Jeg har laget et smart AI-humaniseringsverktøy som skal få AI-generert tekst til å høres mer naturlig og autentisk ut, men jeg sliter med å få ærlige tilbakemeldinger fra ekte brukere. Jeg vil gjerne vite hvordan det fungerer i praktisk bruk: høres det faktisk menneskelig ut, er det til å stole på for innholdsproduksjon og SEO, og hvor svikter det eller føles åpenbart AI-laget? Jeg trenger detaljerte, praktiske tilbakemeldinger slik at jeg kan rette feil, forbedre kvaliteten og sikre at det er trygt og pålitelig for bloggere, markedsførere og vanlige brukere som vil ha menneskelig klingende AI-innhold.
Clever AI Humanizer: Min faktiske erfaring, med dokumenterte beviser
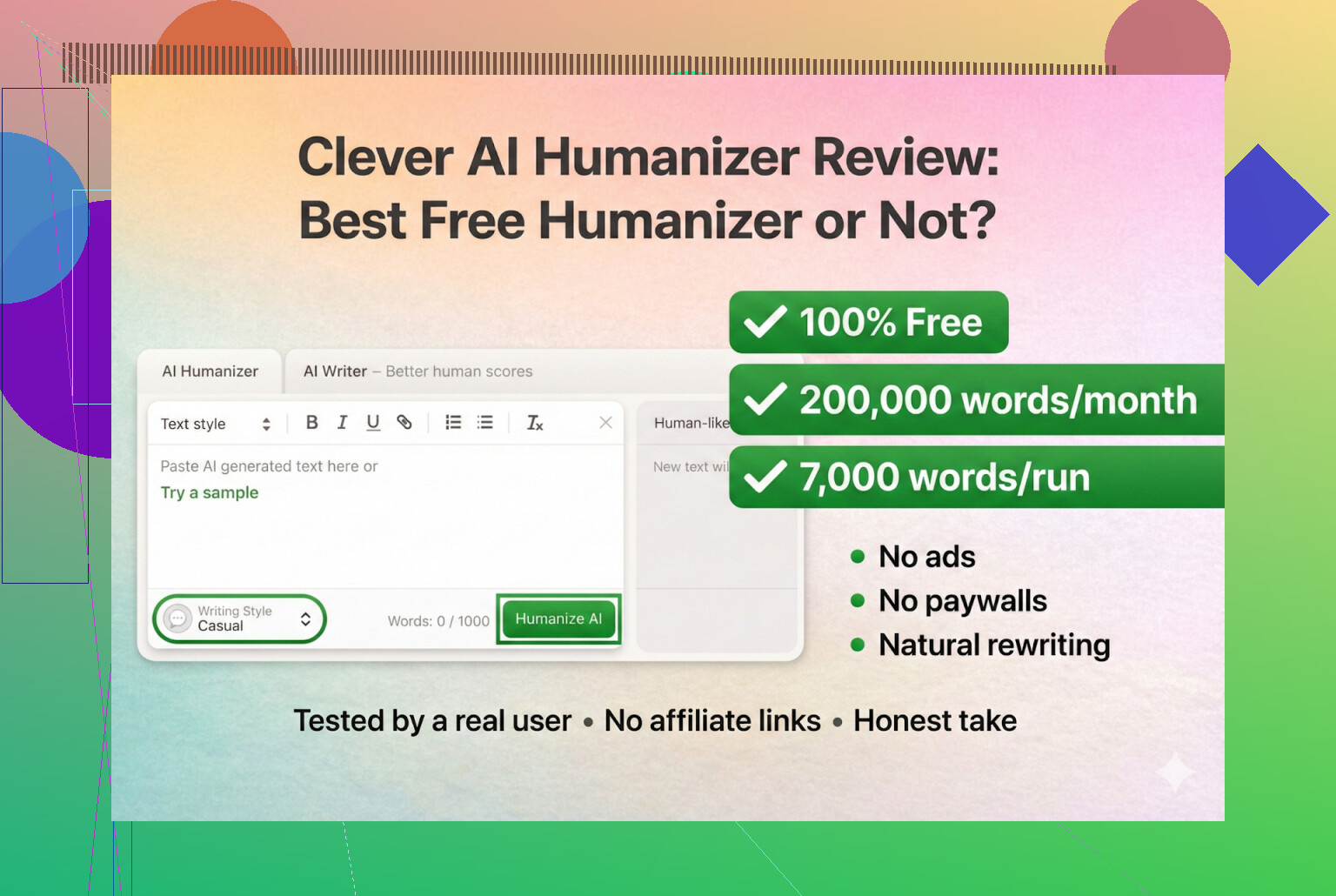
Jeg har tuklet en del med ulike «AI humanizer»-verktøy i det siste, mest fordi jeg stadig så folk på Discord og Reddit som spurte hvilke som fortsatt fungerer. Mange av dem enten sluttet å virke, ble omgjort til betalt SaaS over natten, eller ble stille og rolig dårligere.
Så jeg bestemte meg for å starte med verktøy som faktisk er gratis, uten innlogging og uten kredittkort. Først på lista: Clever AI Humanizer.
Du finner det her:
Clever AI Humanizer — Best 100% Free Humanizer
Så langt jeg kan se, er dette den ekte, ikke en klone og ikke en rar rebranding.
URL-forvirring og falske kopier
En liten «public service announcement», fordi jeg selv gikk på en smell: det finnes en haug «AI humanizer»-nettsteder som bruker lignende navn og kjøper annonser på samme søkeord. Et par personer sendte meg DM og spurte «hvilken er den ekte Clever AI Humanizer?» fordi de hadde havnet på en helt annen side som prøvde å ta betalt for «pro»-funksjoner.
For å være tydelig:
- Clever AI Humanizer selv (Clever AI Humanizer — Best 100% Free Humanizer)
- Så langt jeg har sett:
- Ingen premium-nivåer
- Ingen abonnementer
- Ingen «låst opp 5 000 flere ord for $9.99»-popups
Hvis du klikket på noe fra Google Ads og endte med at kredittkortet ditt ble belastet, var det ikke dette verktøyet.
Hvordan jeg testet det (fullt ut AI mot AI)
Jeg ville se hvor langt dette kunne strekkes i et verst tenkelig scenario, så jeg ga det ingen særbehandling.
- Ba ChatGPT 5.2 skrive en fullstendig AI-generert artikkel om Clever AI Humanizer.
- Ingen menneskelige endringer.
- Rett kopi–lim inn.
- Tok den teksten og kjørte den gjennom Clever AI Humanizer i Simple Academic-modus.
- Kjørte resultatet gjennom flere AI-detektorer.
- Ba deretter ChatGPT 5.2 selv vurdere den omskrevne teksten.
På den måten finnes det ingen «men kanskje originalteksten allerede var menneskeaktig»–unnskyldning. Det er 100 % maskin til maskin.
Simple Academic-modus: hvorfor jeg valgte den vanskeligste
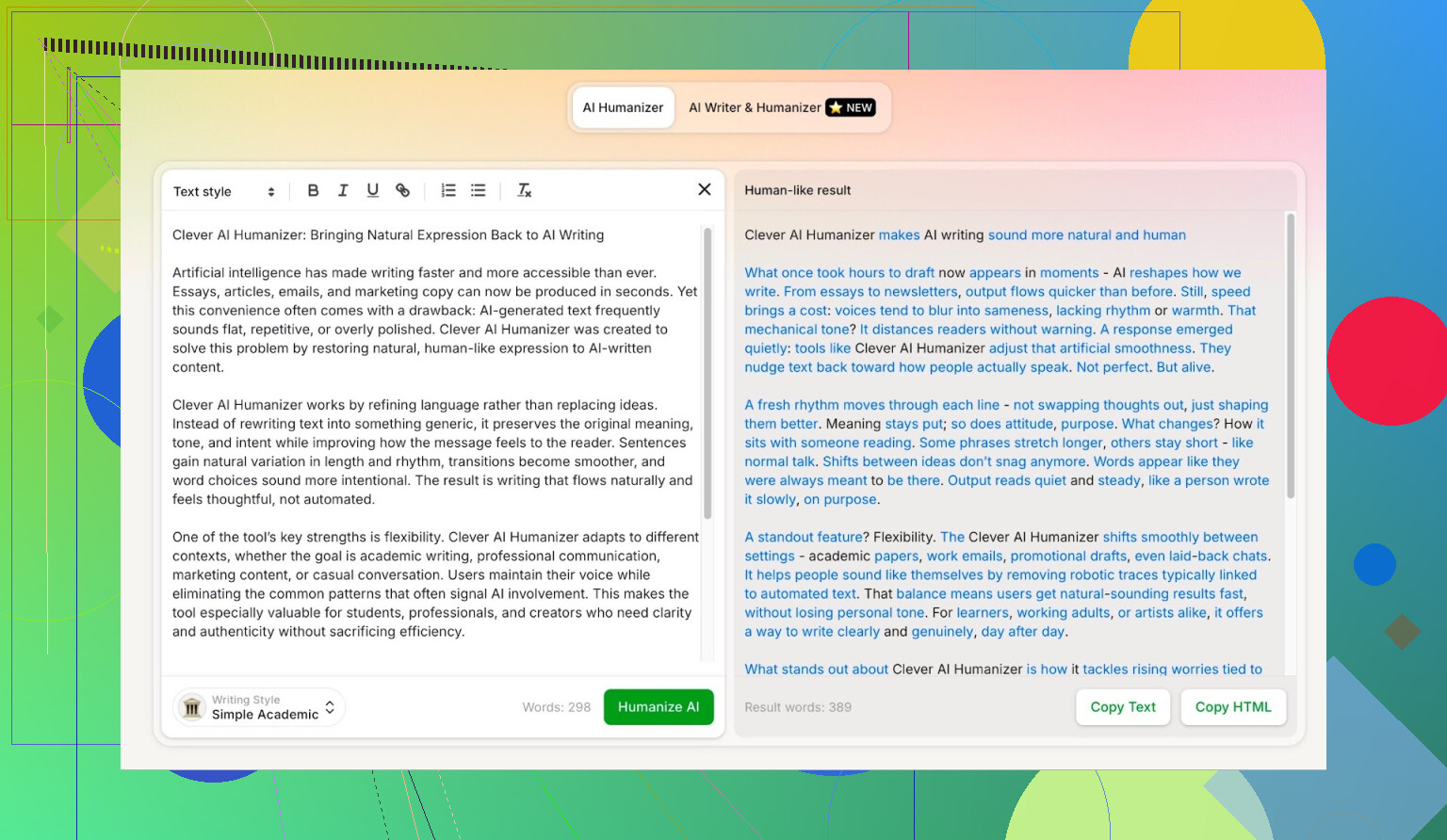
Jeg valgte ikke Casual eller Blog-stil eller noe mykt. Jeg gikk rett på Simple Academic.
