Jeg har bygget et smart AI-humanizer-værktøj, der skal få AI-genereret tekst til at lyde mere naturlig og autentisk, men jeg har svært ved at få ærlig feedback fra rigtige brugere. Jeg vil gerne vide, hvordan det klarer sig i virkelig brug: lyder det faktisk menneskeligt, er det til at stole på til tekstforfatning og SEO, og hvor fejler det eller føles det tydeligt AI-skabt? Jeg har brug for detaljeret, praktisk feedback, så jeg kan rette problemer, forbedre kvaliteten og sikre, at det er sikkert og pålideligt for bloggere, marketingfolk og almindelige brugere, der ønsker AI-indhold, der lyder menneskeligt.
Clever AI Humanizer: Min faktiske oplevelse, med dokumentation
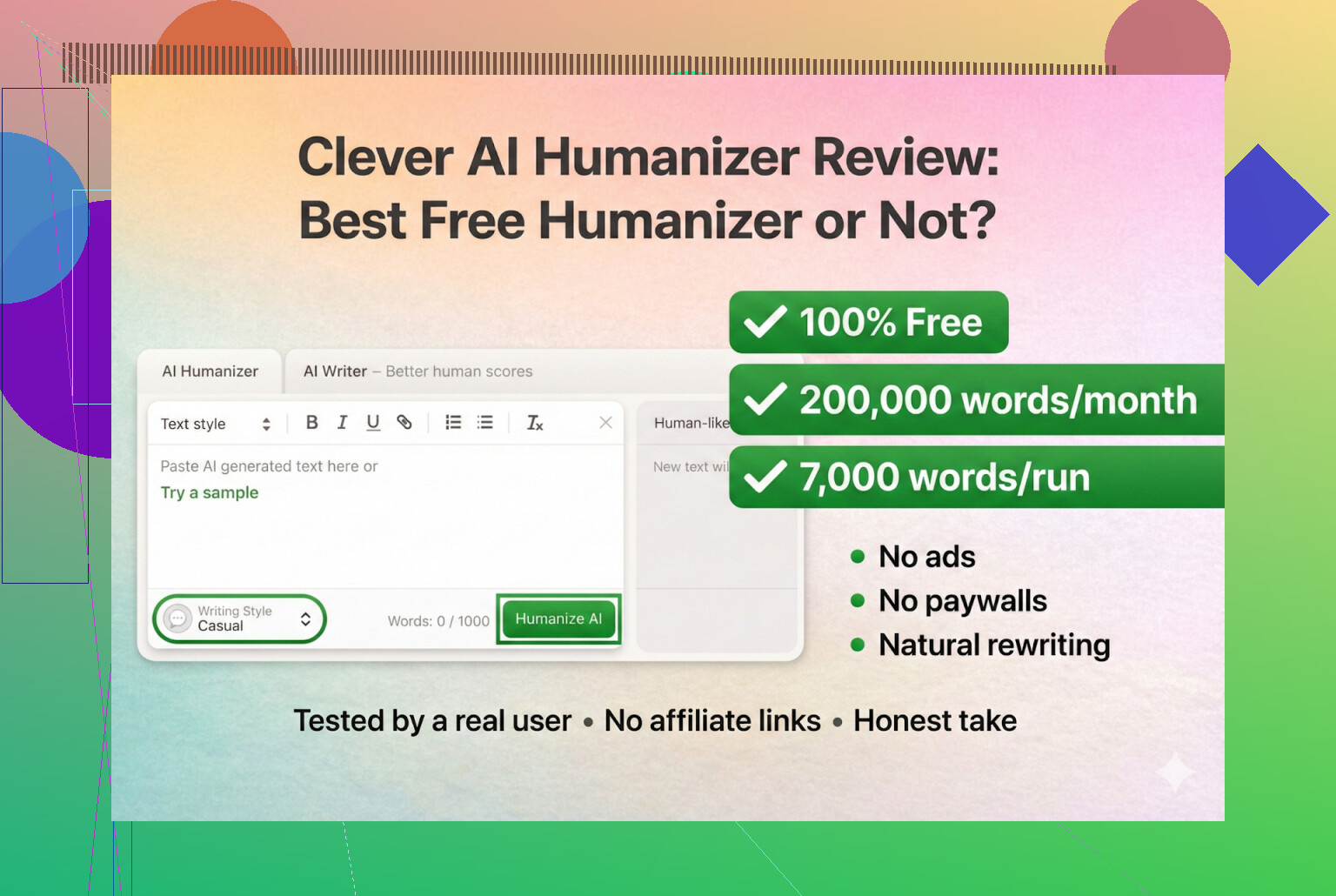
Jeg har rodet en del med forskellige “AI humanizer”-værktøjer på det seneste, mest fordi jeg hele tiden så folk på Discord og Reddit spørge, hvilke der stadig virker. Mange af dem enten brød sammen, blev til betalt SaaS fra den ene dag til den anden eller blev stille og roligt dårligere.
Så jeg besluttede at starte med værktøjer, der faktisk er gratis, uden login og uden kreditkort. Først på listen: Clever AI Humanizer.
Du kan finde det her:
Clever AI Humanizer — Best 100% Free Humanizer
Så vidt jeg kan se, er det den rigtige, ikke en kopi og ikke et mærkeligt rebrand.
URL-forvirring og falske kopier
En lille public service-meddelelse, fordi jeg selv røg i fælden én gang: der findes en masse “AI humanizer”-sites med lignende navne, som køber annoncer på de samme søgeord. Et par stykker skrev til mig og spurgte “hvilken er den rigtige Clever AI Humanizer?”, fordi de var landet på en helt anden side, der prøvede at tage betaling for “pro”-funktioner.
For at gøre det klart:
- Selve Clever AI Humanizer (Clever AI Humanizer — Best 100% Free Humanizer)
- Så vidt jeg har set:
- Ingen premium-niveauer
- Ingen abonnementer
- Ingen popups med “låst op for 5.000 flere ord for $9.99”
Hvis du klikkede på noget fra Google Ads og endte med at se dit kreditkort blive trukket, var det ikke dette værktøj.
Sådan testede jeg det (ren AI mod AI)
Jeg ville se, hvor langt det kunne gå i et worst case-scenario, så jeg skånede det ikke på nogen måde.
- Bad ChatGPT 5.2 skrive en fuld AI-artikel om Clever AI Humanizer.
- Ingen menneskelige rettelser.
- Ren copy-paste.
- Tog den tekst og kørte den gennem Clever AI Humanizer i Simple Academic-tilstand.
- Kørte resultatet gennem flere AI-detektorer.
- Bad derefter ChatGPT 5.2 selv vurdere den omskrevne tekst.
På den måde er der ingen “men måske var grundteksten allerede menneske-agtig”-undskyldning. Det er 100% maskine til maskine.
Simple Academic-tilstand: hvorfor jeg valgte den sværeste mulighed
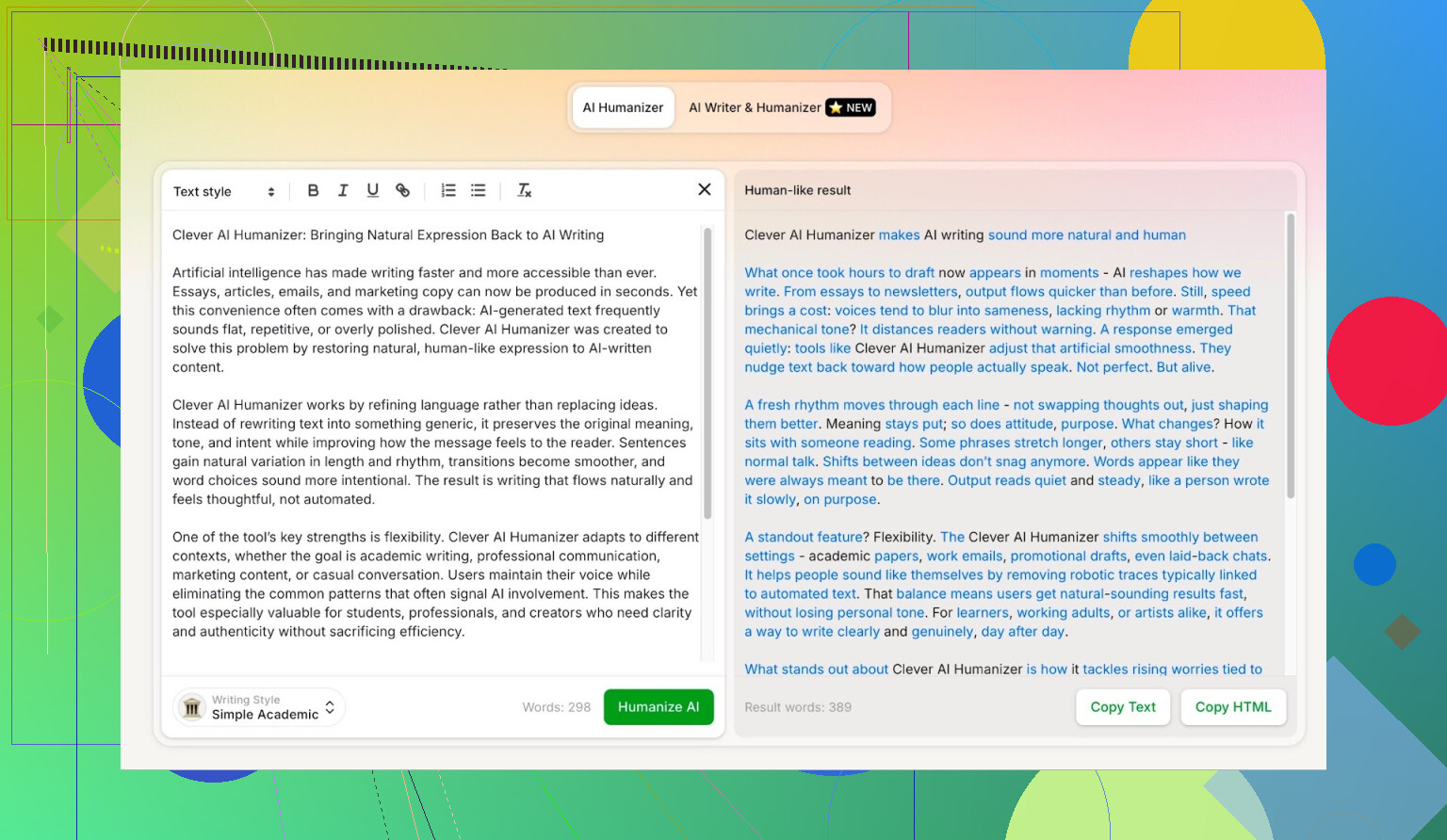
Jeg valgte ikke Casual, Blog-stil eller noget blødt. Jeg gik direkte til Simple Academic.
