Jag har byggt ett smart AI-humaniseringsverktyg som ska få AI-genererad text att låta mer naturlig och autentisk, men jag har svårt att få ärlig feedback från riktiga användare. Jag vill veta hur det fungerar i verklig användning: låter det faktiskt mänskligt, är det pålitligt för innehållsskrivning och SEO, och var brister det eller känns uppenbart AI-genererat? Jag behöver detaljerad, praktisk feedback så att jag kan rätta till problem, förbättra kvaliteten och säkerställa att det är säkert och tillförlitligt för bloggare, marknadsförare och vanliga användare som vill ha AI-innehåll som låter mänskligt.
Clever AI Humanizer: Min faktiska upplevelse, med bevis
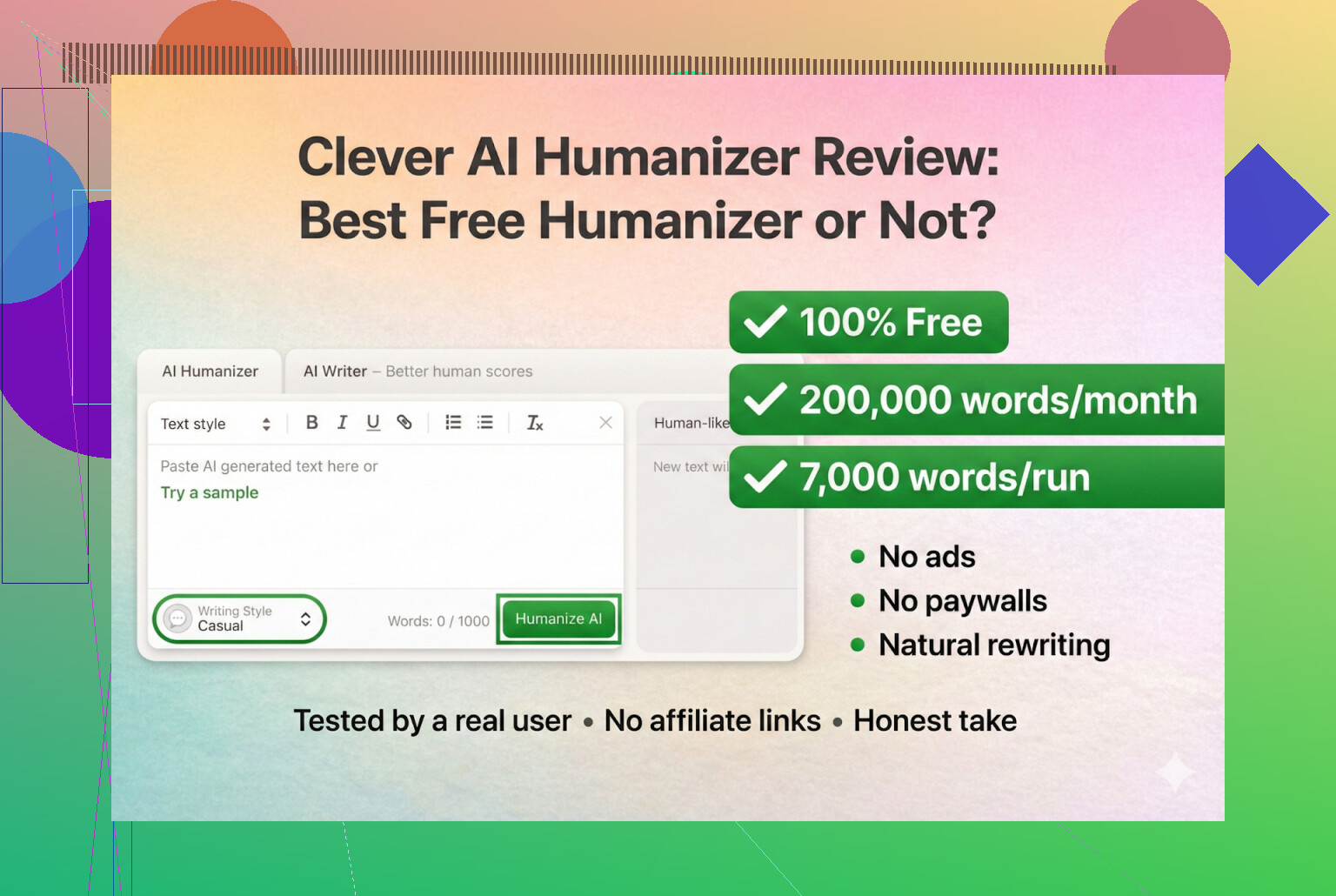
Jag har lekt runt med en massa olika AI humanizer‑verktyg på sistone, mest för att jag hela tiden såg folk på Discord och Reddit fråga vilka som fortfarande fungerar. Många har antingen slutat funka, blivit betalda SaaS över en natt eller bara tyst blivit sämre.
Så jag bestämde mig för att börja med verktyg som faktiskt är gratis, utan inloggning och utan kreditkort. Först på listan: Clever AI Humanizer.
Du hittar det här:
Clever AI Humanizer — Bästa 100 % gratis humanizer
Så långt jag kan se är det den riktiga, inte en klon och inte någon konstig rebrand.
URL‑förvirring och fejkade kopior
En liten varning, eftersom jag själv åkte dit en gång: det finns en massa “AI humanizer”-sajter som använder liknande namn och köper annonser på samma sökord. Några personer DM:ade mig och frågade “vilken är den riktiga Clever AI Humanizer?” eftersom de hamnat på någon helt annan sida som försökte ta betalt för “pro”-funktioner.
För tydlighetens skull:
- Själva Clever AI Humanizer (Clever AI Humanizer — Bästa 100 % gratis humanizer)
- Så långt jag har sett:
- Inga premium‑nivåer
- Inga prenumerationer
- Inga popups som “lås upp 5 000 fler ord för 9,99 $”
Om du klickade på något från Google Ads och såg ditt kreditkort börja pingas, då var det inte det här verktyget.
Så testade jag det (helt AI mot AI)
Jag ville se hur långt det här verktyget klarar sig i ett värsta‑fall‑scenario, så jag gav det ingen specialbehandling alls.
- Bad ChatGPT 5.2 skriva en helt AI‑genererad artikel om Clever AI Humanizer.
- Inga mänskliga redigeringar.
- Rak copy‑paste.
- Tog den texten och körde den genom Clever AI Humanizer i läget Simple Academic.
- Körde resultatet genom flera AI‑detektorer.
- Bad sedan ChatGPT 5.2 bedöma den omskrivna texten själv.
På det sättet finns ingen “men grundtexten var ju redan ganska mänsklig”-ursäkt. Det är 100 % maskin till maskin.
Simple Academic‑läget: varför jag valde det svåraste
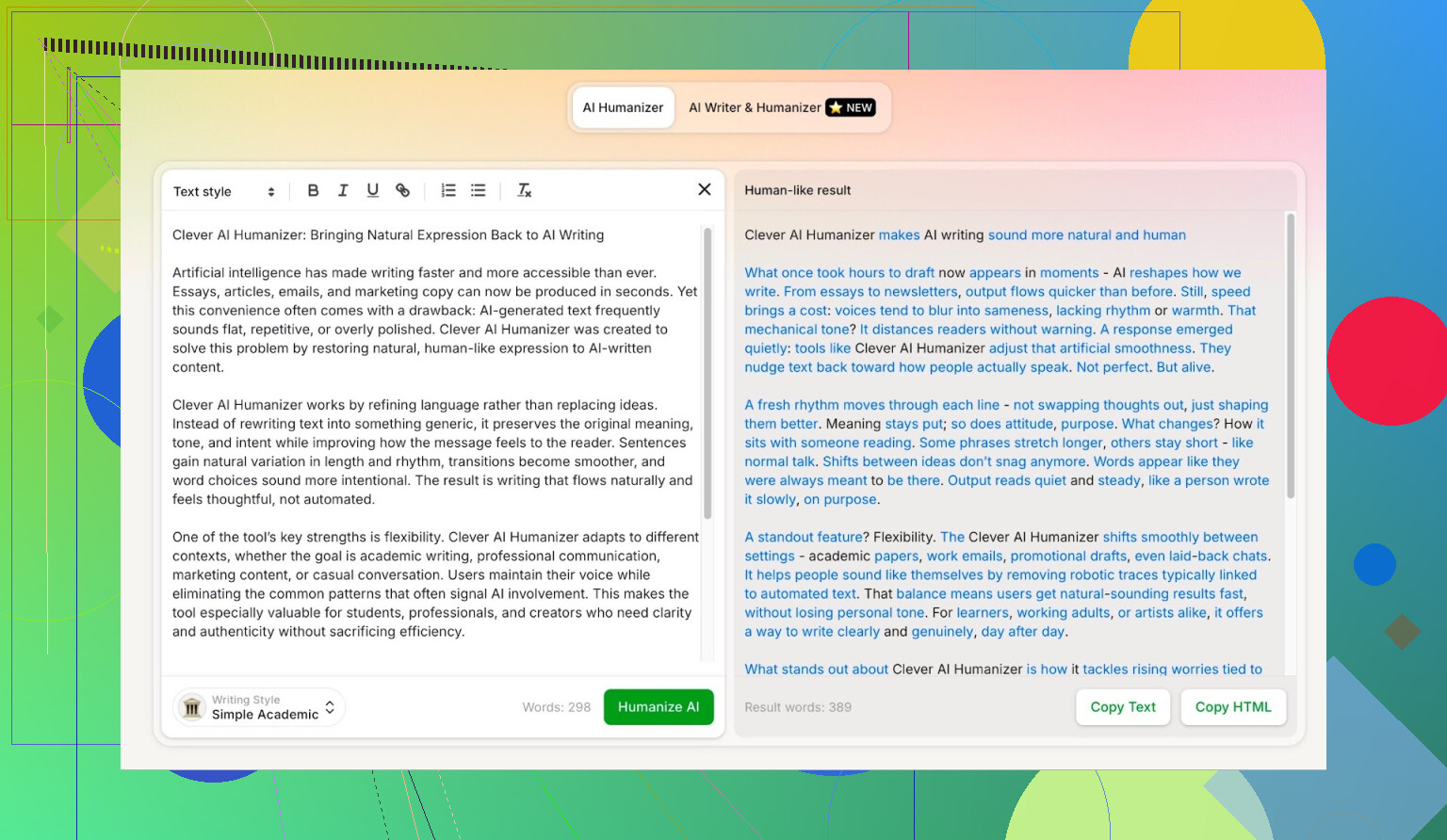
Jag valde inte Casual eller Blog‑stil eller något mjukt. Jag gick direkt på Simple Academic.