Hvordan den modusen føles i praksis:
- Fortsatt lett å lese, ikke full akademisk tidsskriftsjargon
- Litt formell, strukturert og ryddig
- Nok «akademisk-aktig» språk til å høres seriøs ut, men ikke som en avhandling
Akkurat dette mellomnivået er typisk der AI-detektorer begynner å skrike «AI!» fordi setningene blir for pene og balanserte. Så hvis en humanizer kan levere denne stilen og likevel få gode scorer, er det interessant.
ZeroGPT: «Jeg stoler ikke på det, men alle bruker det»-testen
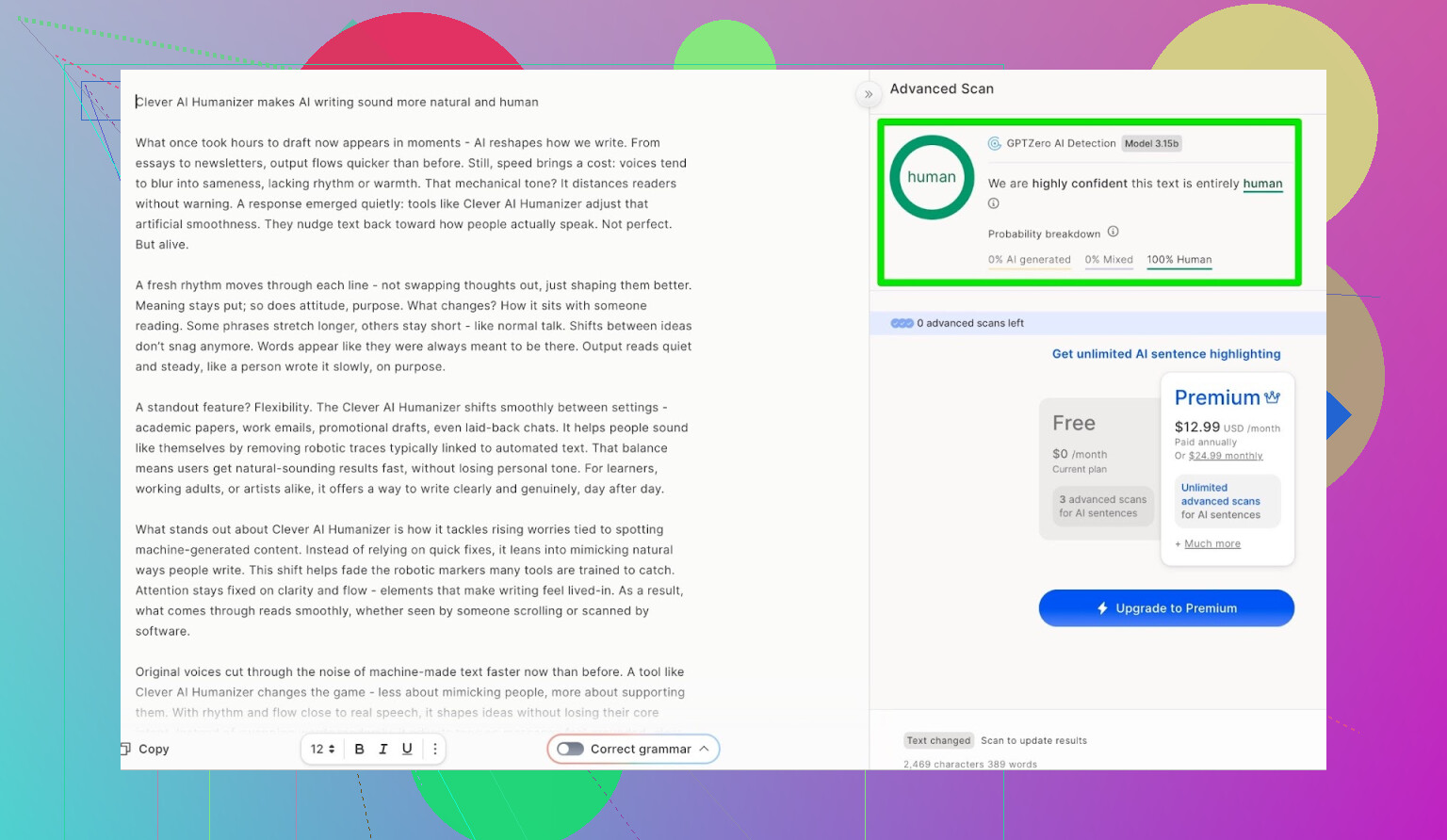
Jeg er ikke fan av ZeroGPT av én hovedgrunn: det flagger den amerikanske grunnloven som «100 % AI».
Når du har sett det, stuper tilliten rett ned.
Når det er sagt:
- Det ligger fortsatt høyt på Google.
- Folk fortsetter å bruke det fordi det er et av de første treffene.
- Så jeg tok det med.