Hvordan den tilstand føles i praksis:
- Stadig læsbar, ikke fuld akademisk tidsskriftsjargon
- En smule formel, struktureret og ryddelig
- Nok “akademisk-agtige” vendinger til at lyde seriøs uden at være en afhandling
Lige det midterfelt er typisk dér, hvor AI-detektorer begynder at råbe “AI!”, fordi sætningerne bliver for pæne og balancerede. Så hvis en humanizer kan klare den stil og stadig score godt, er det interessant.
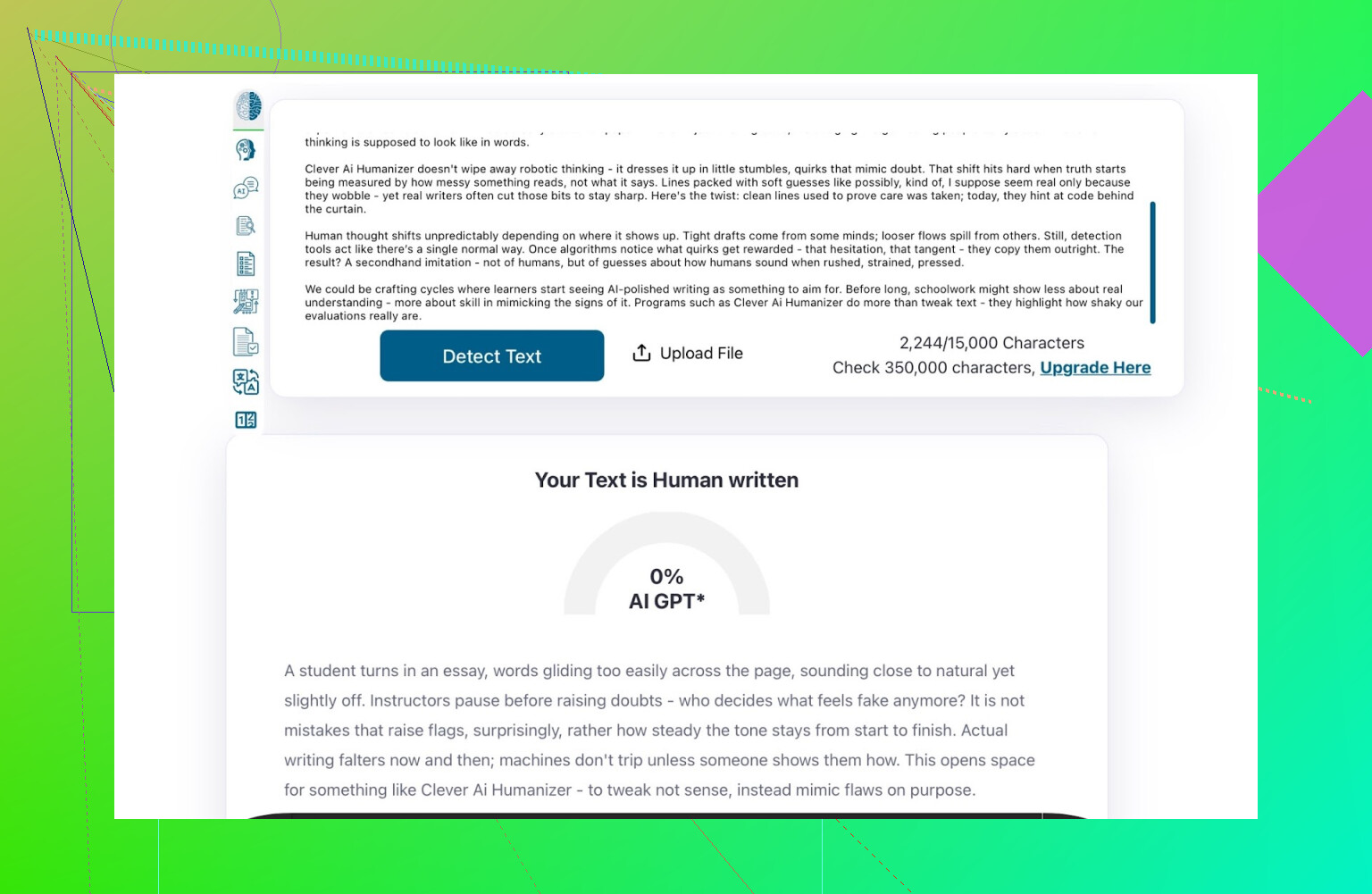
ZeroGPT: testen “jeg stoler ikke på det, men alle bruger det”
Jeg er ikke fan af ZeroGPT af én hovedgrund: det markerer den amerikanske forfatning som “100% AI”.
Når man har set det, falder tilliden ret hurtigt.
Når det er sagt:
- Det ligger stadig højt på Google.
- Folk bliver ved med at bruge det, fordi det er et af de første resultater.
- Så jeg tog det med.
Resultat for Clever AI Humanizer-outputtet:
ZeroGPT: 0% AI detected.
For hvad det er værd, er det så godt, som det kan blive i det værktøj.