Hur det läget känns i praktiken:
- Fortfarande lättläst, inte full akademisk tidskriftsjargong
- Ganska formellt, strukturerat och prydligt
- Lagom mycket “akademiskt” språk för att låta seriöst, men inte som en avhandling
Just den här mittzonen är ofta där AI‑detektorer börjar skrika “AI!” eftersom meningarna blir för prydliga och balanserade. Så om en humanizer klarar den stilen och ändå får bra poäng, är det intressant.
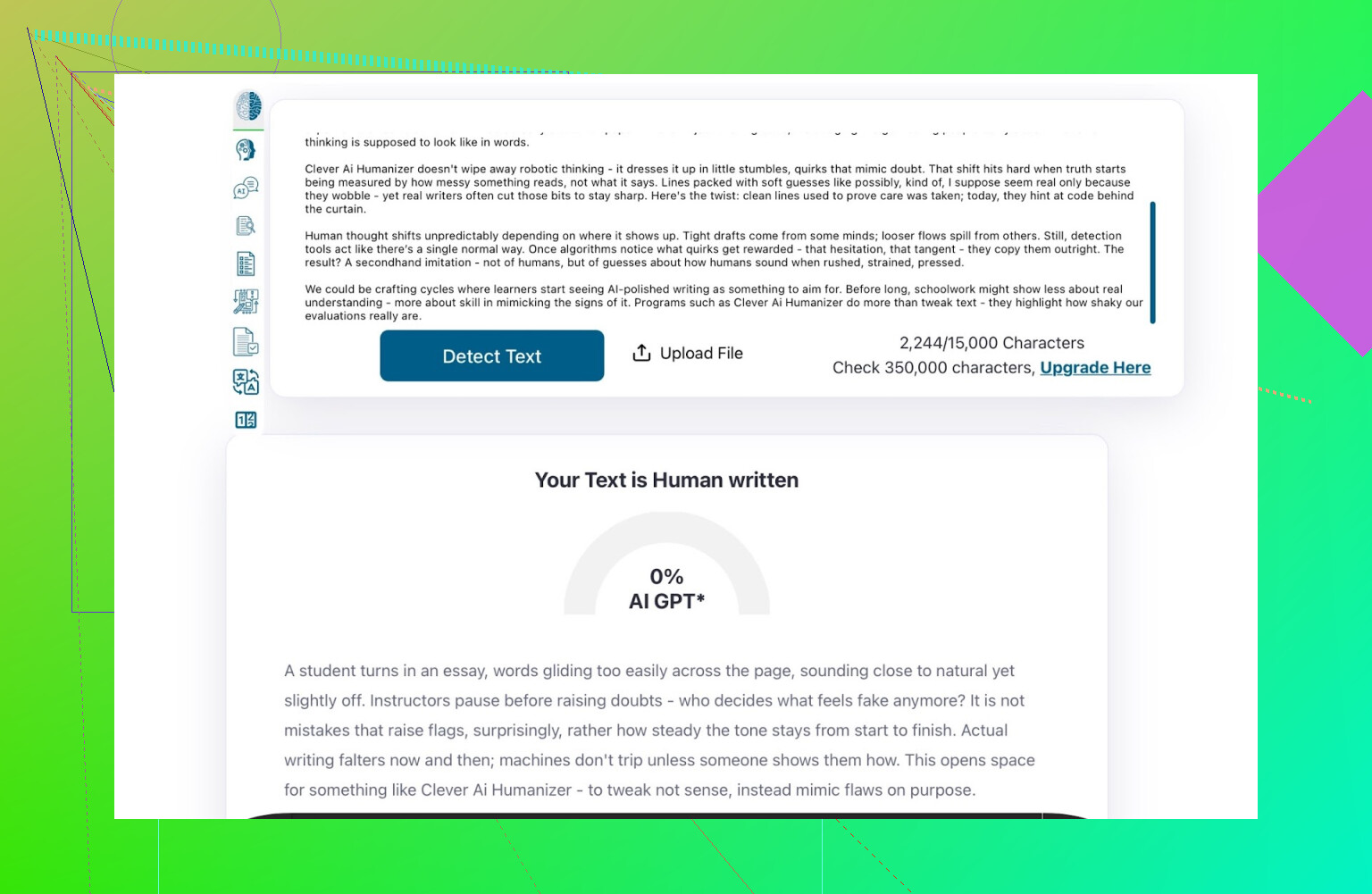
ZeroGPT: testet “jag litar inte på det, men alla använder det”
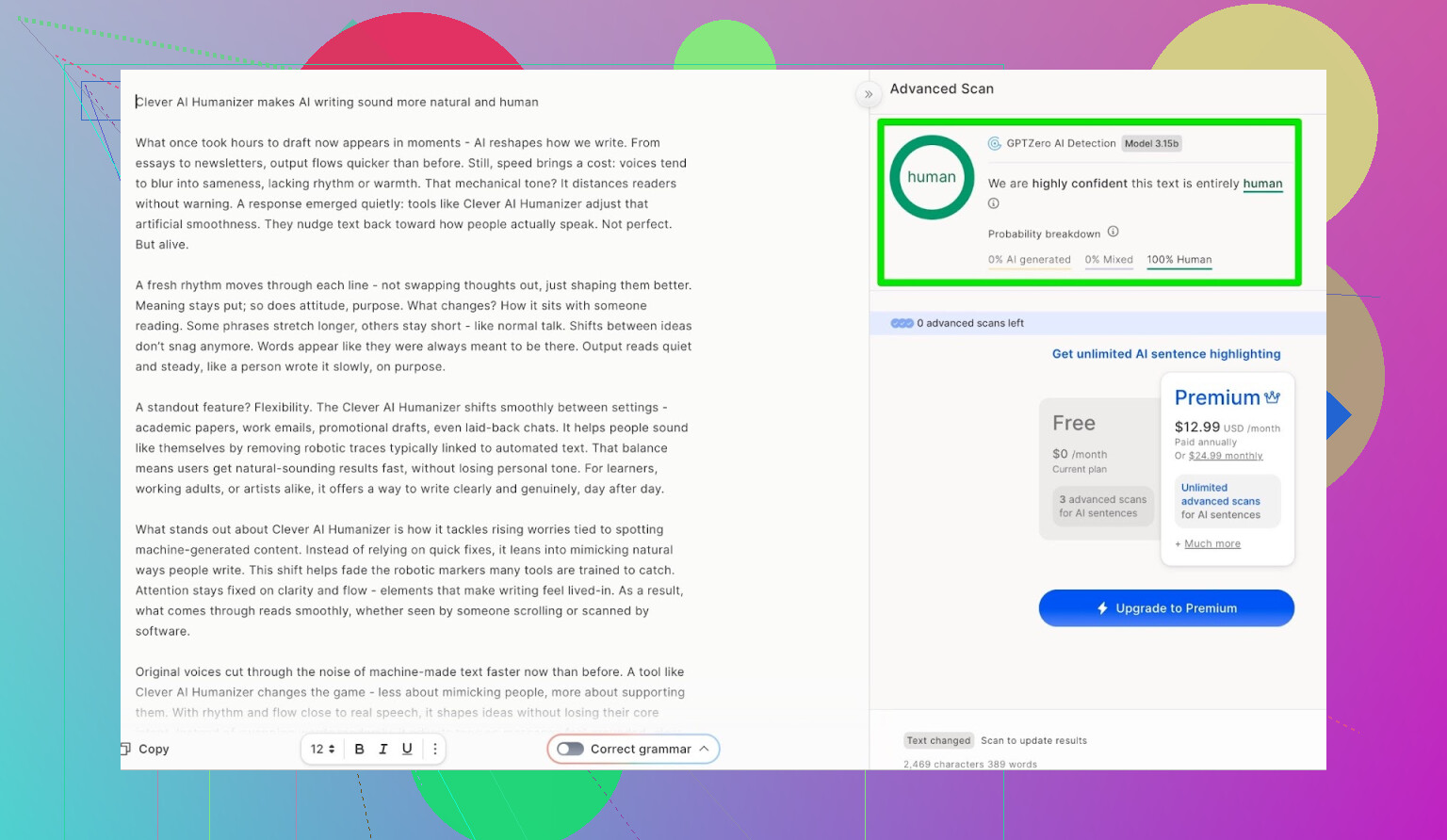
Jag är inget fan av ZeroGPT av en huvudorsak: det flaggar USA:s konstitution som “100 % AI”.