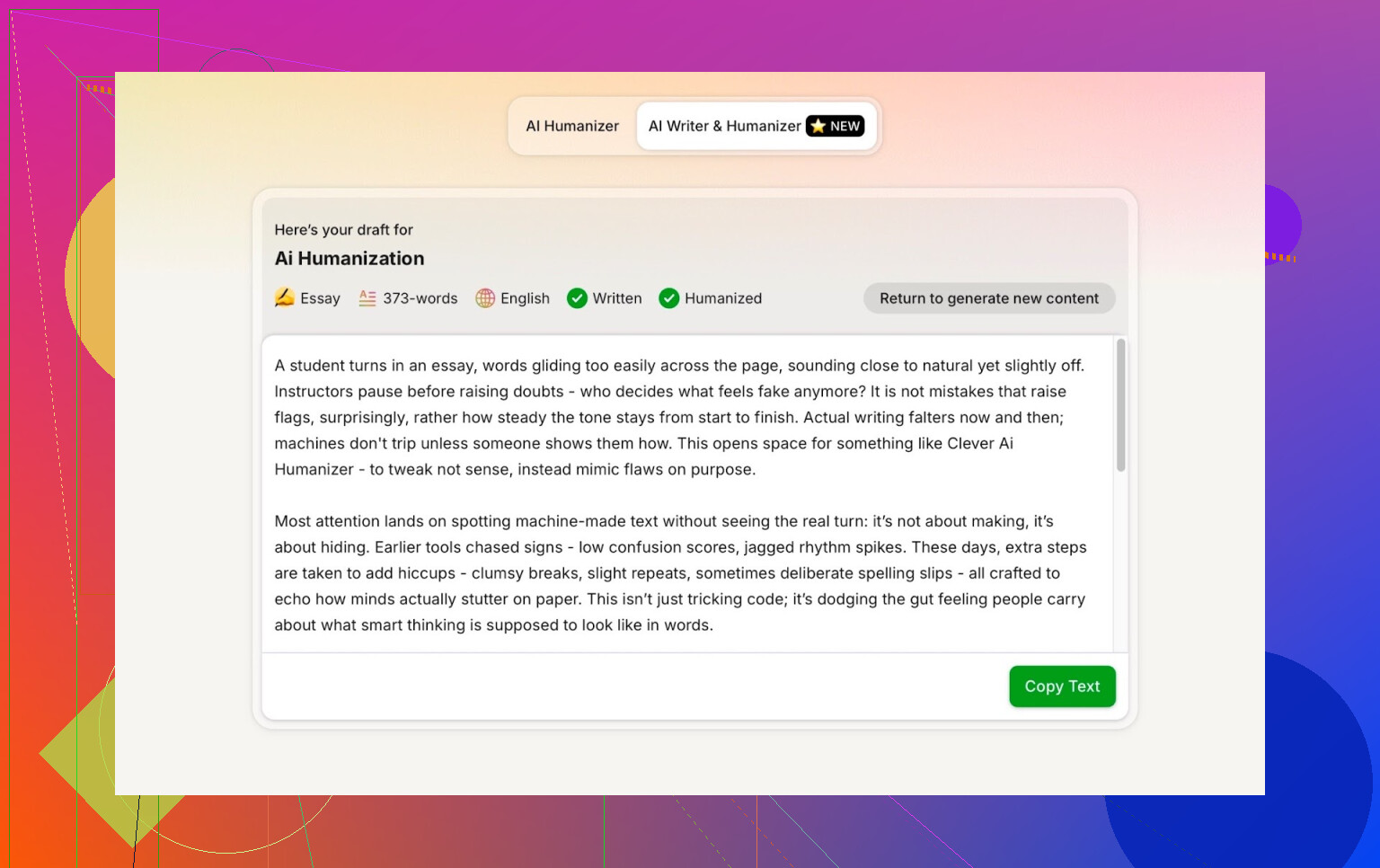
Resultat for outputen fra Clever AI Humanizer:
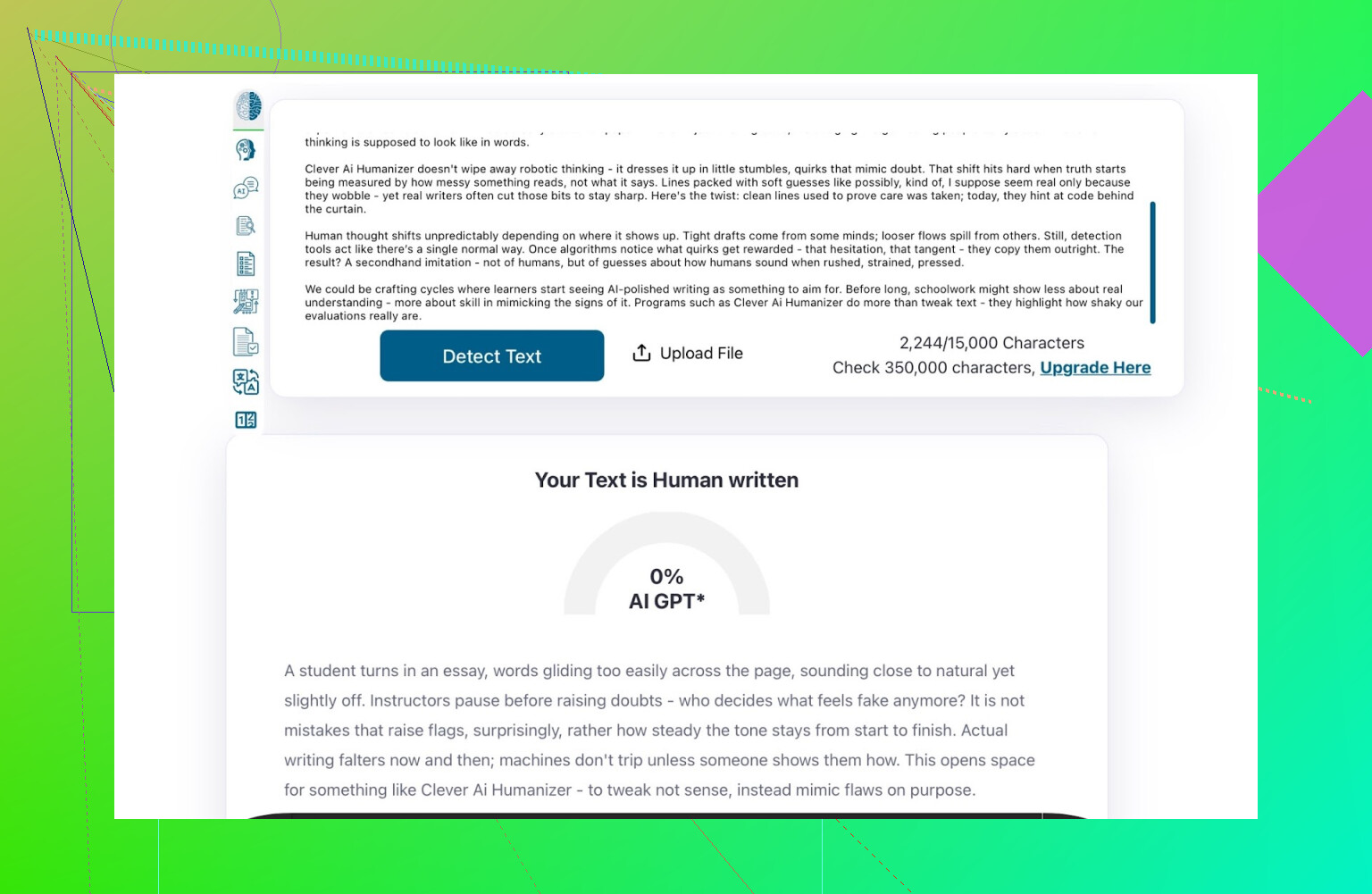
ZeroGPT: 0 % AI oppdaget.
For det det er verdt: det er omtrent så bra som det blir på det verktøyet.
GPTZero: second opinion, samme historie
Neste ut var GPTZero.
Dette brukes mye i skoler og universiteter, så det er ofte det folk er mest redd for.
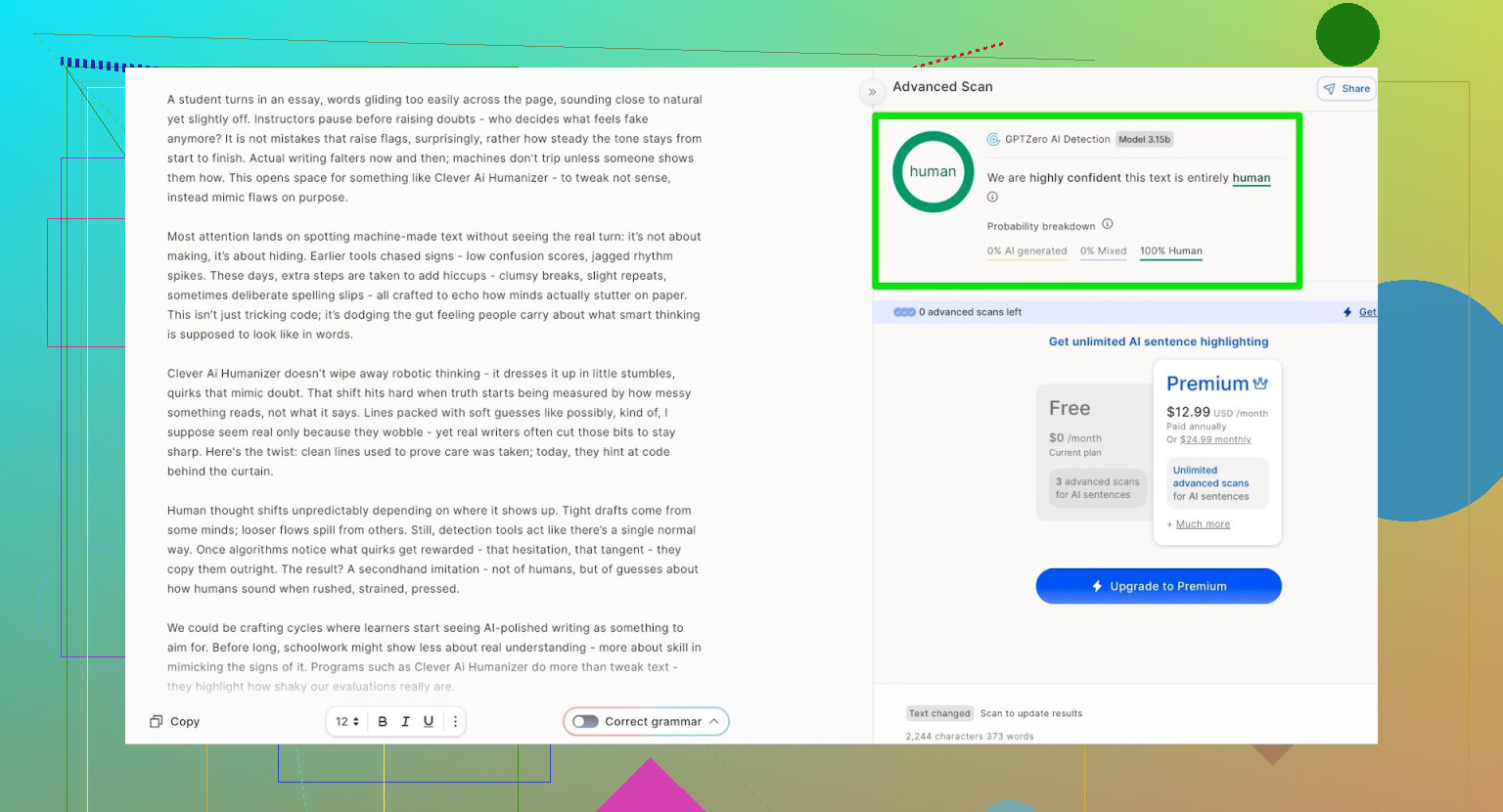
Outputen fra Clever AI Humanizer (Simple Academic-modus) kom tilbake som:
- 100 % menneskeskrevet
- 0 % AI
Så på de to mest brukte offentlige detektorene gikk teksten rett gjennom med perfekte scorer.