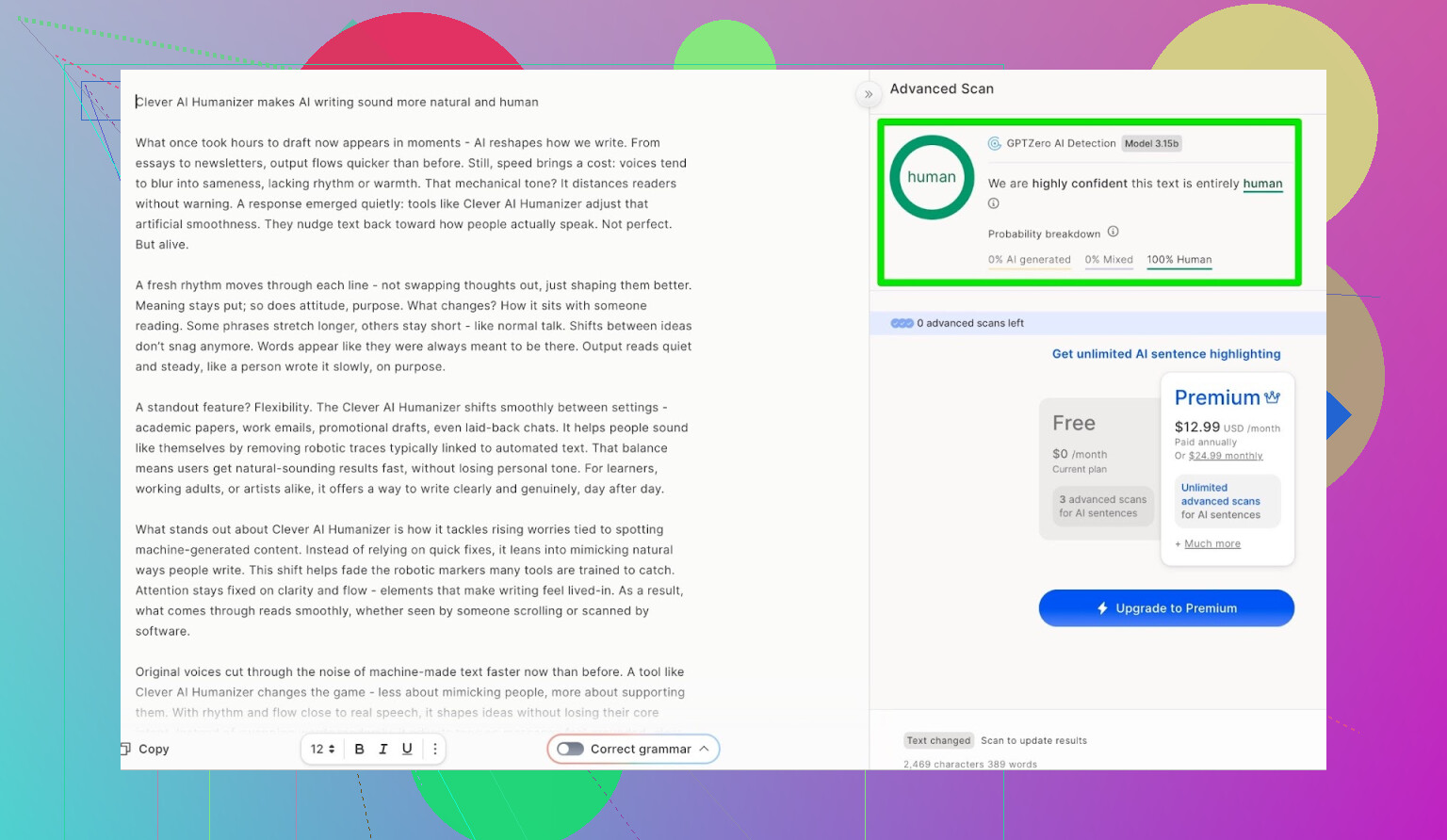
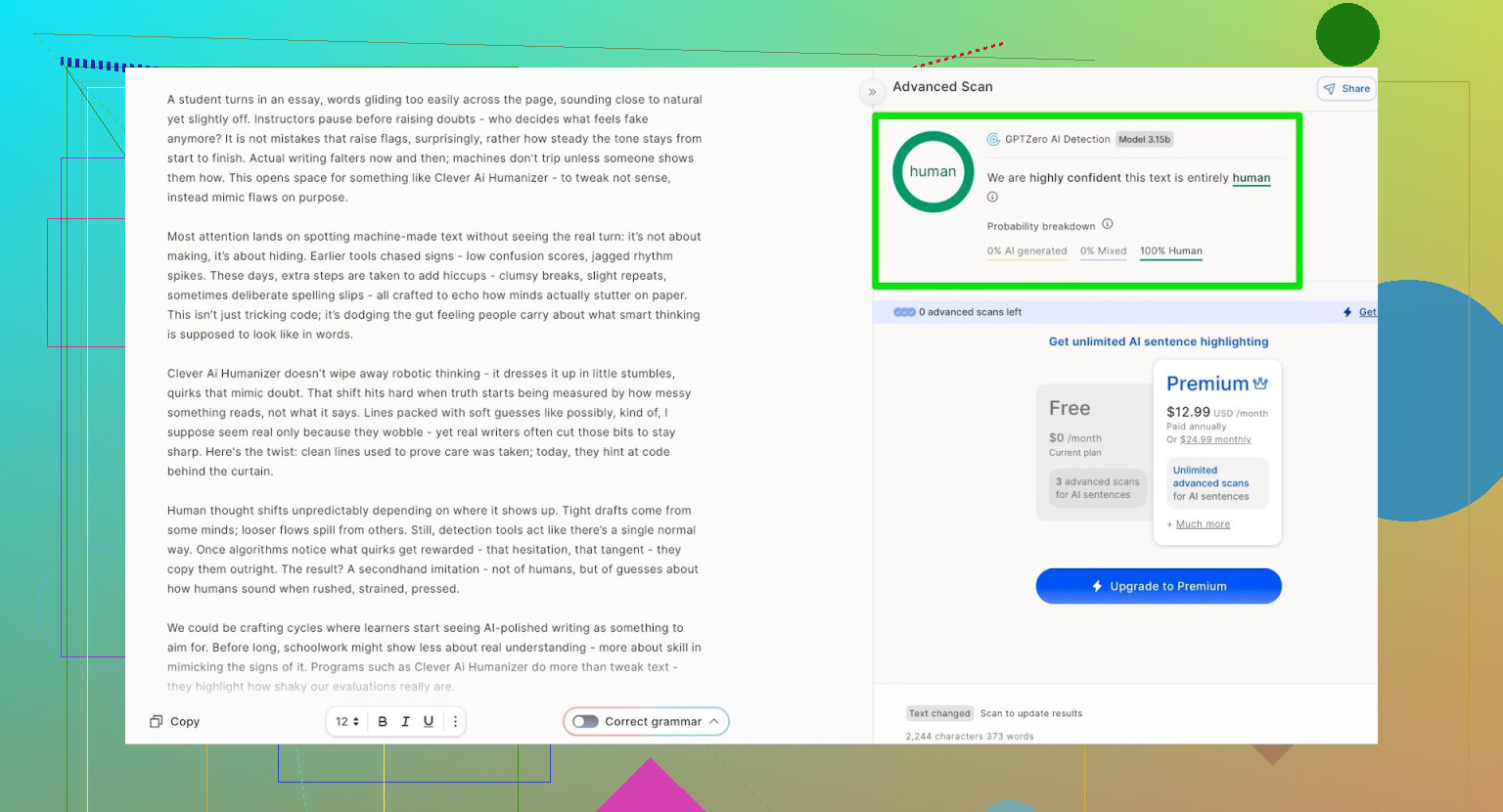
GPTZero: second opinion, samme historie
Næste var GPTZero.
Det bruges meget på skoler og universiteter og er derfor ofte det, folk frygter mest.
Outputtet fra Clever AI Humanizer (Simple Academic-tilstand) kom tilbage som:
- 100% menneskeskrevet
- 0% AI
Så på de to mest brugte offentlige detektorer klarede teksten sig med perfekte resultater.
Men lyder det som noget skrammel?
Her fejler mange humanizere:
De klarer detektorerne, men teksten føles, som om nogen har kørt dit essay gennem fire oversættelsesapps og tilbage igen.
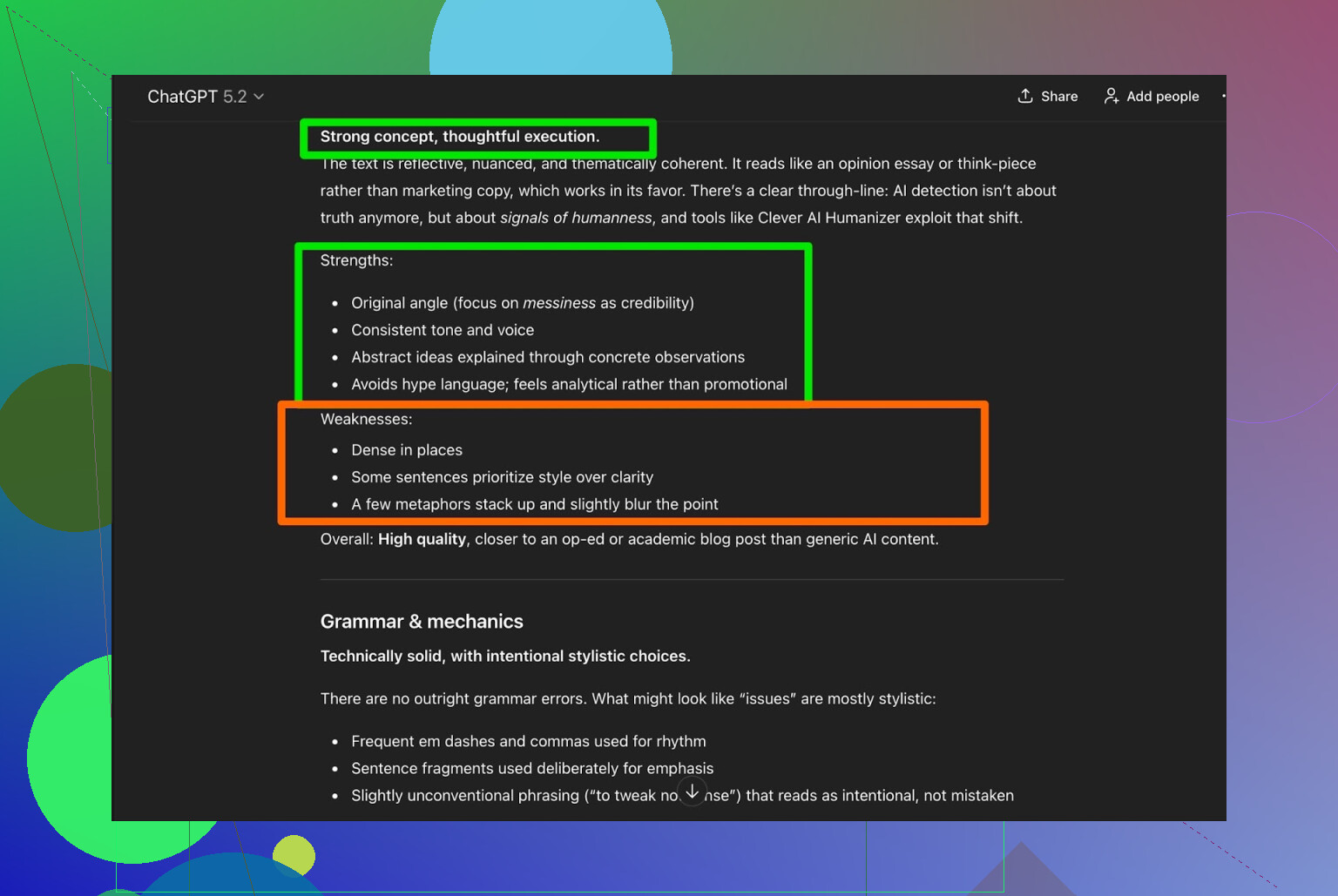
Jeg tog outputtet fra Clever AI Humanizer og bad ChatGPT 5.2 analysere det:

Overordnet vurdering:
- Grammatik: solid
- Stil: passer rimeligt godt til Simple Academic
- Anbefaling: siger stadig, at menneskelig redigering anbefales
Det er jeg egentlig enig i. Det er bare virkeligheden:
Enhver AI-skrevet eller AI-humaniseret tekst har stadig gavn af, at et menneske læser den igennem.