När man sett det går förtroendet rakt neråt.
Med det sagt:
- Det dyker fortfarande upp överallt på Google.
- Folk fortsätter använda det eftersom det är ett av de första resultaten.
- Så jag tog med det.
Resultatet för texten från Clever AI Humanizer:
ZeroGPT: 0 % AI upptäckt.
För vad det är värt: mycket bättre än så blir det inte i det verktyget.
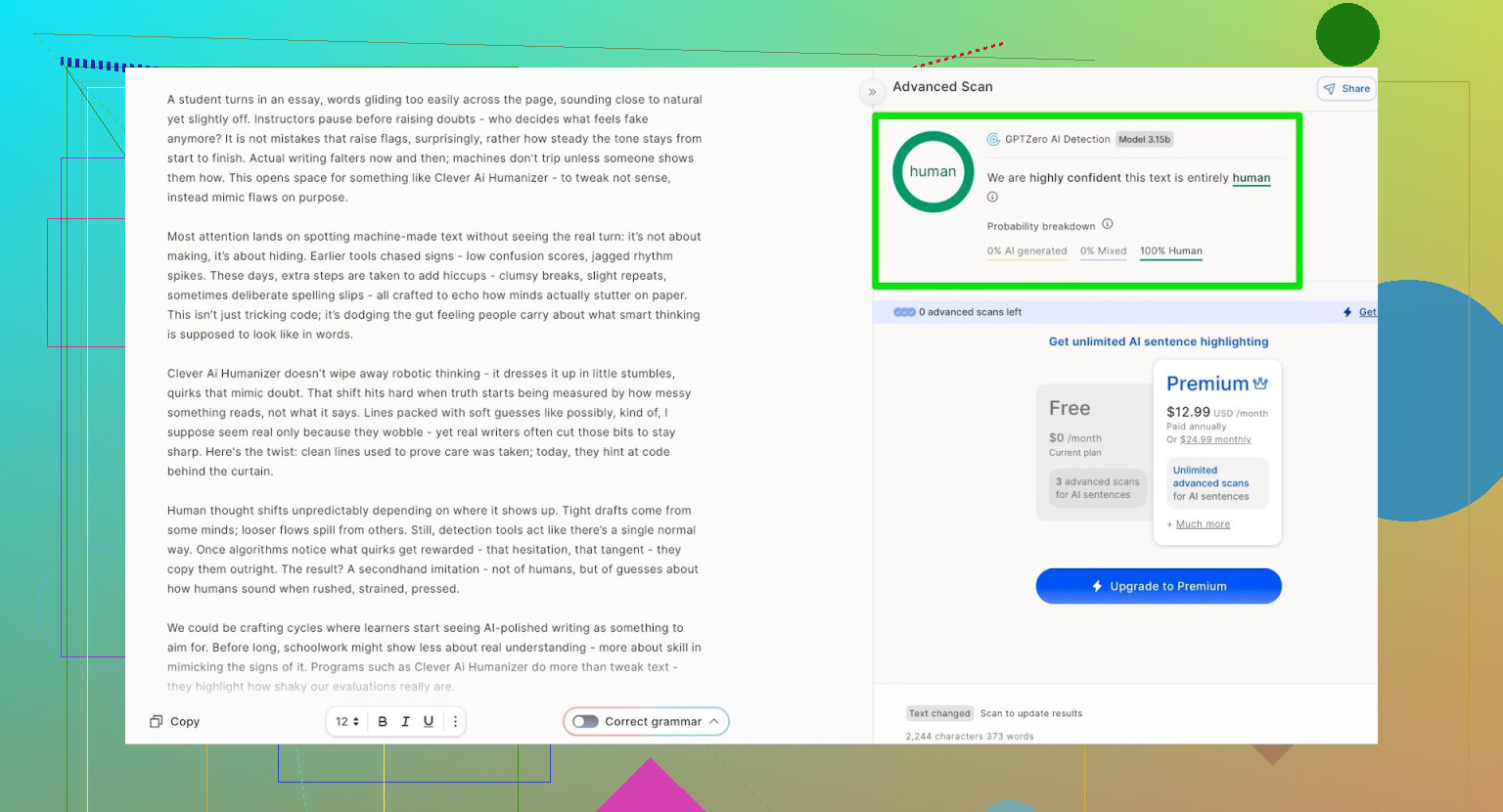
GPTZero: andra åsikt, samma resultat
Nästa var GPTZero.
Det här används flitigt på skolor och universitet, så det är ofta det verktyg många är mest rädda för.
Utdata från Clever AI Humanizer (Simple Academic‑läge) kom tillbaka som:
- 100 % mänskligt skrivet
- 0 % AI
Så på de två mest använda offentliga detektorerna klarade texten sig med perfekta resultat.
Men känns det som skräp när man läser?
Här faller många humanizers:
De klarar detektorer, men texten känns som om någon kört din uppsats genom 4 översättningsappar och tillbaka.
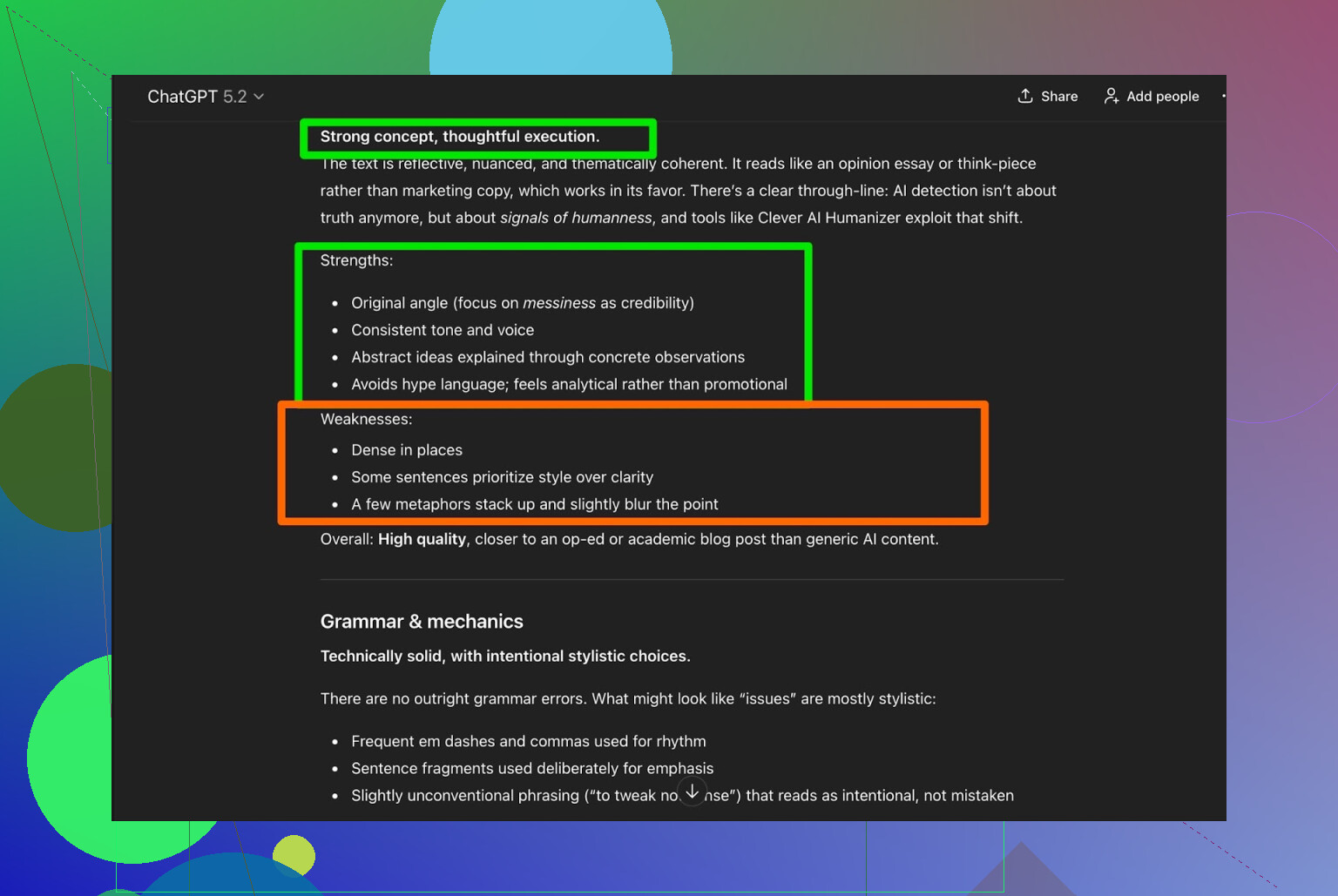
Jag tog texten från Clever AI Humanizer och bad ChatGPT 5.2 analysera den:

Allmän bedömning:
- Grammatik: stabil
- Stil: passar Simple Academic ganska bra
- Rekommendation: säger fortfarande att en mänsklig genomläsning rekommenderas
Ärligt talat håller jag med. Det är bara verkligheten:
All text som är skriven eller “humaniserad” av AI mår bättre av att en människa läser igenom den.