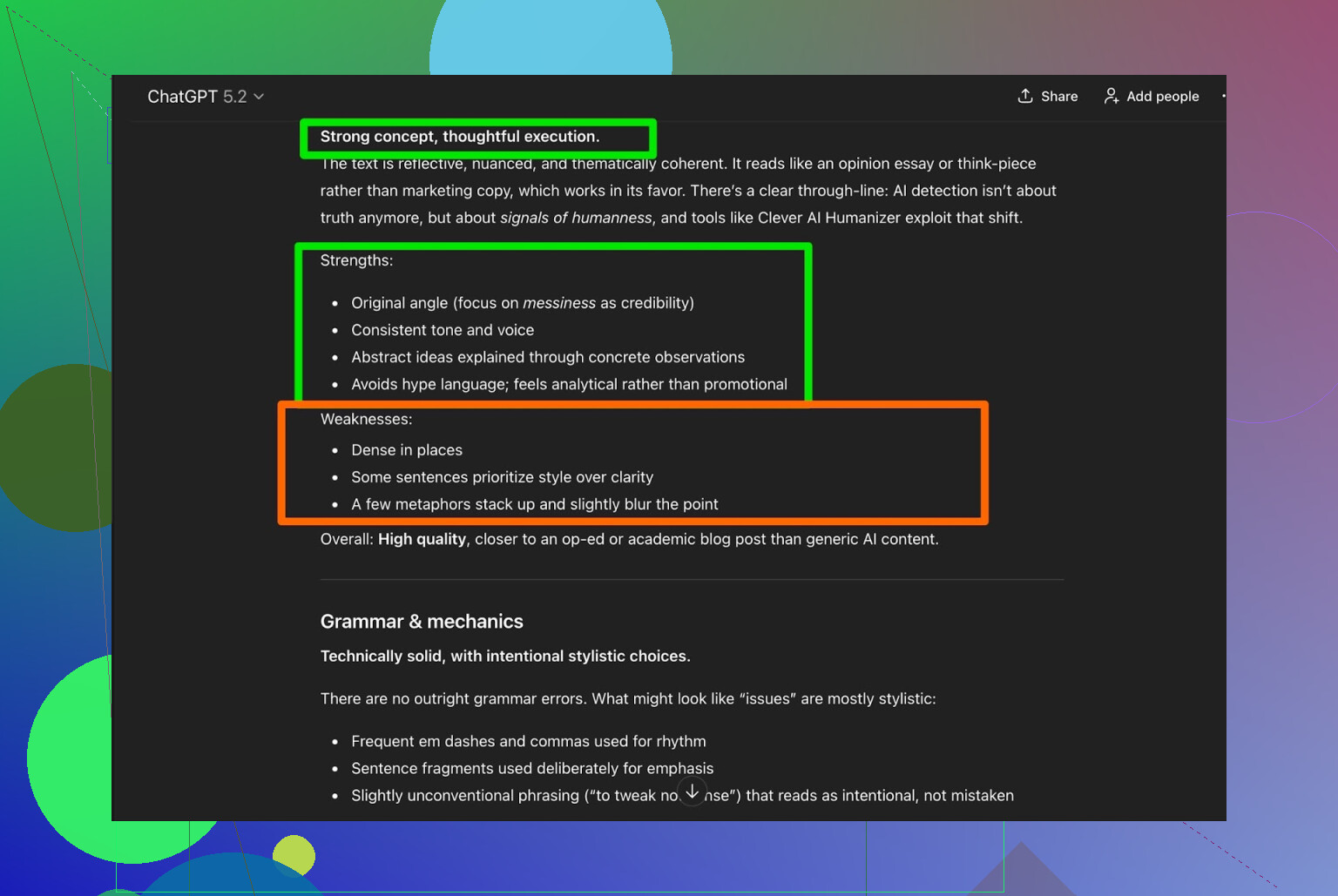
Men høres det dritt ut?
Her feiler mange humanizere:
De passerer detektorer, men teksten føles som om noen kjørte essayet ditt gjennom fire oversettelsesapper og tilbake igjen.
Jeg tok outputen fra Clever AI Humanizer og ba ChatGPT 5.2 analysere den:

Generell dom:
- Grammatikk: solid
- Stil: passer ganske godt til Simple Academic
- Anbefaling: sier fortsatt at menneskelig redigering anbefales
Ærlig talt er jeg enig. Det er bare realiteten:
All AI-skrevet eller AI-humanisert tekst har fortsatt godt av at et menneske leser den gjennom.
Hvis et verktøy hevder «ingen menneskelig redigering nødvendig», er det trolig mer markedsføring enn sannhet.
Testing AI-skriveren som er innebygd i Clever AI Humanizer
De har et eget verktøy her:
https://aihumanizer.net/noai-writer
Her blir det mer interessant. I stedet for:
LLM → Kopier → Lim inn i humanizer → Håp på det beste
Kan du:
- Generere og humanisere i ett steg
- La systemet deres styre både struktur og stil fra start
Det har noe å si fordi hvis et verktøy genererer innholdet selv, kan det forme det på en måte som naturlig unngår noen av de mest åpenbare AI-mønstrene.
Til testen gjorde jeg følgende:
- Valgte Casual skrivestil
- Tema: AI-humanisering, med omtale av Clever AI Humanizer
- La bevisst inn en liten feil i prompten for å se hvordan den håndterte det
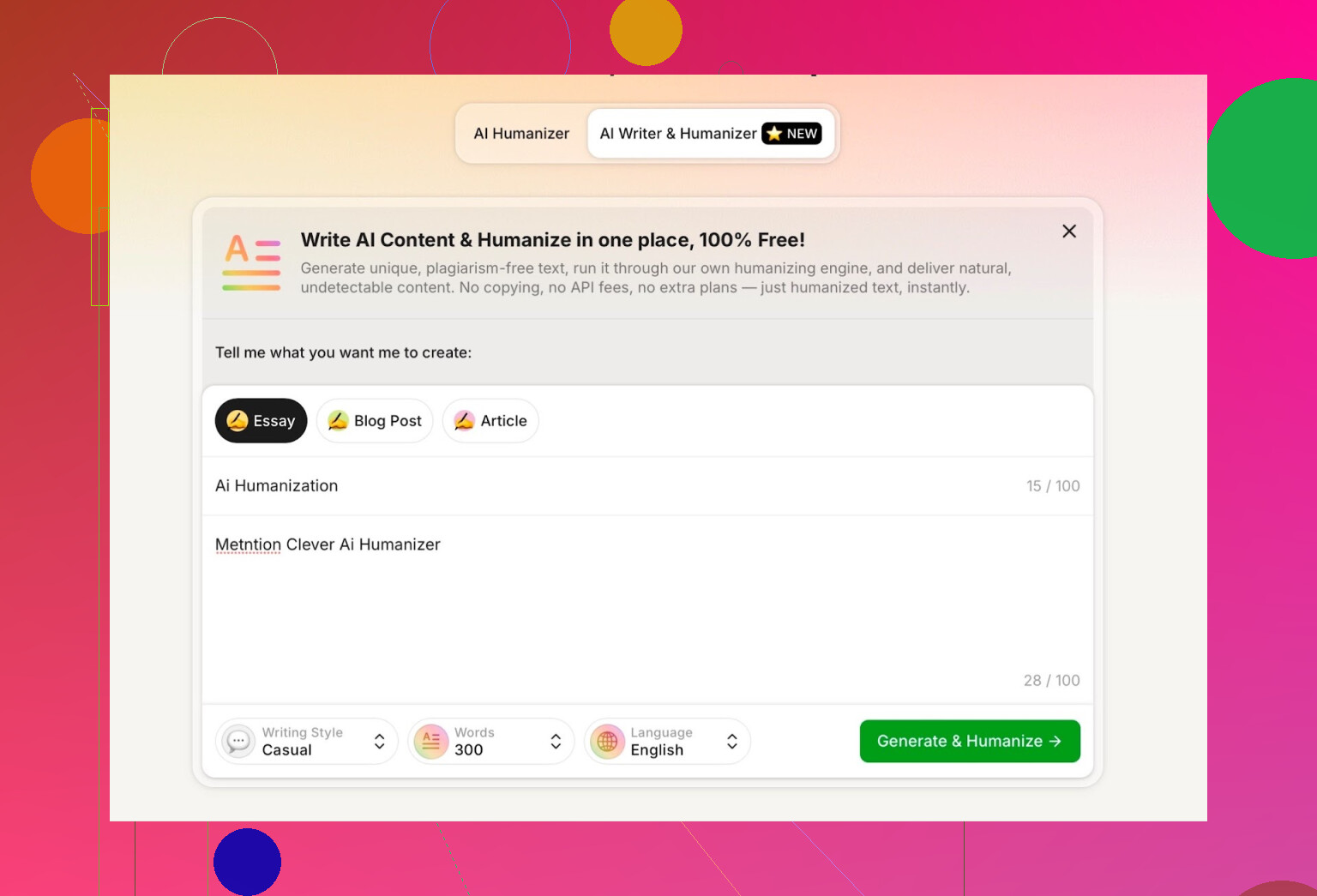
Outputen var ryddig, samtalepreget og gjentok ikke skrivefeilen min på noen rar måte.