Hvis et værktøj påstår “ingen menneskelig redigering nødvendig”, er det sandsynligvis mere marketing end virkelighed.
Afprøvning af AI-skrivefunktionen i Clever AI Humanizer
De har et separat værktøj her:
https://aihumanizer.net/dkai-writer
Her bliver det mere interessant. I stedet for:
LLM → Kopiér → Sæt ind i humanizer → Kryds fingre
Kan du:
- Generere og humanisere i ét trin
- Lade deres system styre både struktur og stil fra starten
Det betyder noget, fordi hvis et værktøj selv genererer indholdet, kan det forme det på en måde, der naturligt undgår nogle af de mest åbenlyse AI-mønstre.
Til testen gjorde jeg:
- Valgte Casual skrivestil
- Emne: AI-humanisering, med omtale af Clever AI Humanizer
- Tilføjede med vilje en lille fejl i prompten for at se, hvordan den håndterede den
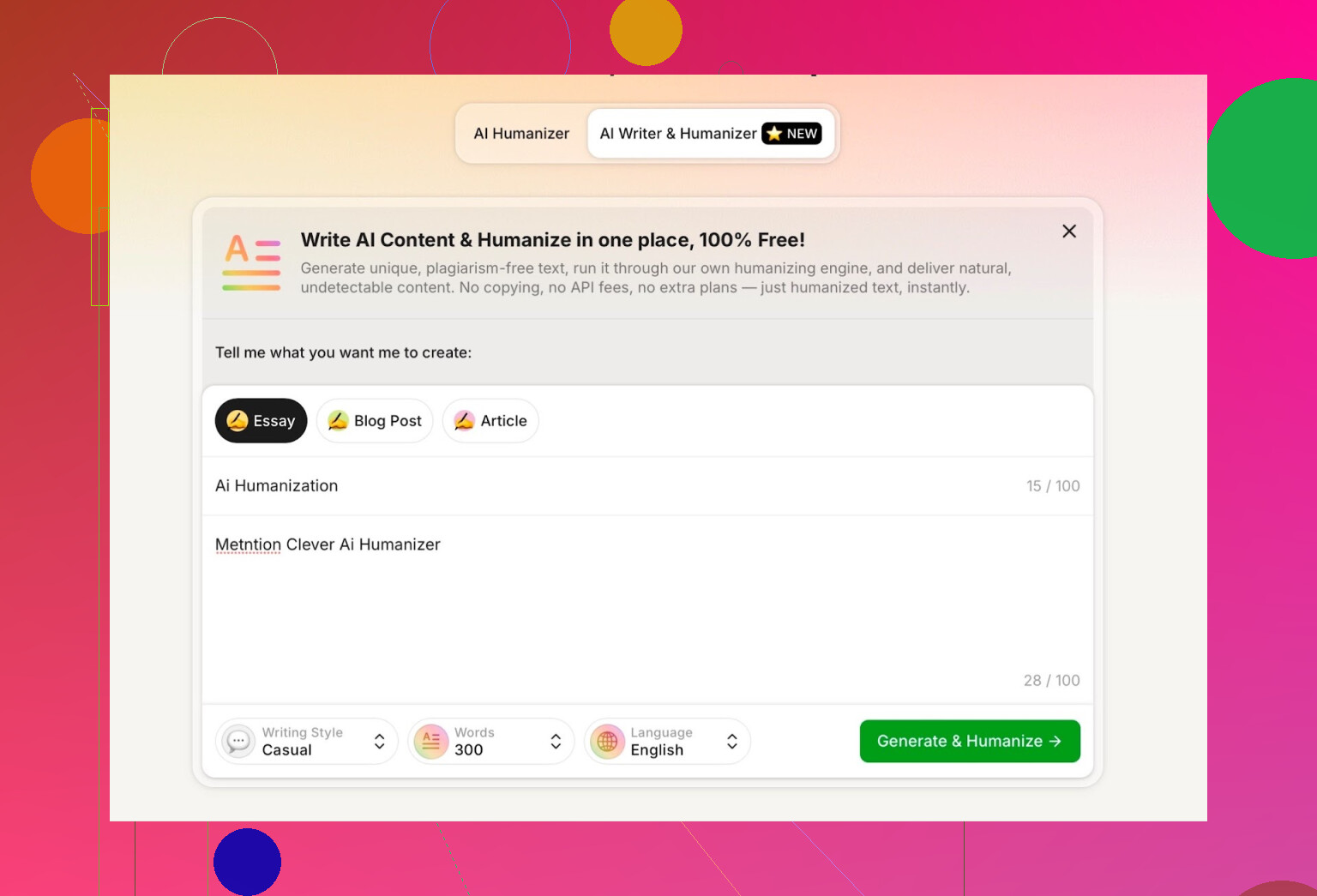
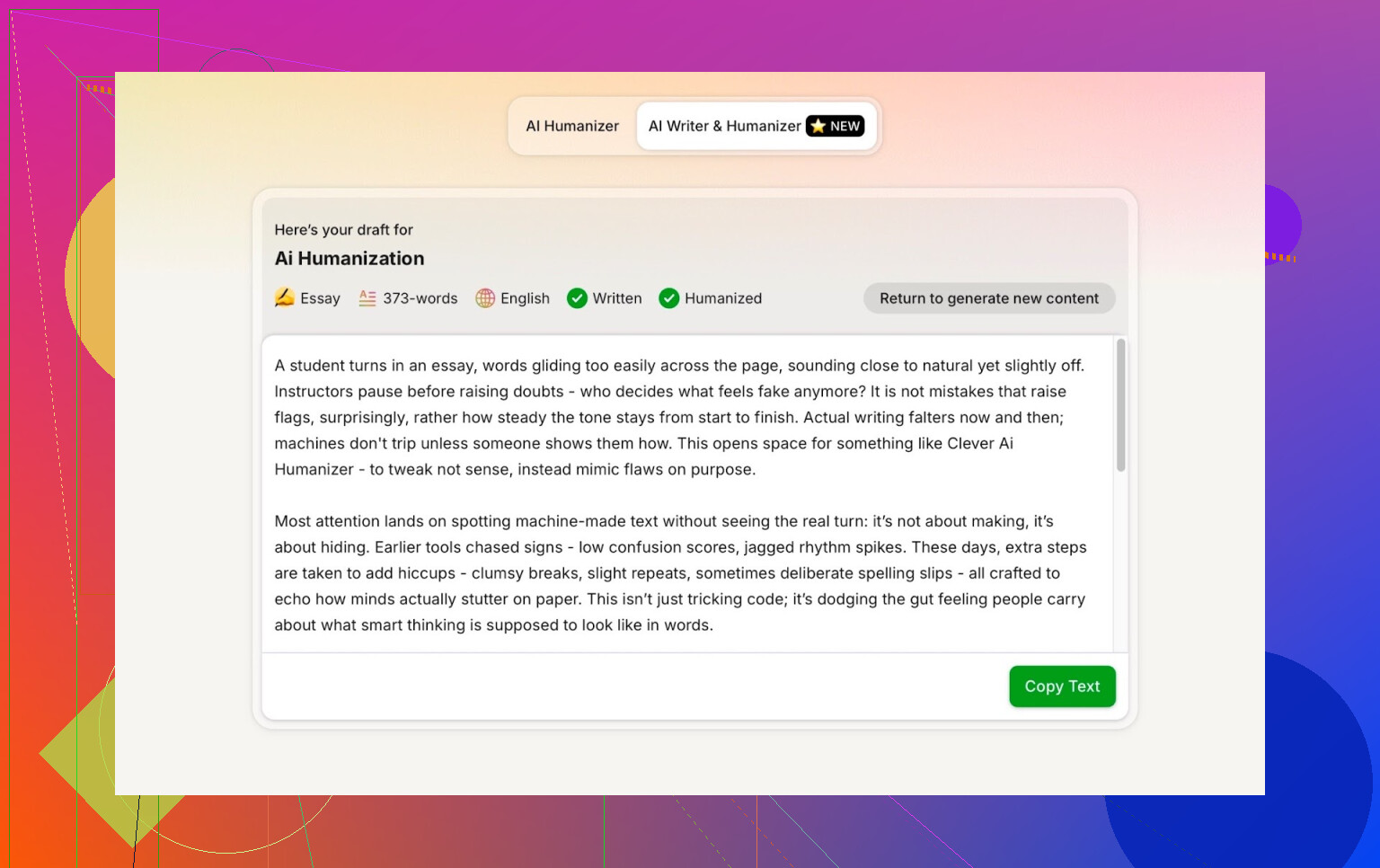
Outputtet var rent, samtalelystent og gentog ikke min slåfejl på nogen mærkelig måde.