Om ett verktyg påstår “ingen mänsklig redigering behövs” är det troligen marknadsföring, inte sanning.
Test av AI‑skrivaren inbyggd i Clever AI Humanizer
De har ett separat verktyg här:
https://aihumanizer.net/svai-writer
Det här är där det blir mer intressant. I stället för:
LLM → Kopiera → Klistra in i Humanizer → Hoppas på det bästa
Kan du:
- Generera och humanisera i ett steg
- Låta deras system styra både struktur och stil från början
Det spelar roll eftersom ett verktyg som själv genererar innehållet kan forma det på ett sätt som naturligt undviker en del väldigt tydliga AI‑mönster.
För testet:
- Valde jag Casual skrivstil
- Ämne: AI‑humanisering, med omnämnande av Clever AI Humanizer
- Lade medvetet in ett litet fel i prompten för att se hur det hanterades
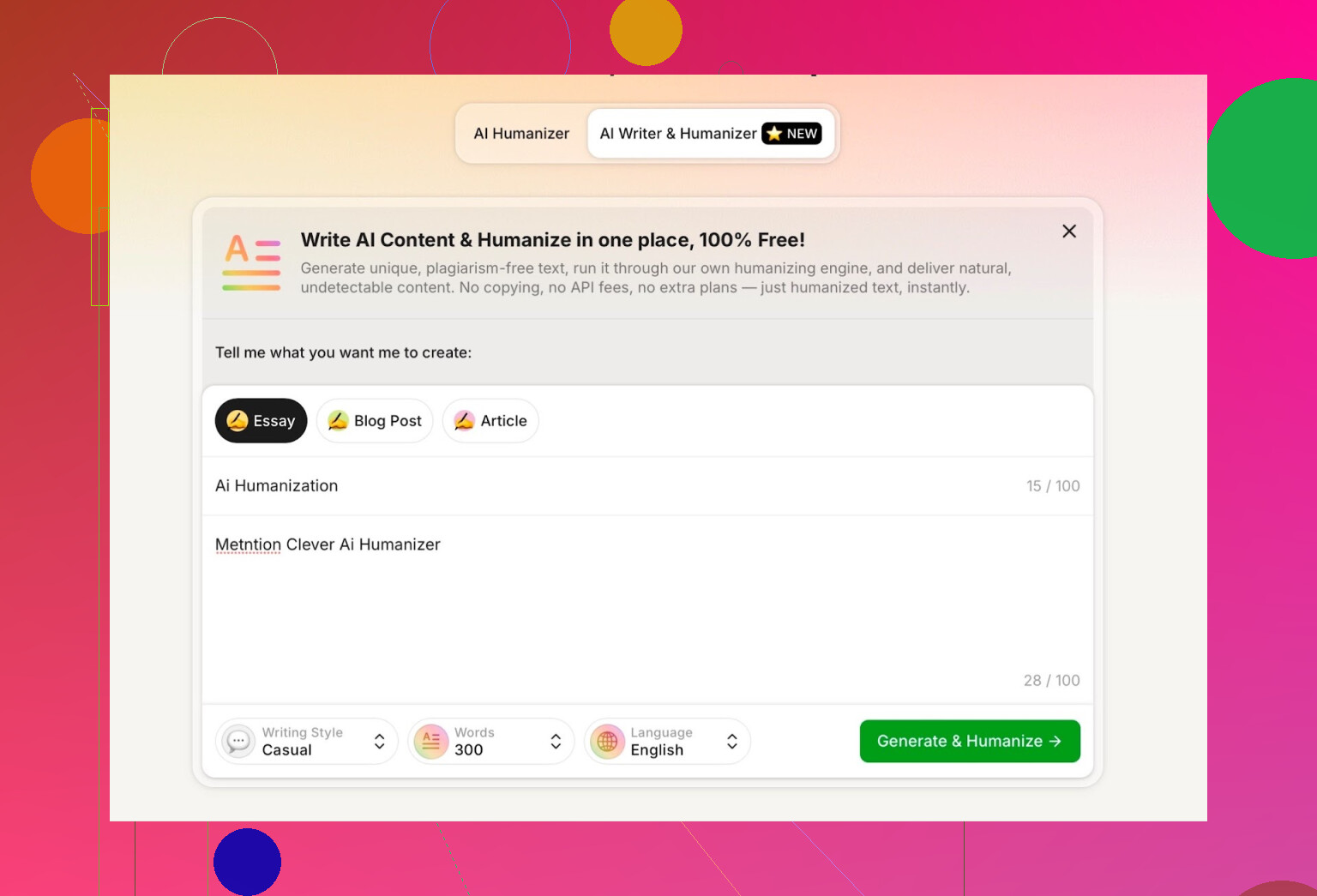
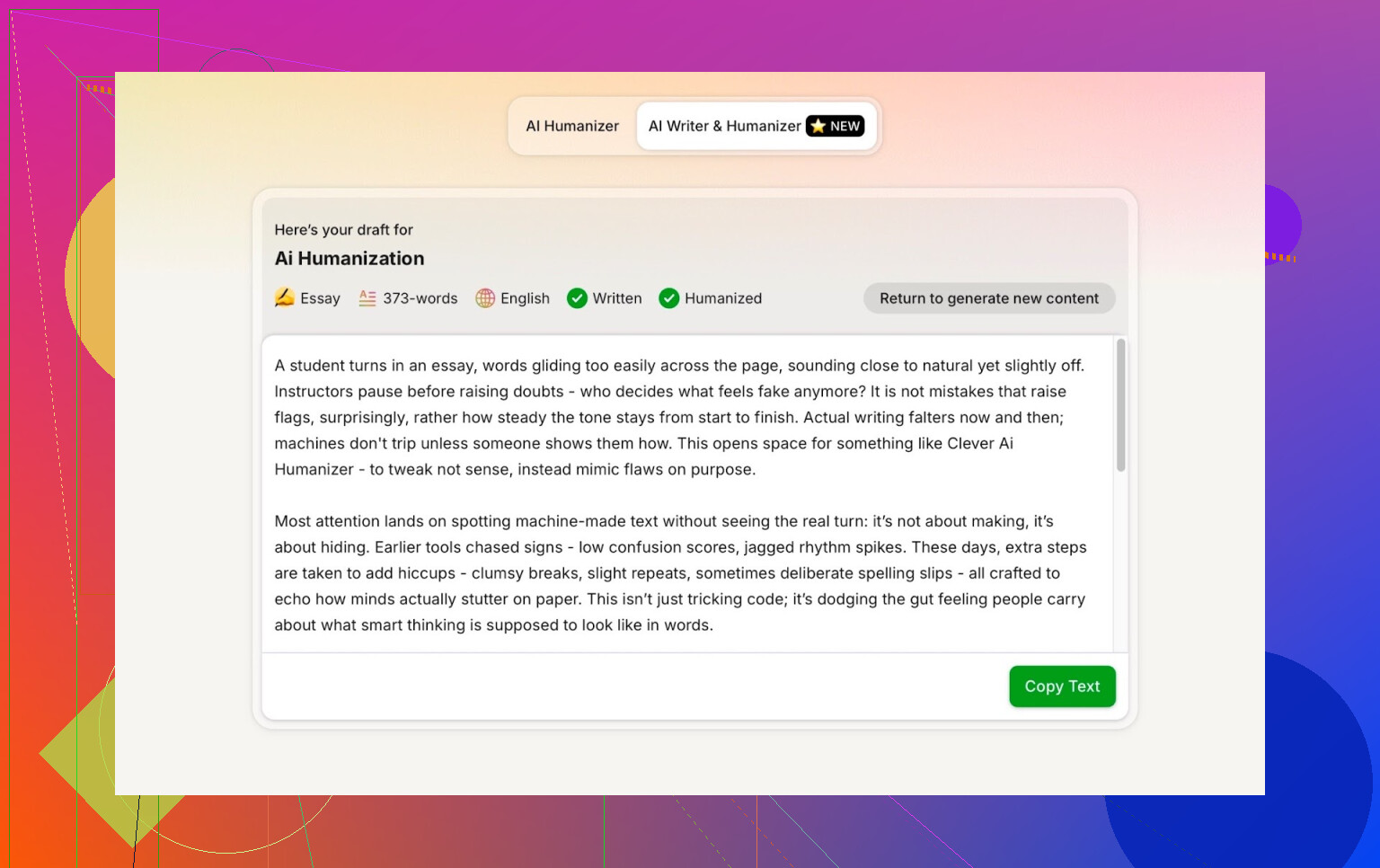
Resultatet var rent, samtalstonat och tog inte med mitt stavfel på något konstigt sätt.