Én ting jeg ikke likte:
- Jeg ba om 300 ord
- Den ga meg mer enn 300
Hvis jeg sier 300, vil jeg ha 300. Ikke 412. Slike ting betyr noe hvis du har strenge grenseverdier i oppgaver eller innholdsbrief.
Det er min første reelle innvending.
Deteksjonsscorer for outputen fra AI-skriveren
Jeg tok det AI-skriveren produserte og kjørte det gjennom:
- GPTZero
- ZeroGPT
- QuillBot-detektor som ekstra datapunkt
Resultater:
- GPTZero: 0 % AI
- ZeroGPT: 0 % AI, 100 % menneske
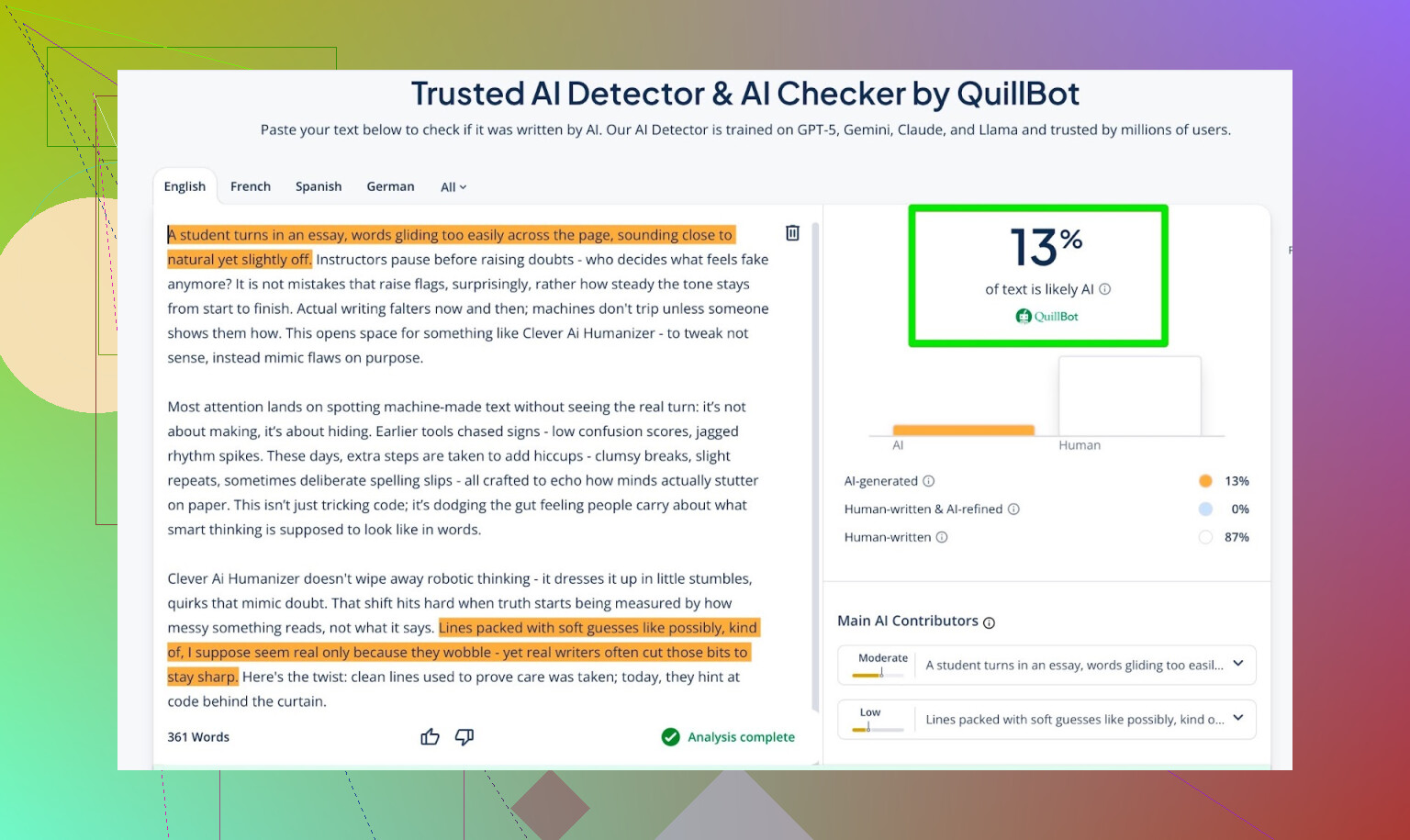
- QuillBot: 13 % AI
Så QuillBot så en liten anelse «AI-aktig» mønster, men fortsatt hovedsakelig menneskelig.
Alt i alt er det ganske bra.
Å be ChatGPT 5.2 vurdere outputen fra AI-skriveren
Så til den delen jeg egentlig brydde meg mest om: ikke bare «lurer den detektorer», men:
- Høres det ut som et menneske?
- Holder den konsistens?
- Leses det naturlig?
Jeg sendte teksten fra AI-skriveren inn i ChatGPT 5.2 og spurte om den virket menneskeskrevet eller AI-skrevet.
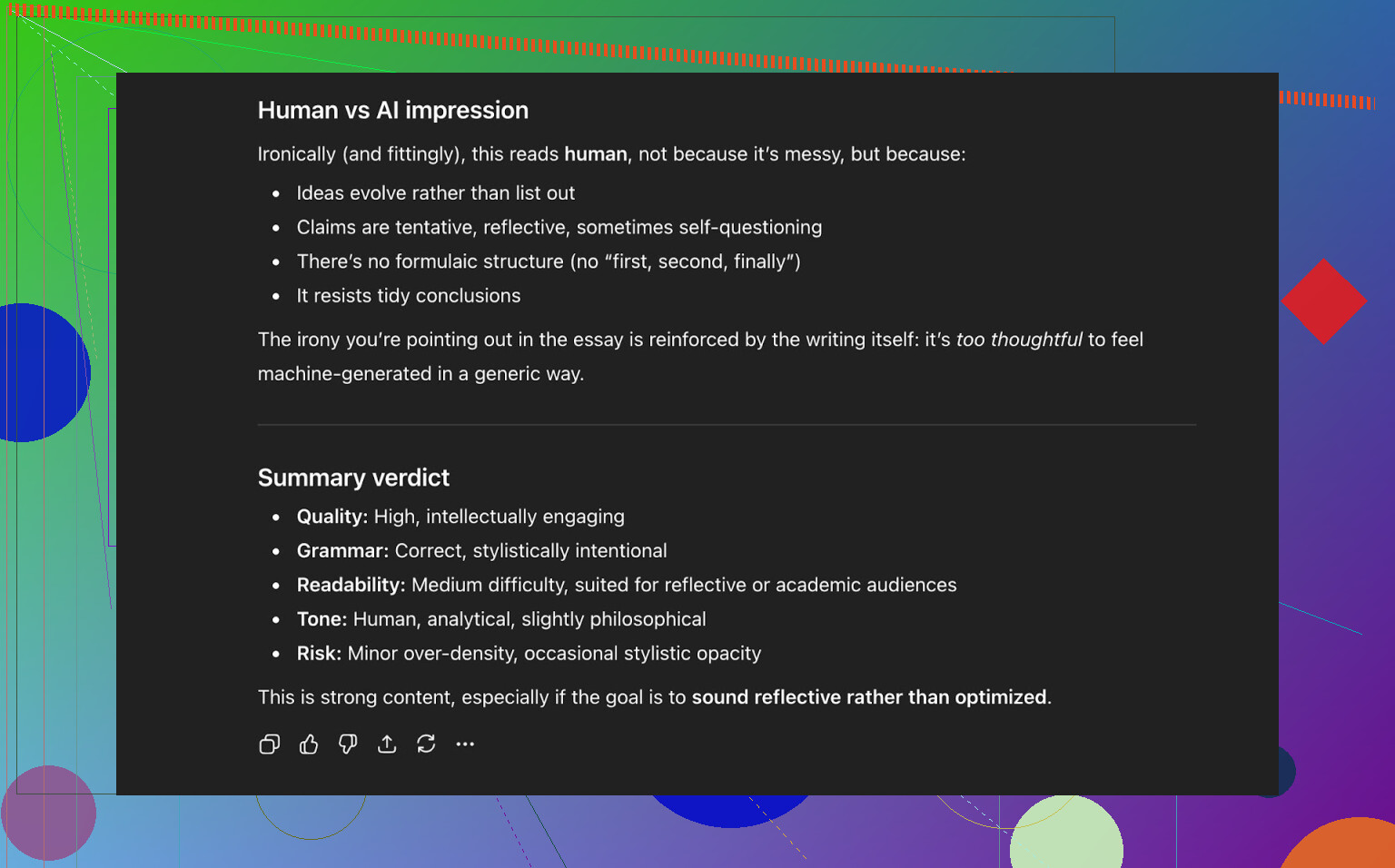
Konklusjon fra ChatGPT 5.2:
- Leses som menneskeskrevet
- Kvaliteten er sterk
- Ingenting åpenbart ødelagt i grammatikk eller struktur
Så på dette tidspunktet hadde teksten:
- Passert tre offentlige AI-detektorer fint
- Også «lurt» en moderne LLM til å klassifisere den som menneskeskrevet
Hvordan den ligger an mot andre humanizere jeg prøvde
I mine egne tester gjorde Clever AI Humanizer det bedre enn en del andre verktøy folk ofte nevner.