Én ting kunne jeg ikke lide:
- Jeg bad om 300 ord
- Jeg fik mere end 300
Hvis jeg siger 300, vil jeg have 300. Ikke 412. Den slags betyder noget, hvis du arbejder med faste opgavekrav eller stramme content-briefs.
Det er min første reelle klage.
Detektionsresultater for outputtet fra AI Writer
Jeg tog teksten fra AI Writer og kørte den gennem:
- GPTZero
- ZeroGPT
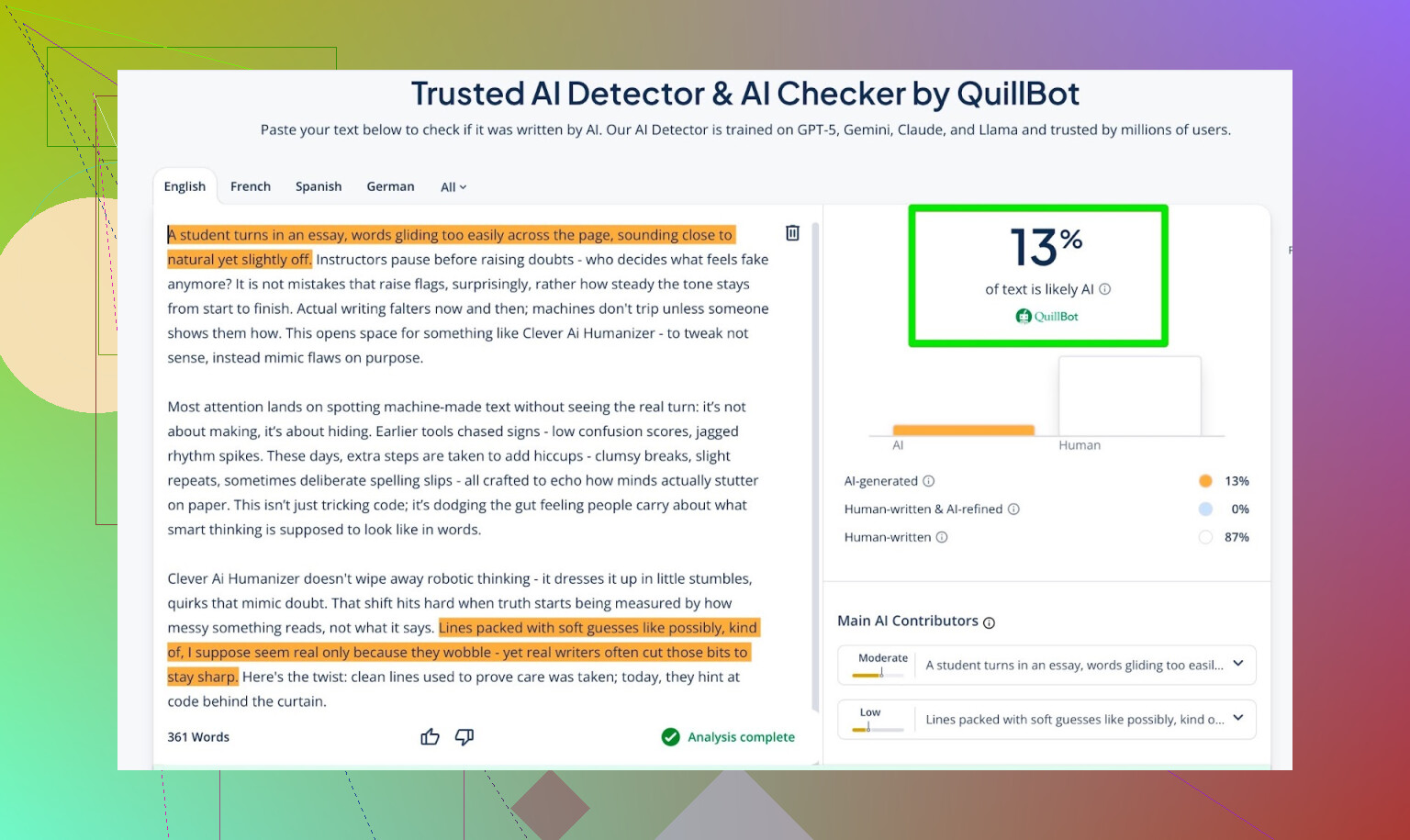
- QuillBot-detektor som ekstra datapunkt
Resultater:
- GPTZero: 0% AI
- ZeroGPT: 0% AI, 100% human
- QuillBot: 13% AI
Så QuillBot så en lille smule “AI-agtigt” mønster, men stadig mest menneskeligt.
Alt i alt ret fornuftigt.
At bede ChatGPT 5.2 vurdere outputtet fra AI Writer
Nu til den del, jeg faktisk gik mest op i: ikke kun “narre det detektorerne”, men:
- Lyder det som et menneske?
- Beholder det sammenhængen?
- Læses det naturligt?
Jeg gav teksten fra AI Writer tilbage til ChatGPT 5.2 og spurgte, om den virkede menneskeskrevet eller AI-skrevet.
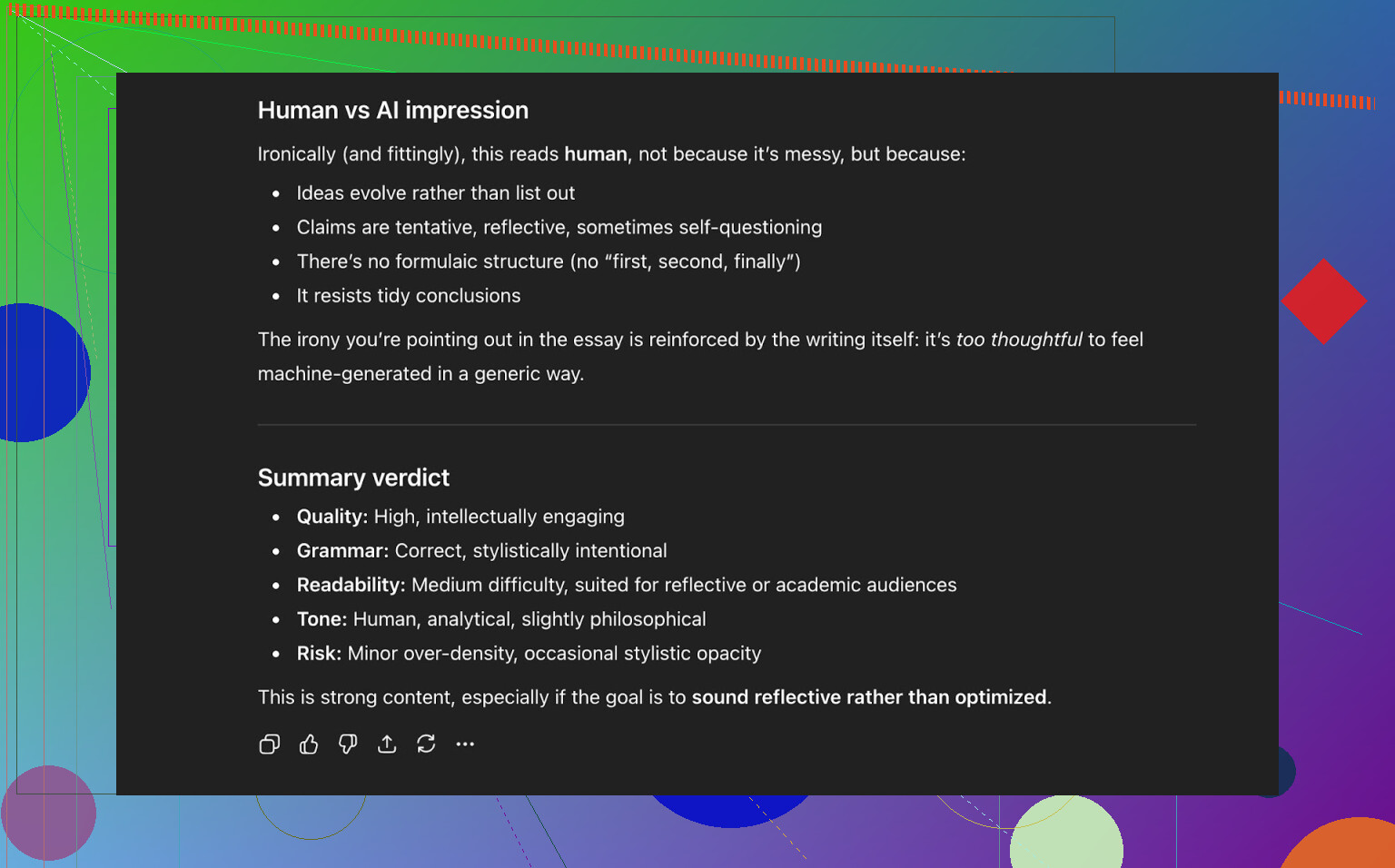
Konklusion fra ChatGPT 5.2:
- Læses som menneskeskrevet
- Kvaliteten er stærk
- Intet åbenlyst galt i grammatik eller struktur
Så på dette tidspunkt havde teksten:
- Bestået tre offentlige AI-detektorer pænt
- Også “narret” en moderne LLM til at klassificere den som menneskeskrevet
Hvordan det klarer sig mod andre humanizere, jeg testede
I mine egne tests klarede Clever AI Humanizer sig bedre end en række andre værktøjer, folk ofte nævner.