En sak jag inte gillade:
- Jag bad om 300 ord
- Jag fick mer än 300
Om jag säger 300 vill jag ha 300. Inte 412. Sånt spelar roll om du har hårda gränser i uppgifter eller innehållsbriefar.
Det är min första riktiga invändning mot det.
Detektionsresultat för utdata från AI‑skrivaren
Jag tog texten som AI Writer producerade och körde den genom:
- GPTZero
- ZeroGPT
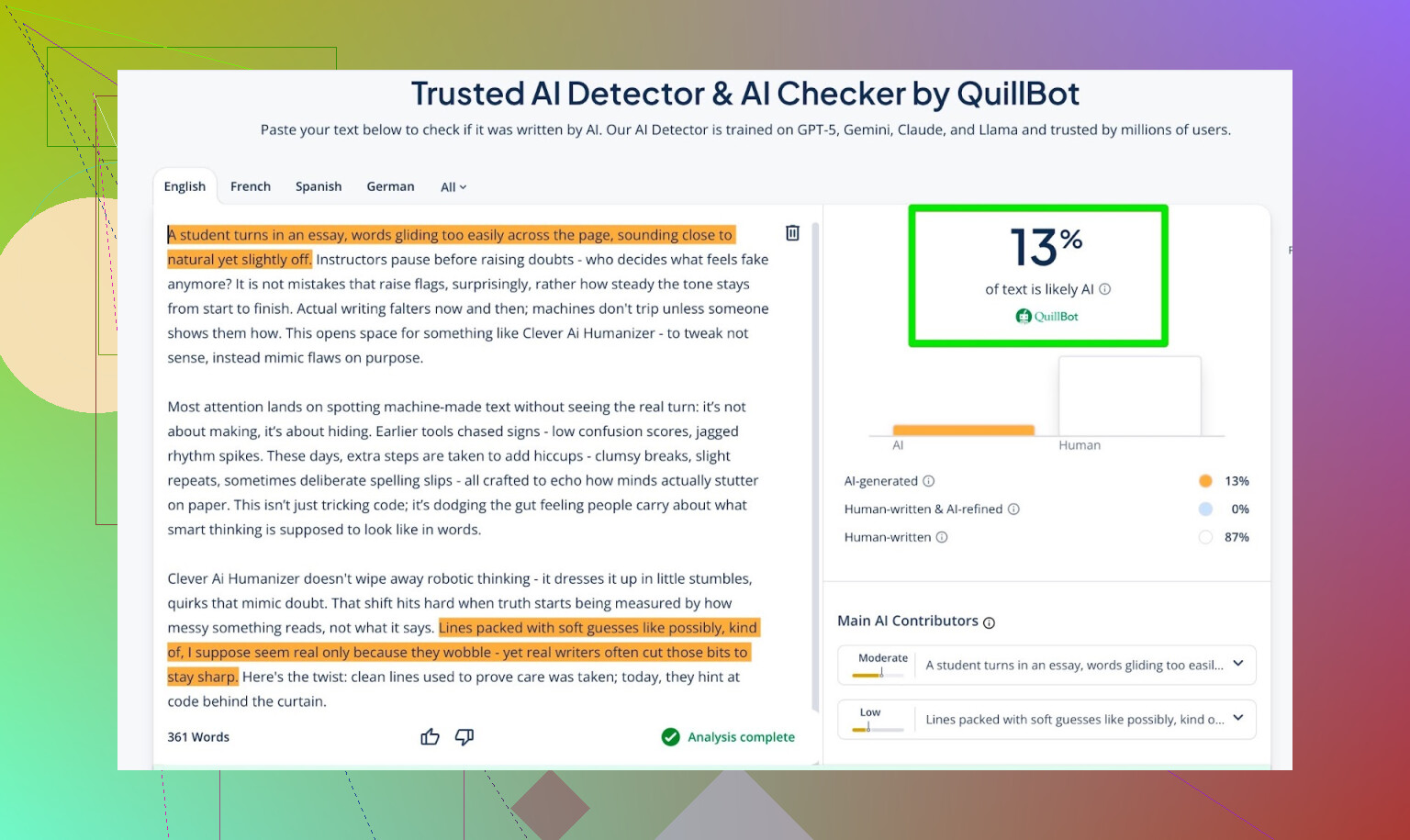
- QuillBot detector som en extra datapunkt
Resultat:
- GPTZero: 0 % AI
- ZeroGPT: 0 % AI, 100 % mänsklig
- QuillBot: 13 % AI
Så QuillBot såg en liten del “AI‑likt” mönster, men fortfarande mest mänskligt.
Överlag är det ganska bra.
Att låta ChatGPT 5.2 bedöma texten från AI‑skrivaren
Nu till den del jag egentligen brydde mig om: inte bara “lurar det detektorer”, utan:
- Låter det som en person?
- Håller det konsekvent ton och stil?
- Flyter det naturligt?
Jag skickade tillbaka texten från AI Writer till ChatGPT 5.2 och frågade om den verkade mänskligt eller AI‑skriven.
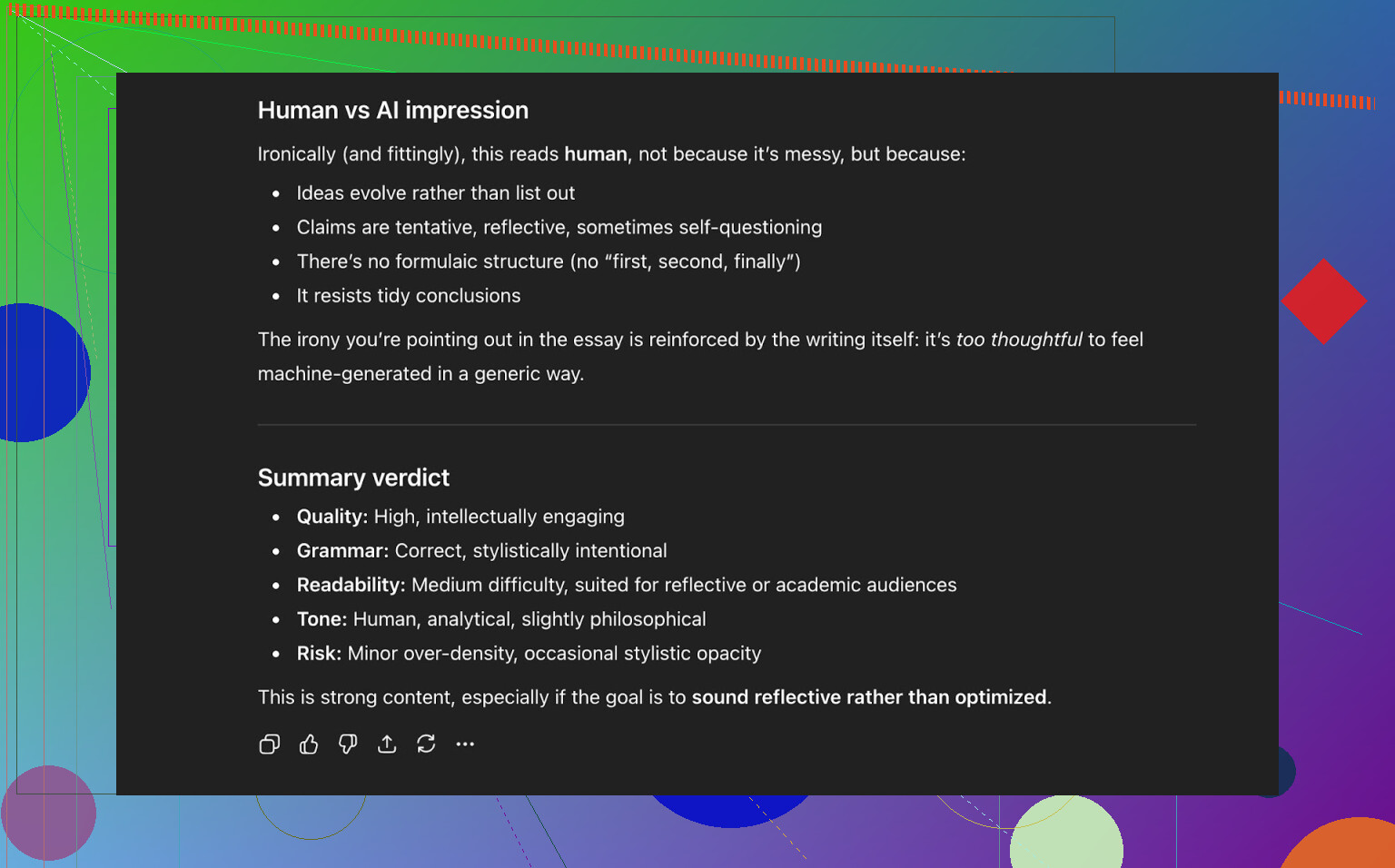
Slutsats från ChatGPT 5.2:
- Läser som mänskligt skriven
- Kvaliteten är stark
- Inget uppenbart fel i grammatik eller struktur
Så vid det här laget hade texten:
- Klarat tre offentliga AI‑detektorer snyggt
- Också “lurat” en modern LLM att klassa den som mänskligt skriven
Hur den står sig mot andra humanizers jag testat
I mina egna tester presterade Clever AI Humanizer bättre än en rad andra verktyg som folk ofta nämner.