Her er en rask oppsummeringstabell fra de kjøringene:
| Verktøy | Gratis | AI-detektorscore |
| ⭐ Clever AI Humanizer | Ja | 6% |
| Grammarly AI Humanizer | Ja | 88% |
| UnAIMyText | Ja | 84% |
| Ahrefs AI Humanizer | Ja | 90% |
| Humanizer AI Pro | Begrenset | 79% |
| Walter Writes AI | Nei | 18% |
| StealthGPT | Nei | 14% |
| Undetectable AI | Nei | 11% |
| WriteHuman AI | Nei | 16% |
| BypassGPT | Begrenset | 22% |
Verktøy det slo i mine faktiske tester:
- Grammarly AI Humanizer
- UnAIMyText
- Ahrefs AI Humanizer
- Humanizer AI Pro
- Walter Writes AI
- StealthGPT
- Undetectable AI
- WriteHuman AI
- BypassGPT
For å være tydelig: denne tabellen er basert på detektorscorer, ikke «hvilket som subjektivt høres penest ut».
Hvor Clever AI Humanizer fortsatt svikter
Det er ikke magi, og det er ikke feilfritt.
Noen problemer jeg la merke til:
- Dårlig kontroll på ordantall
- Ber du om 300 ord, får du kanskje 280, kanskje 370.
- Mønstre kan fortsatt dukke opp
- Enkelte LLM-er kan av og til fortsatt flagge deler som AI-aktige.
- Innholdsdrift
- Det speiler ikke alltid originalen nøyaktig; av og til omskriver det mer aggressivt enn du forventer.
På den positive siden:
- Grammatisk kvalitet: rundt 8–9/10 i mine tester
- Flyter godt nok til at du ikke snubler over formuleringer annenhver linje
- Ingen irriterende strategi med «bevisste skrivefeil» som å skrive «i was» i stedet for «I was» for å lure detektorer
Det siste er viktig. Noen verktøy legger med vilje inn feil bare for å fremstå mer menneskelige. Det kan gi bedre score mot detektorer, men gjør teksten dårligere.
Det rare: 0 % AI føles ikke alltid «menneskelig»
Det er noe subtilt som er vanskelig å beskrive: selv når en tekst får 0 % AI på flere deteksjonsverktøy, kan du noen ganger føle at den er formet av en maskin. Rytmen, måten ideer introduseres på, hvor ryddig alt er.
Clever AI Humanizer gjør en bedre jobb enn de fleste, men dette underliggende mønsteret er der fortsatt innimellom. Det er egentlig ikke en kritikk av verktøyet; det er bare der hele økosystemet er nå.
Det er bokstavelig talt en katt-og-mus-lek:
- Detektorer blir smartere
- Humanizere tilpasser seg
- Detektorer oppdateres igjen
- Gjenta
Hvis du forventer at noe verktøy skal være «fremtidssikkert», blir du skuffet.
Så, er det «det beste» gratis humanizer-verktøyet akkurat nå?
For gratis verktøy jeg faktisk har testet med detektorer og LLM-sjekker:
- Jeg vil plassere Clever AI Humanizer på topp så langt.
- Spesielt når du tar med at det har både:
- En humanizer for eksisterende tekst
- En innebygd AI-skriver som humaniserer mens den skriver
Du må fortsatt:
- Lese gjennom outputen selv
- Fikse det som føles rart
- Justere tone så det høres ut som deg
Men hvis spørsmålet ditt er:
«Er Clever AI Humanizer verdt å prøve nå, spesielt siden det er gratis?»
Så er svaret mitt, basert på testene: ja.
Ekstra ting hvis du vil dykke dypere
Det finnes noen diskusjoner og tester på Reddit med flere skjermbilder og bevis:
-
Generell sammenligning av de beste AI-humanizerne med deteksjonsresultater:
https://www.reddit.com/r/DataRecoveryHelp/comments/1oqwdib/best_ai_humanizer/?tl=no -
En spesifikk tråd med fokus på Clever AI Humanizer:
https://www.reddit.com/r/DataRecoveryHelp/comments/1ptugsf/clever_ai_humanizer_review/?tl=no
Hvis du bestemmer deg for å teste Clever AI Humanizer, ville jeg fortsatt behandlet det som:
- En hjelper, ikke en erstatning
- Noe som tar deg 70–90 % av veien
- Et verktøy som bare er så godt som mennesket som vurderer sluttresultatet
Du må fortsatt være den som står for ordene.
Kort svar: du kommer ikke til å få den typen «ærlig tilbakemelding fra ekte brukere» du vil ha bare ved å se på detectorscore eller spørre andre KI-er hva de mener. Det er én del av bildet, men også den lateste delen.
Du har allerede sett at @mikeappsreviewer kjørte detector‑olympiske leker og strukturerte tester. Nyttig, men det forteller deg fortsatt ikke hvordan verktøyet ditt føles når noen er trøtte kl. 01 og prøver å bli ferdig med en oppgave, eller når en innholdsansvarlig batch‑prosesserer 20 artikler og er på randen av å si opp.
Hvis du vil ha signal fra virkelige brukssituasjoner, gjør ting som dette:
-
Bygg inn tilbakemelding i selve bruken
- Etter hver kjøring: 3‑klikk mikroundersøkelse:
- «Hørtes ut som: [Altfor robotaktig] [Ganske naturlig] [Veldig menneskelig]»
- «Var denne teksten trygg å levere inn som den er? [Ja/Nei]»
- Så en bitteliten valgfri tekstboks: «Hva irriterte deg?»
- Ikke spør «Hva likte du?» Da får du bare falsk skryt. Spør hva som sugde.
- Etter hver kjøring: 3‑klikk mikroundersøkelse:
-
Følg atferd, ikke bare meninger
- Mål:
- Hvor ofte brukere trykker «generer på nytt»
- Hvor ofte de straks redigerer teksten i editoren din (hvis du har en)
- Frafall midt i økten
- Hvis folk genererer på nytt 3–4 ganger per input, forteller verktøyet deg at det feiler, selv om undersøkelsene ser positive ut.
- Mål:
-
Kjør målrettede tester med ekte brukere i stedet for tilfeldig trafikk
Ta små, spesifikke grupper i stedet for «internett»:- Studenter som prøver å unngå AI‑flagg
- Frilansskribenter/innholdsbyråer
- Ikke‑native engelsktalende som finpusser tekst
Tilby dem: - Et privat testområde
- Et knippe faste oppgaver (skriv om essay‑innledning, puss LinkedIn‑innlegg, osv.)
- 10–15 minutters samtale eller skjermopptak for hver
Bestikk med Amazon‑gavekort, gratis premiumbruk, hva som helst. Den kvalitative tilbakemeldingen du får fra 20 slike personer slår 2 000 anonyme klikk.
-
A/B‑test verktøyet ditt mot en baseline
I stedet for å spørre «Er dette bra?» spør «Er dette bedre enn X?»
Du kan i det skjulte kjøre:- Versjon A: rå LLM‑output
- Versjon B: den humaniserte outputen din
Vis dem blindt til testere og spør: - «Hvilken høres mest ut som at et ekte menneske har skrevet den?»
- «Hvilken ville du faktisk levert/postet?»
Du trenger ikke engang å nevne detektorer her.
-
Bruk «fiendtlige» anmeldere med vilje
Finn folk som hater AI‑innhold eller er superpicky redaktører.
Si til dem:- «Tenk at en juniorskribent har levert dette til deg. Riv det i filler.»
Notatene deres om stemme, gjentakelser, stivhet og logisk flyt er mye mer verdifulle enn «ZeroGPT sier 0 % AI».