Her er en hurtig oversigtstabel fra de kørseler:
| Værktøj | Gratis | AI-detektorscore |
| ⭐ Clever AI Humanizer | Ja | 6% |
| Grammarly AI Humanizer | Ja | 88% |
| UnAIMyText | Ja | 84% |
| Ahrefs AI Humanizer | Ja | 90% |
| Humanizer AI Pro | Begrænset | 79% |
| Walter Writes AI | Nej | 18% |
| StealthGPT | Nej | 14% |
| Undetectable AI | Nej | 11% |
| WriteHuman AI | Nej | 16% |
| BypassGPT | Begrænset | 22% |
Værktøjer, det slog i mine egne, konkrete tests:
- Grammarly AI Humanizer
- UnAIMyText
- Ahrefs AI Humanizer
- Humanizer AI Pro
- Walter Writes AI
- StealthGPT
- Undetectable AI
- WriteHuman AI
- BypassGPT
For at være helt tydelig: tabellen bygger på detektorscores, ikke på “hvilket lyder bedst subjektivt”.
Hvor Clever AI Humanizer stadig halter
Det er ikke magisk, og det er ikke fejlfrit.
Nogle problemer, jeg lagde mærke til:
- Dårlig styring af ordantal
- Beder du om 300 ord, får du måske 280 eller 370.
- Mønstre kan stadig dukke op
- Visse LLM’er kan indimellem stadig markere dele som AI-agtige.
- Indholdsdrift
- Det spejler ikke altid originalen helt; nogle gange omskriver det mere aggressivt end forventet.
På den positive side:
- Grammatisk kvalitet: omkring 8–9/10 i mine tests
- Flyder godt nok til, at du ikke snubler over formuleringer i hver anden linje
- Ingen irriterende strategi med bevidste fejl som at skrive “i was” i stedet for “I was” for at snyde detektorer
Det sidste er vigtigt. Nogle værktøjer indsætter bevidst fejl for at virke mere menneskelige. Det kan måske snyde detektorer oftere, men gør teksten dårligere.
Det mærkelige: 0% AI føles ikke altid “menneskeligt”
Der er noget subtilt, som er svært at beskrive: selv når en tekst får 0% AI på flere detektorer, kan du nogle gange mærke, at den er formet af en maskine. Rytmen, måden ideer introduceres på, den perfekte pænhed.
Clever AI Humanizer gør det bedre end de fleste, men det underliggende mønster er der stadig indimellem. Det er ikke så meget en kritik af værktøjet som af, hvor hele feltet befinder sig lige nu.
Det er bogstaveligt talt en katten-efter-musen-situation:
- Detektorer bliver klogere
- Humanizere tilpasser sig
- Detektorerne opdateres igen
- Gentag
Hvis du forventer, at noget værktøj er “fremtidssikret”, bliver du skuffet.
Så, er det “det bedste” gratis humanizer lige nu?
Blandt de gratis værktøjer, jeg faktisk har testet med detektorer og LLM-tjek:
- Vil jeg indtil videre placere Clever AI Humanizer øverst.
- Især når man tager i betragtning, at det både har:
- En humanizer til eksisterende tekst
- En integreret AI Writer, der humaniserer, mens den skriver
Du skal stadig:
- Selv læse outputtet igennem
- Fikse det, der føles forkert
- Justere tonen, så det lyder som dig
Men hvis spørgsmålet er:
“Er Clever AI Humanizer værd at prøve lige nu, især når det er gratis?”
Så er mit svar ud fra mine tests: ja.
Ekstra, hvis du vil endnu dybere ned i kaninhullet
Der findes nogle diskussioner og tests på Reddit med flere skærmbilleder og dokumentation:
-
Generel sammenligning af AI humanizere med detektionsresultater:
https://www.reddit.com/r/DataRecoveryHelp/comments/1oqwdib/best_ai_humanizer/?tl=dk -
En specifik anmeldelsestråd om Clever AI Humanizer:
https://www.reddit.com/r/DataRecoveryHelp/comments/1ptugsf/clever_ai_humanizer_review/?tl=dk
Hvis du vælger at prøve Clever AI Humanizer, ville jeg stadig betragte det som:
- En hjælper, ikke en erstatning
- Noget, der bringer dig 70–90% af vejen
- Et værktøj, der kun er så godt som det menneske, der gennemgår det endelige resultat
Du er stadig den, der skal kunne stå inde for ordene.
Kort svar: Du får ikke den slags ærlig feedback fra rigtige brugere, du ønsker, bare ved at kigge på detektorscorer eller spørge andre AI’er, hvad de synes. Det er en del af historien, men det er også den dovneste del.
Du har allerede set @mikeappsreviewer lave detector-OL og strukturerede tests. Brugbart, men det fortæller dig stadig ikke, hvordan dit værktøj føles for en, der er træt kl. 1 om natten og skal gøre et paper færdigt, eller for en content manager der batchbehandler 20 artikler og er ved at give op.
Hvis du vil have signal fra den virkelige verden, så gør ting som dette:
-
Indbyg feedback i selve brugssituationen
- Efter hvert run: 3-klik mikroundersøgelse:
- “Lød: [Alt for robotagtigt] [Ret naturligt] [Meget menneskeligt]”
- “Var dette output sikkert at aflevere som det er? [Ja/Nej]”
- Så en lille frivillig tekstboks: “Hvad irriterede dig?”
- Spørg ikke “Hvad kunne du lide?” Det giver dig falsk ros. Spørg hvad der var dårligt.
- Efter hvert run: 3-klik mikroundersøgelse:
-
Track adfærd, ikke kun holdninger
- Mål:
- Hvor ofte brugere trykker “generer igen”
- Hvor ofte de straks retter i teksten i din editor (hvis du har en)
- Afbrydelser midt i sessioner
- Hvis folk genererer igen 3–4 gange pr. input, siger værktøjet i praksis, at det fejler, selv hvis spørgeskemaerne ser positive ud.
- Mål:
-
Kør målrettede brugertests i stedet for tilfældig trafik
Fang små, specifikke grupper i stedet for “internettet”:- Studerende der prøver at undgå AI-flags
- Freelance-skribenter/content-bureauer
- Ikke-native engelsktalende der pudser tekst af
Tilbyd dem: - Et privat testmiljø
- En håndfuld faste opgaver (omskriv essay-intro, puds LinkedIn-opslag osv.)
- 10–15 minutters kald eller skærmoptaget session for hver
Bestik dem med Amazon-gavekort, gratis premium-brug, hvad som helst. Den kvalitative feedback du får fra 20 sådanne personer slår 2.000 anonyme klik.
-
A/B-test dit eget værktøj mod en baseline
I stedet for at spørge “Er det her godt?” så spørg “Er det her bedre end X?”
Du kan i hemmelighed køre:- Version A: råt LLM-output
- Version B: dit humaniserede output
Vis dem blindt for testere og spørg: - “Hvilket lyder mest som om et rigtigt menneske har skrevet det?”
- “Hvilket ville du faktisk aflevere/poste?”
Du behøver slet ikke nævne detektorer her.
-
Brug “fjendtlige” reviewere med vilje
Find folk der hader AI-indhold eller er ultrakritiske redaktører.
Sig til dem:- “Forestil dig, at en juniorskribent har givet dig det her. Riv det fra hinanden.”
Deres noter om tone, gentagelser, stivhed og logisk flow er langt mere værd end “ZeroGPT siger 0 % AI.”