Här är en snabb översiktstabell från de körningarna:
| Verktyg | Gratis | AI‑detektorpoäng |
| ⭐ Clever AI Humanizer | Ja | 6 % |
| Grammarly AI Humanizer | Ja | 88 % |
| UnAIMyText | Ja | 84 % |
| Ahrefs AI Humanizer | Ja | 90 % |
| Humanizer AI Pro | Begränsad | 79 % |
| Walter Writes AI | Nej | 18 % |
| StealthGPT | Nej | 14 % |
| Undetectable AI | Nej | 11 % |
| WriteHuman AI | Nej | 16 % |
| BypassGPT | Begränsad | 22 % |
Verktyg det slog i mina faktiska tester:
- Grammarly AI Humanizer
- UnAIMyText
- Ahrefs AI Humanizer
- Humanizer AI Pro
- Walter Writes AI
- StealthGPT
- Undetectable AI
- WriteHuman AI
- BypassGPT
För att vara tydlig: tabellen bygger på detektorpoäng, inte på “vilket som låter trevligast subjektivt”.
Där Clever AI Humanizer fortfarande brister
Det är inte magi och det är inte felfritt.
Några saker jag märkte:
- Dålig kontroll på ordantal
- Ber du om 300 ord kan du få 280 eller 370.
- Mönster kan fortfarande dyka upp
- Vissa LLM:er kan ibland fortfarande flagga delar som AI‑lika.
- Innehållsdrift
- Det speglar inte alltid originalet exakt; ibland blir omskrivningen mer aggressiv än väntat.
På plussidan:
- Grammatikkvalitet: runt 8–9/10 i mina körningar
- Flyter tillräckligt bra för att du inte snubblar på formuleringar hela tiden
- Inga störande “avsiktliga stavfel” som att skriva “i was” i stället för “I was” för att försöka lura detektorer
Den sista punkten spelar roll. Vissa verktyg lägger in misstag bara för att framstå mer mänskliga. Det kan ge bättre detektorresultat, men gör texten sämre.
Det märkliga: 0 % AI känns inte alltid “mänskligt”
Det finns något subtilt som är svårt att beskriva: även när en text får 0 % AI i flera detektorer kan man ibland känna att den är maskinformad. Rytmen, hur idéer introduceras, hur prydligt allt är.
Clever AI Humanizer gör ett bättre jobb än de flesta, men det underliggande mönstret finns ibland ändå där. Det är egentligen ingen direkt kritik mot verktyget; det är bara där hela ekosystemet befinner sig just nu.
Det är bokstavligen katt‑och‑råtta:
- Detektorer blir smartare
- Humanizers anpassar sig
- Detektorer uppdateras igen
- Upprepa
Om du förväntar dig att något verktyg ska vara “framtidssäkert” kommer du bli besviken.
Så, är det “det bästa” gratis humanizer‑verktyget just nu?
För gratis verktyg jag faktiskt har testat med detektorer och LLM‑kontroller:
- Skulle jag just nu sätta Clever AI Humanizer överst.
- Särskilt om man tar hänsyn till att det både har:
- En humanizer för befintlig text
- En inbyggd AI Writer som humaniserar medan den skriver
Du behöver fortfarande:
- Läsa igenom texten själv
- Rätta sådant som känns fel
- Justera tonen så att den låter som du
Men om din fråga är:
“Är Clever AI Humanizer värt att testa just nu, särskilt när det är gratis?”
Så baserat på mina tester: ja.
Extra om du vill nörda ner dig mer
Det finns några diskussioner och tester på Reddit med fler skärmdumpar och bevis:
-
Allmän jämförelse av AI‑humanizers med detektionsresultat:
https://www.reddit.com/r/DataRecoveryHelp/comments/1oqwdib/best_ai_humanizer/?tl=sv -
En specifik recensionstråd om Clever AI Humanizer:
https://www.reddit.com/r/DataRecoveryHelp/comments/1ptugsf/clever_ai_humanizer_review/?tl=sv
Om du bestämmer dig för att testa Clever AI Humanizer skulle jag ändå se det som:
- Ett hjälpmedel, inte en ersättare
- Något som tar dig 70–90 % av vägen
- Ett verktyg som bara är så bra som människan som granskar slutresultatet
Du måste fortfarande vara den som står för orden.
Kort svar: du kommer inte att få den sortens ärlig feedback från verkliga användare du vill ha bara genom att titta på detectorsiffror eller fråga andra AI:er vad de tycker. Det är en del av bilden, men också den lataste delen.
Du har redan sett att @mikeappsreviewer körde detector-OS och strukturerade tester. Användbart, men det säger fortfarande inte hur ditt verktyg känns för någon som är trött klockan ett på natten och försöker bli klar med en uppsats, eller för en content manager som batchbearbetar 20 artiklar och är nära att säga upp sig.
Om du vill ha signal från verkligheten, gör sånt här:
-
Bädda in feedback i användningsögonblicket
- Efter varje körning: mikroundersökning med 3 klick:
- “Lät: [För robotaktigt] [Ganska naturligt] [Väldigt mänskligt]”
- “Var den här texten säker att lämna in som den är? [Ja/Nej]”
- Sedan en pytteliten frivillig textruta: “Vad irriterade dig?”
- Fråga inte “Vad gillade du?” Det är så du får falskt beröm. Fråga vad som var dåligt.
- Efter varje körning: mikroundersökning med 3 klick:
-
Följ beteende, inte bara åsikter
- Mät:
- Hur ofta användare trycker på “generera om”
- Hur ofta de direkt börjar redigera texten i din editor (om du har en)
- Avhopp mitt i sessioner
- Om folk genererar om 3–4 gånger per inmatning, säger verktyget till dig att det misslyckas, även om enkäterna ser positiva ut.
- Mät:
-
Kör riktade tester med riktiga användare istället för slumptrafik
Ta små, specifika grupper i stället för “internet”:- Studenter som försöker undvika AI‑flaggor
- Frilansskribenter/contentbyråer
- Icke modersmålstalare i engelska som finslipar texter
Erbjud dem: - Ett privat testutrymme
- Ett par fasta uppgifter (skriv om essäinledning, putsa LinkedIn‑inlägg osv.)
- Ett 10–15 minuters samtal eller skärminspelad session för varje
Mutor med presentkort, gratis premiumanvändning, vad som helst. Den kvalitativa feedback du får från 20 sådana personer slår 2 000 anonyma klick.
-
A/B‑testa ditt eget verktyg mot en baslinje
I stället för att fråga “Är det här bra?” fråga “Är det här bättre än X?”
Du kan i smyg köra:- Version A: rå LLM‑text
- Version B: din humaniserade text
Visa dem blint för testare och fråga: - “Vilken låter mest som att en verklig människa skrev den?”
- “Vilken skulle du faktiskt lämna in/posta?”
Du behöver inte ens nämna detectors här.
-
Använd “fientliga” granskare med flit
Hitta personer som hatar AI‑innehåll eller är superpetiga redaktörer.
Säg till dem:- “Föreställ dig att en junior skribent gav dig det här. Säg exakt vad som är fel.”
