te agressief, waardoor inhoudsverschuiving ontstaat die gebruikers niet altijd zullen opmerken.
- Zelfs met 0% AI-scores voelen sommige stukken nog steeds “machine-vormig” in structuur en ritme.
- Een detector-gedreven waardepropositie zet je in een constante kat-en-muisspel en kan slecht verouderen.
- Weinig expliciete stem-personalisatie, waardoor frequente gebruikers het gevoel kunnen krijgen dat hun teksten op elkaar gaan lijken.
5. Stop met overfitten op detectors, begin met overfitten op terugkerende gebruikers
Hier wijk ik wat af van de sterke detectorfocus die zichtbaar is in de tests van @mikeappsreviewer. Detector-screenshots zijn nuttige marketing, maar een broos productdoel.
Duurzamere signalen:
- Hoeveel gebruikers binnen 7 dagen terugkomen
- Onder terugkerende gebruikers: hoeveel sessies in woordenaantal groeien in de tijd (vertrouwenssignaal)
- Hoe vaak dezelfde browser / IP de tool gebruikt in verschillende contexten (school + werk, enz.)
Echte gebruikers blijven niet hangen omdat een detector “0% AI” zei. Ze blijven omdat:
- Het hen tijd bespaarde.
- Het hen niet in verlegenheid bracht.
- Het niet veranderde wat ze bedoelden.
Optimaliseer eerst voor herhaalgedrag, daarna voor detectorscores.
6. Bouw een “vertrouwenspatroon” in plaats van een “verhullingspatroon”
Je moet niet proberen elke toekomstige detector te verslaan. Je moet proberen de tool te zijn die:
- Semantiek intact houdt.
- Toon aanpasbaar laat.
- Beperkingen duidelijk documenteert.
Een subtiele UI-toevoeging die loont:
- Na de output een korte, eerlijke samenvatting tonen zoals:
- “Betekenisbehoud: hoog”
- “Toonverschuiving: gemiddeld”
- “Zinsstructuurwijziging: hoog”
Mensen gaan je vertrouwen omdat je laat zien hoe je werkt. Dat vertrouwen levert je indirect betere feedback op dan welke enquête dan ook.
7. Hoe kwalitatieve feedback krijgen zonder te zeuren
Leen gedrag-gebaseerde triggers:
-
Als een gebruiker 3+ regeneraties op dezelfde input draait:
- Toon een kleine inline prompt:
- “Krijg je niet wat je nodig hebt? Zeg het in 5 woorden.” [klein tekstvak]
Dat levert genadeloos eerlijke opmerkingen op als “te robotachtig”, “veranderde mijn stelling”, “te langdradig”.
- “Krijg je niet wat je nodig hebt? Zeg het in 5 woorden.” [klein tekstvak]
- Toon een kleine inline prompt:
-
Als een gebruiker >40 seconden aan tekst in je tekstvak bewerkt vóór het humanizen:
- Vraag: “Ben je AI-tekst aan het fixen of je eigen tekst aan het polijsten?”
Dat helpt je te begrijpen of Clever AI Humanizer wordt gezien als “AI-reparateur” of “editor”, wat belangrijk is voor de roadmap.
- Vraag: “Ben je AI-tekst aan het fixen of je eigen tekst aan het polijsten?”
Geen grote modals, geen “geef ons 5 sterren”, alleen kleine contextbewuste zetjes.
8. Hoe concurrenten in je mentale model passen
Je hebt al goed vergelijkingswerk van mensen als @kakeru en de detector-zwaardere review van @mikeappsreviewer. Gebruik ze als benchmarks, maar niet als noordsterren.
Zie anderen als:
- “Dit is wat er gebeurt als je detector-ontwijking maximaal opendraait en stem negeert.”
- “Dit is wat er gebeurt als je licht parafraseert en veilig blijft maar detecteerbaar.”
Het voordeel van Clever AI Humanizer zit nu in de balans tussen leesbaarheid en detectie. Je volgende voordeel zou personalisatie en controle moeten zijn, niet alleen lagere percentages op weer een nieuwe publieke detector.
Als je één concreet ding wilt bouwen dat je deze week kunt lanceren én dat het product verbetert én je echte signalen uit de praktijk geeft:
- Voeg twee toggles toe vóór het humanizen:
- “Structuur zo veel mogelijk behouden”
- “Structuur veranderen voor meer menselijke variatie”
Log vervolgens welke toggle-combinatie correleert met:
- Hogere kopieerratio
- Minder regeneraties
- Meer terugkerende sessies
Je weet dan heel snel welk soort “humanization” je daadwerkelijke gebruikers echt willen, in plaats van te gokken op basis van detectorgrafieken.