- “Forestil dig, at en juniorskribent har givet dig det her. Riv det fra hinanden.”
-
Dogfood det offentligt, men ærligt
Brug output fra din egen Clever AI Humanizer på:- Teksten på dit produktsite
- Release notes
- Blogindlæg
Tilføj så en lille linje nederst:
“Dette indlæg blev skrevet med Clever AI Humanizer og let redigeret af et menneske. Var der noget, der føltes forkert? Fortæl os det.”
Du får brutal, rå feedback fra de mennesker, der går nok op i det til at klage. -
Test fejlsituationer, ikke kun “idealtilfælde”
De fleste værktøjer ser fine ud på pæn, formel tekst. Du bør teste:- Kaotiske prompts
- Knækket engelsk
- Slang, emojis, underlig formatering
- Meget korte ting som emnelinjer til mails
Spørg brugerne: - “Hvor mislykkedes den fuldstændig?”
Log og kategorisér de fejl.
-
Hold øje med “vibes-problemet”
Selv når detektorer viser 0 % AI, føles meget tekst stadig maskinformet: samme rytme, pæne afsnit, forudsigelige overgange.
Det fanger du ikke med detektorer.
Du fanger det, hvis du:- Spørger brugere: “Lyder det her som dig?”
- Lader dem indsætte “før” og “efter” og spørger, hvilken de faktisk ville sende til deres chef eller underviser.
-
Overfokuser ikke på at omgå detektorer
Let uenighed med den detektor-fokuserede vinkel fra @mikeappsreviewer her: brugere tror, de vil have “0 % AI”, men på sigt bliver de kun, hvis:- Det matcher deres tone
- Det ikke introducerer løgne
- Det ikke får dem til at lyde som en mærkelig, generisk blogger
Sæt brugeroplevelsen først og “uopdagelighed” som nummer to. Ellers ender du i en kattens-leg-med-musen, du til sidst taber.
-
Tilføj en brutalt transparent kvalitetsmåler til dig selv
Internt, tag hver kørsel (anonymiseret) med:
- Detektorscorer
- Menneskelig vurdering (fra et lille panel du stoler på)
- Brugerfeedback (“irritationsnoter”)
Gennemgå hver måned dine værste 5–10 % af outputs. Det er dér guldet ligger.
Hvis du vil have et konkret næste skridt:
- Lav en lille “beta tester”-side på Clever AI Humanizer.
- Sæt loft ved fx 50 rigtige brugere.
- Giv dem en klar aftale: “Brug det gratis, men du skal sende 3 eksempler om ugen på, hvor det var dårligt eller føltes forkert.”
Du mangler ikke brugere. Du mangler struktureret, smertefuld feedback. Byg kanalerne til det, og du lærer mere på to uger end af endnu 20 screenshots af detektor-dashboard.
Kort svar: detektor-screenshots og AI’ens egne selv-evalueringer er ikke “rigtig brugerfeedback”, det er et laboratorieforsøg. Du er halvvejs der, men du spørger det forkerte publikum.
Et par tanker der ikke bare gentager det @mikeappsreviewer og @kakeru allerede har dækket:
-
Stop med at spørge om det “virker”, og begynd at spørge for hvem det virker
Lige nu jagter du lidt et universelt svar: “Er min AI humanizer god?” Det er uklart. I praksis er der meget forskellige use cases:
- Studerende der prøver ikke at blive fanget
- Indholdsskribenter der vil gøre udkast mindre robotagtige
- Ikke-native talere der vil lyde mere naturlige i mails
- Marketers der vil bevare brandets tone
Dit feedbackproblem kan være: du lukker alle ind og lytter ikke til en specifik gruppe. Vælg en eller to segmenter og optimer feedback-loops omkring dem.
-
Tilbyd meningsfulde presets og døm ud fra, hvilken der bliver misbrugt
I stedet for generiske tilstande som “simpel akademisk” eller “uformel”, stram dem omkring virkelige situationer:
- “Polering af college-essay”
- “LinkedIn thought leadership”
- “Kold mail til en leder”
- “Blog-intro forbedrer”
Gør så dette:
- Track hvilken preset der bruges mest
- Track hvilken der har flest “kopier alt” uden redigering
- Track hvilken brugerne forlader midt i forløbet
Hvis “Polering af college-essay” bruges massivt, men folk hopper fra efter ét run, har du specifikke, handlingsbare fejldata. Det er bedre end endnu et detektor-screenshot.
-
Byg en “Min stemme vs humaniseret stemme”-sammenligning ind
Her er jeg en smule uenig i den tunge detektor-fokus fra andre: på lang sigt går folk mere op i stemme end 0 % AI. Hvis teksten holder op med at lyde som dem, dropper de dit værktøj, selv hvis det er “udetectable”.
Lad brugerne:
- Indsætte original tekst
- Få et humaniseret resultat
- Se en hurtig diff-lignende oversigt:
- “Formalitet: +20 %”
- “Personlig tone: -30 %”
- “Sætningslængde: +15 %”
Og spørg så direkte:
“Lyder det her stadig som dig?” [Ja / Lidt / Nej]
Det spørgsmål alene giver dig mere ærlig signal end “Vurder 1–5 stjerner”.
-
Du har brug for negative incitamenter, ikke kun gulerødder
Alle taler om gavekort, beta-fordele osv. Problemet: folk fortæller dig det, du gerne vil høre, for at beholde fordelene.
Prøv dette:
- “Hvis du sender os 3 virkelig dårlige outputs (screenshots eller indsat tekst), låser vi X ekstra credits op.”
- Du belønner ikke “at bruge værktøjet meget”, du belønner “at finde hvor det fejler”.
Det holder fokus på dine svage punkter i stedet for vage “ja det er fint, tak”-kommentarer.
-
Lav en intern “Hall of Shame”
Du ved allerede, at værktøjet kan præstere godt under bedste betingelser. Det du mangler, er en kurateret bunke af:
- Værste outputs
- Mest akavede sætninger
- Gange hvor det ændrede betydning
- Gange hvor det fik en bruger til at lyde som en generisk AI-blogger
Én gang om ugen trækker du:
- De 50 sessioner med flest hurtige regenereringer
- De 50 med hurtigst luk efter output
Inspicer manuelt 10–20 af dem og tag, hvorfor de var dårlige. Det mønster er din vej til forbedring.
-
Skab friktion ét sted i tragten
Du optimerer sandsynligvis for “ingen login, super hurtigt, lav friktion”. Godt for trafik, elendigt for feedback.
Overvej en separat “Pro feedback sandbox”:
- Kræver e-mail eller minimal tilmelding
- Giver højere grænser eller ekstra tilstande
- Til gengæld skal brugerne:
- Sætte 2 krydser pr. output: “Naturligt / Robotagtigt” og “On topic / Skred ud”
- Eventuelt indsætte kontekst som “Jeg brugte det til [skole / arbejde / sociale medier]”
Folk der bruger 20 sekunder på at tilmelde sig, er meget mere tilbøjelige til at give reel feedback end tilfældige forbipasserende.
-
Indbyg forventninger direkte i UI’et
Let uenighed med den uudtalte antagelse du måske bærer rundt på: “Hvis det er godt nok, burde brugerne kunne klikke kopier og gå videre.” Sådan bruger rigtige mennesker ikke værktøjer som dette.
Tilføj bogstaveligt talt tekst som:
“Det her bringer dig 70–90 % i mål. Du skal lige give det et hurtigt menneskeligt tjek, før du sender.”
Spørg så direkte:
- “Skulle du stadig redigere det meget?” [Lidt / Meget / Skrev det stort set om]
Det er ærlig feedback uden krav om lange spørgeskemaer.
- “Skulle du stadig redigere det meget?” [Lidt / Meget / Skrev det stort set om]
-
Udnyt sammenligning med konkurrenter uden at være cringy
Da folk tydeligvis også prøver ting som Grammarlys humanizer, Ahrefs, Undetectable osv., kan du bruge det i stedet for at lade som om de ikke findes.
Tilføj en lille checkbox:
- “Har du prøvet lignende værktøjer (som Grammarly eller Ahrefs AI humanizers)?
- Ja, og det her er bedre
- Ja, og det her er dårligere
- Nogenlunde det samme
- Har ikke prøvet andre”
Ingen brand-bashing, ingen “vi er bedst”-hype. Kun data.
Brug det til at forstå positionering, ikke kun kvalitet. - “Har du prøvet lignende værktøjer (som Grammarly eller Ahrefs AI humanizers)?
-
Stop med at antage at detektor-succes = produktsucces
Baseret på det @mikeappsreviewer viste, er din Clever AI Humanizer allerede stærk mod offentlige detektorer. Fint. Men spørg dig selv:
- “Hvis alle detektorer forsvandt i morgen, ville mit værktøj så stadig være værd at bruge?”
Hvis det ærlige svar er “ikke rigtigt”, bør din roadmap dreje mere mod:
- Personalisering
- Tonekontrol
- Sikkerhed (ingen hallucinationer, ingen usande påstande)
- Bevarelse af oprindeligt formål
Det er dét, der overlever når detektor-kapløbet køler ned.