Deras kommentarer om ton, upprepningar, stelhet och logisk struktur är mycket mer värdefulla än “ZeroGPT säger 0 % AI”.
- “Föreställ dig att en junior skribent gav dig det här. Säg exakt vad som är fel.”
-
Dogfooda det offentligt, men ärligt
Använd din egen Clever AI Humanizer‑text på:- Produktens webbplatscopy
- Release notes
- Blogginlägg
Lägg sedan till en liten rad längst ner:
“Det här inlägget skrevs med Clever AI Humanizer och lätt redigerat av en människa. Kändes något konstigt? Berätta för oss.”
Du får brutal, ofiltrerad feedback från människor som bryr sig tillräckligt för att klaga. -
Testa misslyckanden, inte bara bästa fall
De flesta verktyg ser okej ut på prydlig, formell text. Du borde testa:- Kaotiska prompts
- Bruten engelska
- Slang, emojis, konstig formatering
- Superkorta saker som ämnesrader i mejl
Fråga användare: - “Var misslyckades den totalt?”
Logga och kategorisera de misstagen.
-
Var uppmärksam på vibe‑problemet
Även när detectors visar 0 % AI känns mycket text fortfarande maskinformad: samma rytm, prydlig styckeindelning, förutsägbara övergångar.
Det upptäcker du inte med detectors.
Du upptäcker det om du:- Frågar användare: “Låter det här som du?”
- Låter dem klistra in “före” och “efter” och sedan fråga vilken de faktiskt skulle skicka till sin chef eller lärare.
-
Överfokusera inte på att lura detectors
Jag håller delvis inte med detector‑fokuset från @mikeappsreviewer här: användare tror att de vill ha “0 % AI”, men på sikt är det som får dem att stanna:- Det matchar deras ton
- Det hittar inte på saker
- Det får dem inte att låta som en konstig generisk bloggare
Sätt UX först, “oodetekterbarhet” sen. Annars fastnar du i en katt‑och‑råtta‑lek du till slut kommer att förlora.
-
Lägg till en brutalt ärlig kvalitetsmätare för dig själv
Internt, tagga varje körning (anonymiserad) med:
- Detectorsiffror
- Mänskligt betyg (från en liten panel du litar på)
- Användarfeedback (irritationsanteckningar)
Gå varje månad igenom dina sämsta 5–10 % av utdata. Det är där guldet finns.
Om du vill ha ett konkret nästa steg:
- Sätt upp en liten betatestarsida på Clever AI Humanizer.
- Begränsa den till, säg, 50 verkliga användare.
- Ge dem en tydlig deal: “Använd det gratis, men du måste skicka 3 exempel per vecka på där det var dåligt eller kändes fel.”
Du har egentligen inte brist på användare. Du har brist på strukturerad, smärtsam feedback. Bygg kanalerna för det, så lär du dig mer på två veckor än av ytterligare 20 skärmdumpar på detectordashboards.
Kort svar: skärmbilder från detektorer och AI:s egna självvärderingar är inte verklig användarfeedback, det är labbexperiment. Du är halvvägs där, men du frågar fel publik.
Några tankar som inte bara upprepar det @mikeappsreviewer och @kakeru redan tagit upp:
-
Sluta fråga om det “fungerar” och börja fråga för vem det fungerar
Just nu jagar du ungefär ett universellt svar: “Är min AI‑humanizer bra?” Det är vagt. I praktiken finns det väldigt olika användningsfall:
- Studenter som försöker undvika att bli flaggade
- Skribenter som vill göra utkast mindre robotlika
- Icke-modersmålstalare som vill låta mer naturliga i mejl
- Marknadsförare som vill behålla varumärkets ton
Ditt feedbackproblem kan vara: du släpper in alla och lyssnar inte på någon specifik grupp. Välj en eller två segment och optimera feedbackloopar kring dem.
-
Erbjud tydliga förinställningar och döm efter vilken som missbrukas mest
I stället för generiska lägen som “enkel akademisk” eller “avslappnad”, förankra dem i verkliga situationer:
- “Polering av college-uppsats”
- “LinkedIn thought leadership-inlägg”
- “Kallmejl till en chef”
- “Fixare för blogginledning”
Gör sedan:
- Spåra vilket läge som används mest
- Spåra vilket som får flest “kopiera allt” utan redigering
- Spåra vilket som användare överger mitt i flödet
Om “Polering av college-uppsats” används massor men folk lämnar efter en körning, har du specifika, åtgärdbara feldata. Det är bättre än ännu en skärmbild från en detektor.
-
Bygg in en jämförelse “Min röst vs humaniserad röst”
Här håller jag delvis inte med den tunga detektorfokuseringen från andra: på sikt bryr sig folk mer om röst än 0 % AI. Om texten slutar låta som dem kommer de att överge ditt verktyg även om det är “oodetekterbart”.
Låt användare:
- Klistra in originaltext
- Få humaniserat resultat
- Se en snabb diff-liknande sammanställning:
- “Formell ton: +20 %”
- “Personlig ton: -30 %”
- “Meningslängd: +15 %”
Fråga sedan rakt ut:
“Låter det här fortfarande som du?” [Ja / Ganska / Nej]
Den frågan ensam ger dig mer ärlig signal än “Betygsätt 1–5 stjärnor”.
-
Du behöver negativa incitament, inte bara mutor
Alla pratar om presentkort, betaförmåner osv. Problemet: folk kommer säga det du vill höra för att behålla förmånerna.
Testa detta:
- “Om du skickar oss 3 riktigt dåliga utdata (skärmbilder eller inklistrat), låser vi upp X extra krediter.”
- Du belönar inte “använder verktyget mycket”, du belönar “hittar där det misslyckas”.
Det håller fokus på dina svagheter i stället för vaga kommentarer som “ja det är bra, tack”.
-
Skapa en intern “skämmes-hall”
Du vet redan att verktyget kan prestera bra i bästa fall. Det du saknar är en kurerad hög av:
- Sämsta utdata
- Mest obekväma meningar
- Tillfällen när det ändrade betydelsen
- Tillfällen när det fick användaren att låta som en generisk AI-bloggare
En gång i veckan, plocka:
- De 50 sessionerna med flest snabba regenereringar
- De 50 med snabbast stängning efter utdata
Granska manuellt 10–20 av dem och tagga varför de var dåliga. Det mönstret är hur du förbättrar.
-
Tvinga fram friktion i en del av tratten
Du optimerar troligen för “ingen inloggning, super snabbt, minimal friktion.” Bra för trafik, uselt för feedback.
Överväg en separat “Pro-feedback-sandlåda”:
- Kräver mejl eller minimal registrering
- Ger högre gränser eller extra lägen
- I utbyte:
- Kryssar användaren i 2 rutor per utdata: “Naturligt / Robotiskt” och “På ämnet / Spårade ur”
- Klistrar eventuellt in kontext som “Jag använde detta för [skola / jobb / sociala medier]”
Personer som lägger 20 sekunder på att registrera sig är betydligt mer benägna att ge riktig feedback än slumpmässiga förbipasserande.
-
Bygg in förväntningar direkt i UI:t
En mild oenighet med den underförstådda premissen du kanske bär på: “Om det är tillräckligt bra ska användare kunna klicka kopiera och gå vidare.” Så beter sig inte människor mot den här typen av verktyg.
Lägg bokstavligen in text som:
“Detta tar dig 70–90 % av vägen. Du måste ge det en snabb mänsklig genomläsning innan du skickar in.”
Fråga sedan direkt:
- “Behövde du fortfarande redigera det här mycket?” [Lite / Mycket / I princip skrev om allt]
Det är ärlig feedback som inte kräver en lång enkät.
- “Behövde du fortfarande redigera det här mycket?” [Lite / Mycket / I princip skrev om allt]
-
Utnyttja jämförelser med konkurrenter utan att vara pinsam
Eftersom folk uppenbart också testar saker som Grammarlys humanizer, Ahrefs, Undetectable osv., kan du använda det i stället för att låtsas att de inte finns.
Lägg till en liten kryssruta:
- “Har du testat liknande verktyg (som Grammarlys eller Ahrefs AI-humanizers)?
- Ja och det här är bättre
- Ja och det här är sämre
- Ungefär samma
- Har inte testat andra”
Ingen smutskastning, inget “vi är bäst”-hype. Bara data.
Använd det för att förstå positionering, inte bara kvalitet. - “Har du testat liknande verktyg (som Grammarlys eller Ahrefs AI-humanizers)?
-
Sluta anta att framgång mot detektorer = produktsuccé
Baserat på vad @mikeappsreviewer visade är din Clever AI Humanizer redan stark mot publika detektorer. Bra. Men fråga dig själv:
- “Om alla detektorer försvann i morgon, skulle mitt verktyg fortfarande vara värt att använda?”
Om det ärligt talat är “inte riktigt”, bör din roadmap luta mer mot:
- Personalisering
- Tonkontroll
- Säkerhet (inga hallucinationer, inga osanna påståenden)
- Bevarande av ursprunglig intention
Det är sådant som överlever när kapprustningen kring detektorer svalnar.