- «Tenk at en juniorskribent har levert dette til deg. Riv det i filler.»
-
Dogfoode det offentlig, men ærlig
Bruk output fra Clever AI Humanizer på:- Produktteksten på nettsiden
- Release notes
- Blogginnlegg
Legg så til en liten linje nederst:
«Dette innlegget ble utkastet med Clever AI Humanizer og lett redigert av et menneske. Var det noe som føltes rart? Gi oss beskjed.»
Du får brutal, rå tilbakemelding fra folk som bryr seg nok til å klage. -
Test «feilmodusene», ikke bare «beste case»
De fleste verktøy ser greie ut på pen, formell tekst. Du bør teste:- Kaotiske prompt
- Brutt engelsk
- Slang, emojier, rar formatering
- Korte ting som emnefelt i e‑post
Spør brukerne: - «Hvor bommet den fullstendig?»
Loggfør og kategoriser disse feilene.
-
Se opp for «vibe‑problemet»
Selv når detektorer viser 0 % AI, «føles» mye tekst fortsatt maskinformet: samme rytme, pen avsnittsstruktur, forutsigbare overganger.
Det fanger du ikke med detektorer.
Du vil fange det hvis du:- Spør brukere: «Høres dette ut som deg?»
- Lar dem lime inn «før» og «etter», og så spør hvilken de faktisk ville sendt til sjefen eller foreleseren.
-
Ikke overfokuser på å omgå detektorer
Litt uenig med den detector‑fokuserte vinklingen til @mikeappsreviewer her: brukere tror de vil ha «0 % AI», men på sikt er det som holder på dem:- Det matcher tonen deres
- Det introduserer ikke løgner
- Det får dem ikke til å høres ut som en merkelig, generisk blogger
Sett brukeropplevelse først, «udetekterbarhet» som nummer to. Ellers lenker du deg til en katt‑og‑mus‑lek du til slutt kommer til å tape.
-
Legg til et brutalt ærlig «kvalitetsmeter» for deg selv
Internt, merk hver kjøring (anonymisert) med:
- Detectorscore
- Menneskelig vurdering (fra et lite panel du stoler på)
- Brukerfeedback («irritasjonsnotater»)
Hver måned går du gjennom de dårligste 5–10 % av outputen. Det er der gullet ligger.
Hvis du vil ha et konkret neste steg:
- Lag en liten «beta‑tester»‑side på Clever AI Humanizer.
- Sett tak på, si, 50 ekte brukere.
- Gi dem en tydelig avtale: «Bruk det gratis, men du må sende 3 eksempler i uken på der det sugde eller føltes rart.»
Du mangler egentlig ikke brukere. Du mangler strukturert, smertefull tilbakemelding. Bygg rørledningene for det, og du lærer mer på to uker enn av 20 nye skjermbilder av detectordashboards.
Kort svar: skjermbilder fra detektorer + AI‑egenvurderinger er ikke «ekte brukerfeedback», de er et labb‑eksperiment. Du er halvveis der, men du spør feil publikum.
Et par tanker som ikke bare gjentar det @mikeappsreviewer og @kakeru allerede har sagt:
-
Slutt å spørre om det «funker» og begynn å spørre for hvem det funker
Akkurat nå jager du litt et universelt svar: «Er AI‑humanizeren min bra?» Det er vagt. I praksis finnes det veldig ulike brukstilfeller:
- Studenter som prøver å unngå å bli flagget
- Innholdsskribenter som vil gjøre utkast mindre robotaktige
- Ikke‑innfødte som vil høres mer naturlige ut på e‑post
- Markedsførere som vil bevare merkevarens stemme
Feedbackproblemet ditt kan være: du slipper inn alle og lytter ikke til noen spesifikk gruppe. Velg én eller to segmenter og optimaliser feedback‑sløyfene rundt dem.
-
Tilby meningsbærende presets, og døm etter hvilken som blir misbrukt mest
I stedet for generiske modi som «enkel akademisk» eller «uformell», stram dem inn rundt virkelige situasjoner:
- «Pussing av college‑essay»
- «LinkedIn thought‑leadership»
- «Kald e‑post til leder»
- «Fikse blogg‑intro»
Deretter:
- Spor hvilken preset som brukes mest
- Spor hvilken som oftest får «kopier alt» uten endringer
- Spor hvilken brukerne forlater midt i flyten
Hvis «Pussing av college‑essay» får masse bruk, men folk forsvinner etter én kjøring, har du spesifikk, handlingsbar feildata. Det er bedre enn enda et skjermbilde fra en detektor.
-
Bygg inn en «Min stemme vs humanisert stemme»‑sammenligning
Her er jeg litt uenig i den tunge detektorfokuseringen fra andre: på sikt bryr folk seg mer om stemme enn 0 % AI. Hvis teksten slutter å høres ut som dem selv, dropper de verktøyet selv om det er «udetekterbart».
La brukerne:
- Lime inn originaltekst
- Få humanisert resultat
- Se en kjapp diff‑aktig oversikt:
- «Formalitet: +20 %»
- «Personlig tone: -30 %»
- «Setningslengde: +15 %»
Spør deretter bokstavelig talt:
«Høres dette fortsatt ut som deg?» [Ja / Litt / Nei]
Det spørsmålet alene gir deg mer ærlig signal enn «Vurder 1–5 stjerner».
-
Du trenger negative insentiver, ikke bare bestikkelser
Alle snakker om gavekort, betafordeler osv. Problemet: folk vil si det du vil høre for å beholde fordelene.
Prøv dette:
- «Hvis du sender oss 3 virkelig dårlige outputs (skjermbilder eller lim inn), låser vi opp X ekstra kreditter.»
- Du belønner ikke «å bruke verktøyet mye», du belønner «å finne der det feiler».
Det holder fokuset på svake punkter i stedet for vage «ja det er bra, takk»‑kommentarer.
-
Lag en intern «Hall of Shame»
Du vet allerede at verktøyet kan prestere bra under ideelle forhold. Det du ikke har, er en kuratert bunke med:
- Verste outputs
- Mest kleine setninger
- Ganger der det endret mening
- Ganger der det fikk en bruker til å høres ut som en generisk AI‑blogger
Hver uke, trekk ut:
- De 50 øktene med flest raske regenereringer
- De 50 med raskest lukking etter output
Inspiser manuelt 10–20 av dem og merk hvorfor de var dårlige. Det mønsteret er hvordan du forbedrer deg.
-
Tving inn friksjon i én del av trakten
Du optimaliserer sannsynligvis for «ingen innlogging, superkjapt, lav friksjon». Flott for trafikk, elendig for feedback.
Vurder en egen «Pro feedback sandbox»:
- Krever e‑post eller minimal registrering
- Gir høyere grenser eller ekstra modi
- Til gjengjeld:
- Huker brukeren av 2 bokser per output: «Naturlig / Robotaktig» og «On topic / Skle ut»
- Valgfritt å lime inn kontekst som «Jeg brukte dette til [skole / jobb / sosiale medier]»
Folk som bruker 20 sekunder på å registrere seg er mye mer tilbøyelige til å gi reell feedback enn tilfeldige forbipasserende.
-
Bygg forventninger direkte inn i grensesnittet
Lett uenighet med den uutalte antakelsen du kanskje bærer på: «Hvis det er godt nok, skal brukerne kunne klikke kopier og gå videre.» Det er ikke sånn ekte folk bruker slike verktøy.
Legg bokstavelig inn tekst som:
«Dette får deg 70–90 % av veien. Du må gi det en kjapp menneskelig gjennomlesning før du sender inn.»
Spør deretter direkte:
- «Måtte du fortsatt redigere dette mye?» [Litt / Mye / Skrev det praktisk talt om]
Det er ærlig feedback som ikke krever et langt skjema.
- «Måtte du fortsatt redigere dette mye?» [Litt / Mye / Skrev det praktisk talt om]
-
Bruk sammenligning med konkurrenter uten å være klein
Siden folk åpenbart også tester ting som Grammarlys humanizer, Ahrefs, Undetectable osv., kan du utnytte det i stedet for å late som de ikke finnes.
Legg til en liten avkrysningsboks:
- «Har du prøvd lignende verktøy (som Grammarly eller Ahrefs AI‑humanizere)?
- Ja, og dette er bedre
- Ja, og dette er dårligere
- Cirka det samme
- Har ikke prøvd andre»
Ingen merkesløying, ingen «vi er best»‑hype. Bare data.
Bruk det til å forstå posisjonering, ikke bare kvalitet. - «Har du prøvd lignende verktøy (som Grammarly eller Ahrefs AI‑humanizere)?
-
Slutt å anta at detektorsuksess = produktsuksess
Basert på det @mikeappsreviewer viste, er Clever AI Humanizer allerede solid mot offentlige detektorer. Kult. Men spør deg selv:
- «Hvis alle detektorer forsvant i morgen, ville verktøyet mitt fortsatt vært verdt å bruke?»