-
Positionér eksplicit Clever AI Humanizer som et samarbejdsværktøj
Du får meget bedre feedback, hvis du stopper med at lade som om det er en usynlighedskappe.
Eksempel i dit UI:
“Skrevet af AI, forfinet af Clever AI Humanizer, afsluttet af dig.”
Det får brugerne til at tænke:
- “Hvad hjalp det mig med?”
- “Hvor gjorde det mit liv sværere?”
Bed om feedback i den ramme:
- “Sparede Clever AI Humanizer dig tid på det her?” [Ja / Nej]
- “Ændrede det din betydning?” [Ja / Nej]
Krydsfeltet “Ingen tid sparet” + “Ændrede min betydning” er dér, du fejler hårdest.
Hvis du vil have et meget praktisk tiltag, du kan implementere på en dag:
- Efter hvert output viser du 3 knapper:
- “Jeg ville sende det her som det er”
- “Jeg ville bruge det, men skal redigere”
- “Det her kan jeg ikke bruge”
- Hvis de vælger den sidste, stiller du ét opfølgende spørgsmål:
- “For robotagtigt / Off-topic / Forkert tone / Dårligt engelsk / Andet”
Det lille flow, i skala, vil fortælle dig langt mere om den virkelige performance af Clever AI Humanizer end endnu en måned med detektor-tests eller at spørge andre LLM’er, om de er blevet “narret”.
Hurtig analytisk vurdering fra en anden vinkel, da andre allerede har dykket ned i UX og testning:
1. Behandl “ægte feedback” som data, ikke meninger
I stedet for flere detector-eksperimenter skal du koble hårde målinger på Clever AI Humanizer:
Kernetal at spore:
- Fuldførelsesrate: tekst indsat → humaniser → kopier.
- Regenereringsrate pr. input: mange regenereringer = utilfredshed.
- Tid til kopi: hvis folk kopierer inden for 2–5 sekunder, læser de ikke, de farmer.
- Redigeringsintention: klik på “Kopier med formatering” vs “Kopier ren tekst” vs “Download.” Forskellige mønstre svarer typisk til forskellige use cases.
Det giver dig tavs feedback fra hver session, ikke kun de få personer, der er villige til at skrive lange beskeder til dig.
2. Letvægts-cohortmærkning
Andre foreslog persona-målretning. Jeg ville gøre det brutalt enkelt:
Ved første brug, en 1-klik vælger over boksen:
- “Bruger dette til: Skole / Arbejde / Socialt / Andet”
Ingen login, ingen friktion. Bare gem et anonymt cohort-tag.
Nu kan du se:
- Skole: højest regenerering og frafald
- Arbejde: længst tid på siden men høj kopieringsrate
- Socialt: hurtig kopi, lav længde, måske ikke værd at optimere
Du gætter ikke længere på, hvilket publikum du fejler over for.
3. A/B-test “aggressiv vs konservativ” humanisering
Lige nu føles Clever AI Humanizer optimeret til detector-undgåelse plus læsbarhed. Det er fint, men forskellige brugere ønsker forskellige grader af redigering.
Kør en stille split test:
- Version A: minimale ændringer, bevarer struktur, let omskrivning
- Version B: kraftigere omskrivning, mere variation, flere rytmeskift
Sammenlign derefter:
- Hvilken version får mest “kopier og gå”-adfærd
- Hvilken version udløser mest “Kør igen”-brug
Ingen spørgeskema, ingen tiggeri om feedback. Adfærd er svaret.
4. Fordele / ulemper som produkt-reality check
Sammenlignet med det @kakeru og @andarilhonoturno beskrev, mener jeg, at dit værktøj allerede ligger i “bedre end gennemsnitligt”-spanden, men det hjælper at navngive ting klart:
Fordele ved Clever AI Humanizer
- Stærk performance mod almindelige AI-detectors, når der testes i realistisk indhold.
- Output læses generelt rent og grammatisk uden det tvungne “stavefejl-spam”-trick, som nogle værktøjer bruger.
- Flere stilarter (Simple Academic, Casual osv.), som passer ret godt til virkelige skrivesituationer.
- Integreret AI-skribent, der kan generere og humanisere i ét hug, hvilket reducerer åbenlyse LLM-fingeraftryk.
- Gratis og let onboarding, hvilket er godt til tidlig adoption og giver masser af testdata i tragten.
Ulemper ved Clever AI Humanizer
- Ordantalskontrol er løs, hvilket er et reelt problem for stramme opgaver og briefs.
- Omskriver nogle gange for aggressivt og introducerer indholdsdrejninger, som brugere ikke altid opdager.
- Selv med 0% AI-scorer føles nogle tekster stadig maskinformede i struktur og rytme.
- Detector-centreret value proposition sætter dig i et konstant kat-og-mus-spil og kan ældes dårligt.
- Lidt eksplicit stemmepersonalisering, så hyppige brugere kan føle, at deres skrivning begynder at lyde ens.
5. Stop med at overfitte til detectors, begynd at overfitte til tilbagevendende brugere
Her er jeg lidt uenig i det tunge detector-fokus, der dukker op i @mikeappsreviewer’s tests. Detector-screenshots er nyttig marketing, men de er et skrøbeligt produktmål.
Mere holdbart signal:
- Hvor mange brugere kommer tilbage inden for 7 dage
- Blandt tilbagevendende brugere, hvor mange sessioner vokser i ordantal over tid (tillidssignal)
- Hvor ofte den samme browser / IP bruger værktøjet på tværs af forskellige kontekster (skole + arbejde osv.)
Rigtige brugere bliver ikke hængende, fordi en detector sagde “0% AI.” De bliver, fordi:
- Det sparede dem tid.
- Det gjorde dem ikke pinligt berørt.
- Det ændrede ikke, hvad de mente.
Optimer for gentagen adfærd først, detector-scorer som nummer to.
6. Byg et “tillidsmønster” i stedet for et “cloak-mønster”
Du bør ikke prøve at slå alle fremtidige detectors. Du bør prøve at være det værktøj, der:
- Holder betydningen intakt.
- Lader tonen være justerbar.
- Dokumenterer begrænsninger tydeligt.
En subtil UI-tilføjelse, der betaler sig:
- Efter output vis en kort, ærlig opsummering som:
- “Betydning bevaret: høj”
- “Toneskift: moderat”
- “Sætningsstruktur ændret: høj”
Folk begynder at stole på dig, fordi du viser dit arbejde. Den tillid giver dig indirekte bedre feedback end noget spørgeskema.
7. Sådan får du kvalitativ feedback uden at plage
Lån adfærdsbaserede triggere:
-
Hvis brugeren kører 3+ regenereringer på samme input:
- Vis en lille inline prompt:
- “Får du ikke det, du skal bruge? Fortæl os det på 5 ord.” [lille tekstboks]
Det giver brutalt ærlige kommentarer som “for robotagtig,” “ændrede min pointe,” “for ordrig.”
- “Får du ikke det, du skal bruge? Fortæl os det på 5 ord.” [lille tekstboks]
- Vis en lille inline prompt:
-
Hvis brugeren bruger >40 sekunder på at redigere tekst i din tekstboks før humanisering:
- Spørg: “Retter du AI-tekst eller pudser du din egen skrivning?”
Det hjælper dig med at forstå, om Clever AI Humanizer bliver set som “AI-fixer” eller “redaktør,” hvilket betyder noget for roadmap.
- Spørg: “Retter du AI-tekst eller pudser du din egen skrivning?”
Ingen store modaler, ingen “giv os 5 stjerner,” kun små kontekstbevidste prik.
8. Hvor konkurrenter passer ind i din mentale model
Du har allerede godt sammenligningsarbejde fra folk som @kakeru og den mere detector-tunge anmeldelse fra @mikeappsreviewer. Brug dem som benchmarks, men ikke som nordstjerner.
Se på andre som:
- “Det her er, hvad der sker, når du skruer op for detector-undgåelse og ignorerer stemme.”
- “Det her er, hvad der sker, når du laver let omskrivning og holder dig sikker men detekterbar.”
Clever AI Humanizer’s edge ligger i at forsøge at balancere læsbarhed og detektion. Din næste edge bør være personalisering og kontrol, ikke bare lavere procenter på endnu en offentlig detector.
Hvis du vil have én konkret ting at lancere i denne uge, som både forbedrer produktet og giver dig reelt signal fra virkeligheden:
- Tilføj to toggles før humanisering:
- “Bevar så meget struktur som muligt”
- “Ændr struktur for mere menneskelig variation”
Log derefter, hvilken kombination af toggles der korrelerer med:
- Højere kopieringsrater
- Færre regenereringer
- Flere tilbagevendende sessioner
Du vil meget hurtigt vide, hvilken type “humanisering” dine faktiske brugere virkelig ønsker, i stedet for at gætte ud fra detector-diagrammer.