-
Positionera Clever AI Humanizer uttryckligen som ett samarbetsverktyg
Du får mycket bättre feedback om du slutar låtsas att det är en osynlighetskappa.
Exempel i UI:t:
“Skapat av AI, finslipat av Clever AI Humanizer, färdigställt av dig.”
Det får användare att tänka:
- “Vad hjälpte det mig med?”
- “Var gjorde det mitt liv svårare?”
Fråga efter feedback i den inramningen:
- “Sparade Clever AI Humanizer tid åt dig på detta?” [Ja / Nej]
- “Ändrade det din betydelse?” [Ja / Nej]
Skärningspunkten “Ingen tid sparad” + “Ändrade min betydelse” är där du misslyckas som mest.
Om du vill ha ett väldigt praktiskt steg du kan införa på en dag:
- Efter varje utdata, visa 3 knappar:
- “Jag skulle skicka detta som det är”
- “Jag skulle använda detta men behöver redigera”
- “Detta går inte att använda”
- Om de väljer den sista, ställ en enda följdfråga:
- “För robotiskt / Utanför ämnet / Fel ton / Knackig engelska / Annat”
Det där lilla flödet, i skala, berättar mer om Clever AI Humanizers faktiska prestanda i verkligheten än ännu en månad av detektortester eller att fråga andra LLM:er om de är “lurade”.
Snabb analytisk synvinkel från en annan vinkel, eftersom andra redan har gått på djupet kring UX och testning:
1. Behandla ‘riktig feedback’ som data, inte åsikter
I stället för fler detektorexperiment, koppla in hårda mätvärden kring Clever AI Humanizer:
Kärnnummer att följa:
- Slutförandegrad: text klistrad in → humanisera → kopiera.
- Regenerationsgrad per inmatning: många regenereringar = missnöje.
- Tid till kopiering: om folk kopierar inom 2–5 sekunder läser de inte, de skördar.
- Redigeringsavsikt: klick på ‘Kopiera med formatering’ vs ‘Kopiera ren text’ vs ‘Ladda ner’. Olika mönster brukar motsvara olika användningsfall.
Det ger dig tyst feedback från varje session, inte bara från de få personer som är villiga att skriva långa texter till dig.
2. Lättviktig kohortmärkning
Andra föreslog personamålgrupper. Jag skulle göra det brutalt enkelt:
Vid första användning, en 1-klikksväljare ovanför rutan:
- ‘Använder detta för: Skola / Jobb / Socialt / Annat’
Ingen inloggning, ingen friktion. Bara spara en anonym kohorttagg.
Nu kan du se:
- Skola: högsta regenerering och avhopp
- Jobb: längst tid på sidan men hög kopieringsgrad
- Socialt: snabb kopiering, låg längd, kanske inte värt att optimera
Du gissar inte längre vilken målgrupp du misslyckas med.
3. A/B-testa ‘aggressiv vs konservativ’ humanisering
Just nu känns Clever AI Humanizer optimerad för detektorundvikande plus läsbarhet. Det är okej, men olika användare vill ha olika nivåer av redigering.
Kör ett tyst splittest:
- Version A: minimala ändringar, bevarar struktur, lätt omformulering
- Version B: tyngre omskrivning, mer variation, större rytmförändringar
Jämför sedan:
- Vilken version ger mer ‘kopiera och lämna’-beteende
- Vilken version triggar mer ‘Kör igen’-användning
Ingen enkät, inget tiggande om feedback. Beteendet är svaret.
4. För- och nackdelar som produktrealitetscheck
Jämfört med vad @kakeru och @andarilhonoturno beskrev tycker jag att ditt verktyg redan ligger i ‘bättre än genomsnittet’-facket, men det hjälper att namnge saker tydligt:
Fördelar med Clever AI Humanizer
- Stark prestanda mot vanliga AI-detektorer när det testas i realistiskt innehåll.
- Utdata läses i allmänhet rent och grammatiskt utan det tvångsmässiga ‘typo-spam’-tricket som vissa verktyg använder.
- Flera stilar (Enkel akademisk, Avslappnad osv.) som ganska väl motsvarar verkliga skrivsituationer.
- Integrerad AI-skrivare som kan generera och humanisera i ett enda steg, vilket minskar uppenbara LLM-avtryck.
- Gratis och lätt onboardning, vilket är bra för tidig adoption och ger gott om testdata.
Nackdelar med Clever AI Humanizer
- Ordantalet är svårkontrollerat, vilket är ett verkligt problem för strikta uppgifter och briefs.
- Ibland skriver den om för aggressivt och introducerar innehållsdrift som användare inte alltid upptäcker.
- Även med 0 % AI-poäng känns vissa texter fortfarande maskinformade i struktur och rytm.
- Detektorcentrerat värdeerbjudande sätter dig i ett konstant katt-och-råtta-spel och kan åldras dåligt.
- Lite uttalad röstpersonalisering, så frekventa användare kan känna att deras skrivande börjar låta likadant.
5. Sluta överanpassa till detektorer, börja överanpassa till återkommande användare
Här håller jag inte helt med den tunga detektorfokusen som syns i @mikeappsreviewers tester. Detektorskärmbilder är användbar marknadsföring, men ett skört produktmål.
Mer hållbara signaler:
- Hur många användare kommer tillbaka inom 7 dagar
- Bland återvändande användare, hur många sessioner växer i ordantal över tid (förtroendesignal)
- Hur ofta samma webbläsare / IP använder verktyget i olika sammanhang (skola + jobb, osv.)
Riktiga användare stannar inte för att en detektor sa ‘0 % AI’. De stannar för att:
- Det sparade dem tid.
- Det gjorde dem inte generade.
- Det ändrade inte vad de menade.
Optimera först för återkommande beteende, detektorpoäng i andra hand.
6. Bygg ett ‘förtroendemönster’ istället för ett ‘maskeringsmönster’
Du ska inte försöka slå varje framtida detektor. Du ska försöka vara verktyget som:
- Håller semantiken obruten.
- Låter tonen vara justerbar.
- Dokumenterar begränsningar tydligt.
En subtil UI-tilläggning som lönar sig:
- Efter utdata, visa en kort, ärlig sammanfattning som:
- ‘Betydelse bevarad: hög’
- ‘Tonförändring: måttlig’
- ‘Meningsstrukturförändring: hög’
Folk börjar lita på dig eftersom du visar hur du arbetar. Det förtroendet ger dig indirekt bättre feedback än någon enkät.
7. Hur du får kvalitativ feedback utan att tjata
Låna beteendebaserade triggers:
-
Om användaren kör 3+ regenereringar på samma inmatning:
- Visa en liten inbäddad prompt:
- ‘Får du inte det du behöver? Berätta på 5 ord.’ [liten textruta]
Det ger brutalt ärliga kommentarer som ‘för robotaktigt’, ‘ändrade mitt påstående’, ‘för ordrikt’.
- ‘Får du inte det du behöver? Berätta på 5 ord.’ [liten textruta]
- Visa en liten inbäddad prompt:
-
Om användaren lägger >40 sekunder på att redigera text i din textruta innan humanisering:
- Fråga: ‘Fixar du AI-text eller putsar du din egen text?’
Det hjälper dig förstå om Clever AI Humanizer ses som ‘AI-fixare’ eller ‘redaktör’, vilket spelar roll för din roadmap.
- Fråga: ‘Fixar du AI-text eller putsar du din egen text?’
Inga stora modaler, inget ‘betygsätt oss med 5 stjärnor’, bara små kontextmedvetna puffar.
8. Var konkurrenter passar in i din mentala modell
Du har redan bra jämförelsearbete från personer som @kakeru och den mer detektortunga recensionen från @mikeappsreviewer. Använd dem som riktmärken, men inte som nordstjärnor.
Behandla andra som:
- ‘Detta är vad som händer när du maxar detektorundvikande och ignorerar röst.’
- ‘Detta är vad som händer när du gör lätt omformulering och spelar säkert men är upptäckbar.’
Clever AI Humanizers fördel ligger i att försöka balansera läsbarhet och upptäckt. Din nästa fördel bör vara personalisering och kontroll, inte bara lägre procenttal på ännu en offentlig detektor.
Om du vill ha en konkret sak att lansera denna vecka som både förbättrar produkten och ger dig signaler från verkliga världen:
- Lägg till två reglage innan humanisering:
- ‘Bevara struktur så mycket som möjligt’
- ‘Ändra struktur för mer mänsklig variation’
Logga sedan vilken kombination av reglage som korrelerar med:
- Högre kopieringsgrad
- Färre regenereringar
- Fler återkommande sessioner
Du kommer mycket snabbt att veta vilken typ av ‘humanisering’ dina faktiska användare verkligen vill ha, istället för att gissa från detektordiagram.