Hvis det ærlige svaret er «ikke egentlig», bør veikartet ditt vris mot:
- Personalisering
- Tonestyring
- Sikkerhet (ingen hallusinasjoner, ingen usanne påstander)
- Bevaring av opprinnelig mening
Det er det som overlever når detektor‑kappløpet roer seg.
-
Posisjoner Clever AI Humanizer eksplisitt som et samarbeidsverktøy
Du får mye bedre feedback hvis du slutter å late som det er en usynlighetskappe.
Eksempel i UI:
«Utkastet av AI, raffinert av Clever AI Humanizer, fullført av deg.»
Det får brukerne til å tenke:
- «Hva hjalp det meg med?»
- «Hvor gjorde det livet mitt vanskeligere?»
Be om feedback i den rammen:
- «Sparte Clever AI Humanizer deg for tid her?» [Ja / Nei]
- «Endret den meningen din?» [Ja / Nei]
Krysset mellom «Sparte ikke tid» + «Endret meningen min» er der du feiler hardest.
Hvis du vil ha et veldig praktisk grep du kan implementere på en dag:
- Etter hver output viser du 3 knapper:
- «Jeg ville sendt dette som det er»
- «Jeg ville brukt dette, men trenger å redigere»
- «Dette er ikke brukbart»
- Hvis de velger den siste, still ett enkelt oppfølgingsspørsmål:
- «For robotaktig / Utenfor tema / Feil tone / Dårlig engelsk / Annet»
Den lille flyten, i skala, vil fortelle deg mer om reell ytelse i virkeligheten for Clever AI Humanizer enn en måned til med detektortester eller å spørre andre LLM‑er om de blir «lurt».
Rask analytisk vurdering fra en litt annen vinkel, siden andre allerede har gått dypt inn i UX og testing:
1. Behandle “ekte tilbakemelding” som data, ikke meninger
I stedet for flere tester med detektorer, koble på harde måltall rundt Clever AI Humanizer:
Kjernetall å følge med på:
- Fullføringsrate: tekst limt inn → humaniser → kopier.
- Regenereringsrate per input: mange regenereringer = misnøye.
- Tid-til-kopi: hvis folk kopierer innen 2–5 sekunder, leser de ikke, de “farmer”.
- Redigeringsintensjon: klikk på “Kopier med formatering” vs “Kopier ren tekst” vs “Last ned”. Ulike mønstre tilsvarer som regel ulike brukstilfeller.
Det gir deg stille tilbakemelding fra hver økt, ikke bare fra de få som gidder å skrive lange kommentarer.
2. Lettvekts-kohortmerking
Andre foreslo personamålretting. Jeg ville gjort det brutalt enkelt:
Ved første bruk, en 1-klikk-velger over boksen:
- “Bruker dette til: Skole / Jobb / Sosialt / Annet”
Ingen innlogging, ingen friksjon. Bare lagre et anonymt kohortmerke.
Da kan du se:
- Skole: høyest regenerering og frafall
- Jobb: lengst tid på siden, men høy kopieringsrate
- Sosialt: rask kopi, lav lengde, kanskje ikke verdt å optimalisere
Du gjetter ikke lenger hvilken målgruppe du bommer på.
3. A/B-test “aggressiv vs konservativ” humanisering
Akkurat nå føles Clever AI Humanizer optimalisert for detektor-unngåelse pluss lesbarhet. Det er greit, men ulike brukere vil ha ulike grader av redigering.
Kjør en stille splittest:
- Versjon A: minimale endringer, bevarer struktur, lett parafrase
- Versjon B: tyngre omskriving, mer variasjon, større rytmeendringer
Sammenlign så:
- Hvilken versjon får flest “kopier og gå”-handlinger
- Hvilken versjon utløser mest “Kjør igjen”-bruk
Ingen spørreundersøkelser, ingen masing om tilbakemeldinger. Atferden gir svaret.
4. Fordeler/ulemper som produktrealitetssjekk
Sammenlignet med det @kakeru og @andarilhonoturno beskrev, mener jeg verktøyet ditt allerede ligger i “bedre enn gjennomsnittet”-gruppen, men det hjelper å sette navn på ting:
Fordeler med Clever AI Humanizer
- Sterk ytelse mot vanlige AI-detektorer når den testes på realistisk innhold.
- Outputen leses som regel ren og grammatisk uten den tvungne “typo-spam”-trikset noen verktøy bruker.
- Flere stiler (enkel akademisk, uformell osv.) som samsvarer ganske godt med faktiske skrivemiljøer.
- Integrert AI-skriver som kan generere og humanisere i én operasjon, noe som reduserer åpenbare LLM-fingeravtrykk.
- Gratis og lett onboarding, som er bra for tidlig adopsjon og gir rikelig med testdata i trakten.
Ulemper med Clever AI Humanizer
- Ordantallkontroll er slapp, noe som er et reelt problem for strenge oppgaver og brief.
- Av og til omskriver den for aggressivt og introduserer meningsglidning som brukerne ikke alltid oppdager.
- Selv med 0 % AI-score føles noen tekster fortsatt “maskinformet” i struktur og rytme.
- Detektorfokusert verdiforslag setter deg i et konstant katt-og-mus-spill og kan eldes dårlig.
- Lite eksplisitt stemmepersonalisering, så hyppige brukere kan oppleve at skrivingen deres begynner å låte lik.
5. Slutt å overtilpasse til detektorer, begynn å overtilpasse til faste brukere
Her er jeg litt uenig i det tunge detektorfokuset som vises i testene til @mikeappsreviewer. Skjermbilder fra detektorer er nyttig markedsføring, men et skjørt produktmål.
Mer holdbar signal:
- Hvor mange brukere kommer tilbake innen 7 dager
- Blant returbrukere, hvor mange økter vokser i ordantall over tid (tillits-signal)
- Hvor ofte samme nettleser / IP bruker verktøyet i ulike kontekster (skole + jobb osv.)
Ekte brukere blir ikke værende fordi en detektor sa “0 % AI”. De blir fordi:
- Det sparte dem tid.
- Det gjorde dem ikke flaue.
- Det endret ikke det de mente.
Optimaliser for gjentatt bruk først, detektorscore deretter.
6. Bygg et “tillitsmønster” i stedet for et “kamuflasjemønster”
Du bør ikke prøve å slå alle fremtidige detektorer. Du bør prøve å være verktøyet som:
- Holder semantikken intakt.
- Lar tonen være justerbar.
- Dokumenterer begrensninger tydelig.
En subtil UI-tillegg som lønner seg:
- Etter output, vis en kort, ærlig oppsummering som:
- “Meningsbevaring: høy”
- “Toneskifte: moderat”
- “Setningsstrukturendring: høy”
Folk begynner å stole på deg fordi du viser hvordan du jobber. Den tilliten gir deg indirekte bedre tilbakemeldinger enn noen spørreundersøkelse.
7. Hvordan få kvalitativ tilbakemelding uten å mase
Lån atferdsbaserte triggere:
-
Hvis brukeren kjører 3+ regenereringer på samme input:
- Vis en liten inline-oppfordring:
- “Får du ikke det du trenger? Si det med 5 ord.” [lite tekstfelt]
Det gir brutalt ærlige kommentarer som “for robotaktig”, “endret påstanden min”, “for ordrik”.
- “Får du ikke det du trenger? Si det med 5 ord.” [lite tekstfelt]
- Vis en liten inline-oppfordring:
-
Hvis brukeren bruker >40 sekunder på å redigere tekst i tekstboksen før humanisering:
- Spør: “Fikser du AI-tekst eller finpusser du din egen skriving?”
Det hjelper deg å forstå om Clever AI Humanizer oppfattes som “AI-fikser” eller “redaktør”, noe som betyr mye for veikartet.
- Spør: “Fikser du AI-tekst eller finpusser du din egen skriving?”
Ingen store modaler, ingen “gi oss 5 stjerner”, bare små, kontekstsensitive dytt.
8. Hvor konkurrenter passer inn i tankemodellen din
Du har allerede god sammenligningsjobb fra folk som @kakeru og den mer detektortunge gjennomgangen fra @mikeappsreviewer. Bruk dem som referanser, men ikke som ledestjerner.
Behandle andre som:
- “Dette er hva som skjer når du skrur opp detektor-unngåelse og ignorerer stemme.”
- “Dette er hva som skjer når du gjør lett parafrasering og holder deg trygg, men lett å oppdage.”
Clever AI Humanizers fortrinn ligger i å balansere lesbarhet og deteksjon. Ditt neste fortrinn bør være personalisering og kontroll, ikke bare lavere prosenter på nok en offentlig detektor.
Hvis du vil ha én konkret ting å lansere denne uken som både vil forbedre produktet og gi deg ekte signaler fra virkelige brukere:
- Legg til to brytere før humanisering:
- “Bevar struktur mest mulig”
- “Endre struktur for mer menneskelig variasjon”
Logg så hvilken kombinasjon som korrelerer med:
- Høyere kopieringsrate
- Færre regenereringer
- Flere retursesjoner
Da vil du raskt vite hvilken type “humanisering” de faktiske brukerne dine egentlig vil ha, i stedet for å gjette ut fra detektordiagrammer.