Eu desenvolvi uma ferramenta inteligente de humanização de IA que deve deixar o texto gerado por IA mais natural e autêntico, mas estou com dificuldade para conseguir feedback honesto de usuários reais. Gostaria de saber como ela se sai no uso real: o texto realmente soa humano, é confiável para redação de conteúdo e SEO, e em quais pontos ela falha ou parece claramente feito por IA? Preciso de um feedback detalhado e prático para que eu possa corrigir problemas, melhorar a qualidade e garantir que seja segura e confiável para blogueiros, profissionais de marketing e usuários comuns que querem conteúdo de IA com aparência humana.
Humanizador de IA Clever: minha experiência real, com provas
Andei brincando com um monte de ferramentas de “humanização de IA” ultimamente, principalmente porque eu via muita gente no Discord e no Reddit perguntando quais ainda funcionam. Várias quebraram, viraram SaaS pago do dia para a noite ou simplesmente ficaram piores.
Então decidi começar por ferramentas que são realmente grátis, sem login, sem cartão. A primeira da lista: Clever AI Humanizer.
Você pode encontrar aqui:
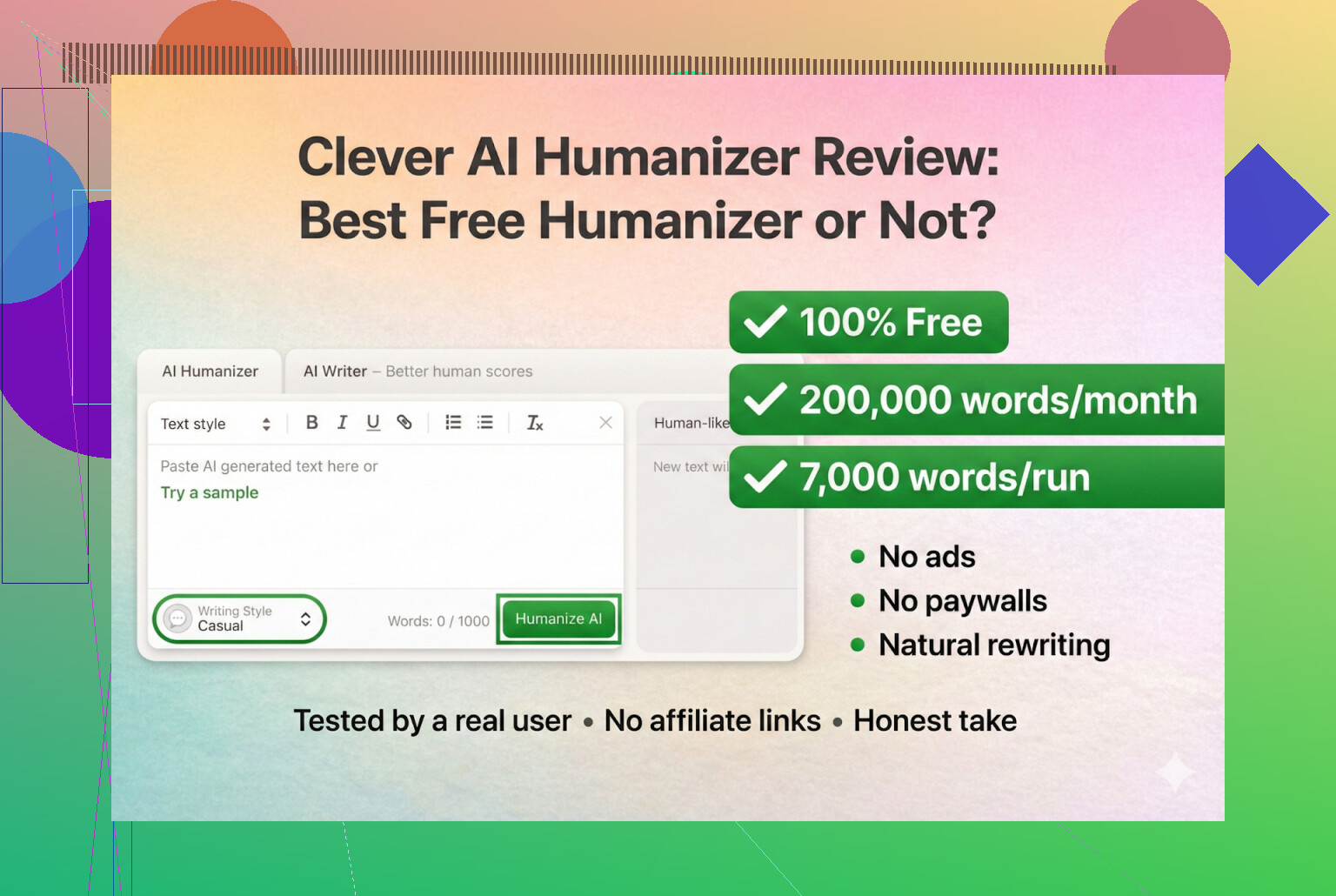
Clever AI Humanizer — Best 100% Free Humanizer
Pelo que consigo ver, este é o original mesmo, não é clone, nem rebrand estranho.
A confusão de URL e as cópias falsas
Um pequeno aviso, porque eu mesmo já caí nessa: existem vários sites de “AI humanizer” usando nomes parecidos e comprando anúncios para a mesma palavra-chave. Algumas pessoas me mandaram DM perguntando “qual é o Clever AI Humanizer de verdade?” porque caíram em outro site totalmente diferente que tentava cobrar por recursos “pro”.
Para deixar claro:
- O próprio Clever AI Humanizer (Clever AI Humanizer — Best 100% Free Humanizer)
- Pelo que eu vi:
- Sem planos premium
- Sem assinatura
- Sem pop-up “desbloqueie mais 5.000 palavras por R$ 9,99”
Se você clicou em algo do Google Ads e viu seu cartão de crédito sendo usado, não era essa ferramenta.
Como eu testei (totalmente IA contra IA)
Quis ver até onde a ferramenta aguenta em cenário de pior caso, então não peguei leve.
- Pedi ao ChatGPT 5.2 para escrever um artigo totalmente em IA sobre o Clever AI Humanizer.
- Sem edição humana.
- Copiar e colar direto.
- Peguei esse texto e rodei no Clever AI Humanizer no modo Simple Academic.
- Rodei o resultado em vários detectores de IA.
- Depois pedi para o próprio ChatGPT 5.2 avaliar o texto reescrito.
Assim não tem aquela desculpa de “ah, mas talvez o texto original já estivesse bem humanizado”. É 100% máquina para máquina.
Modo Simple Academic: por que escolhi a opção mais difícil
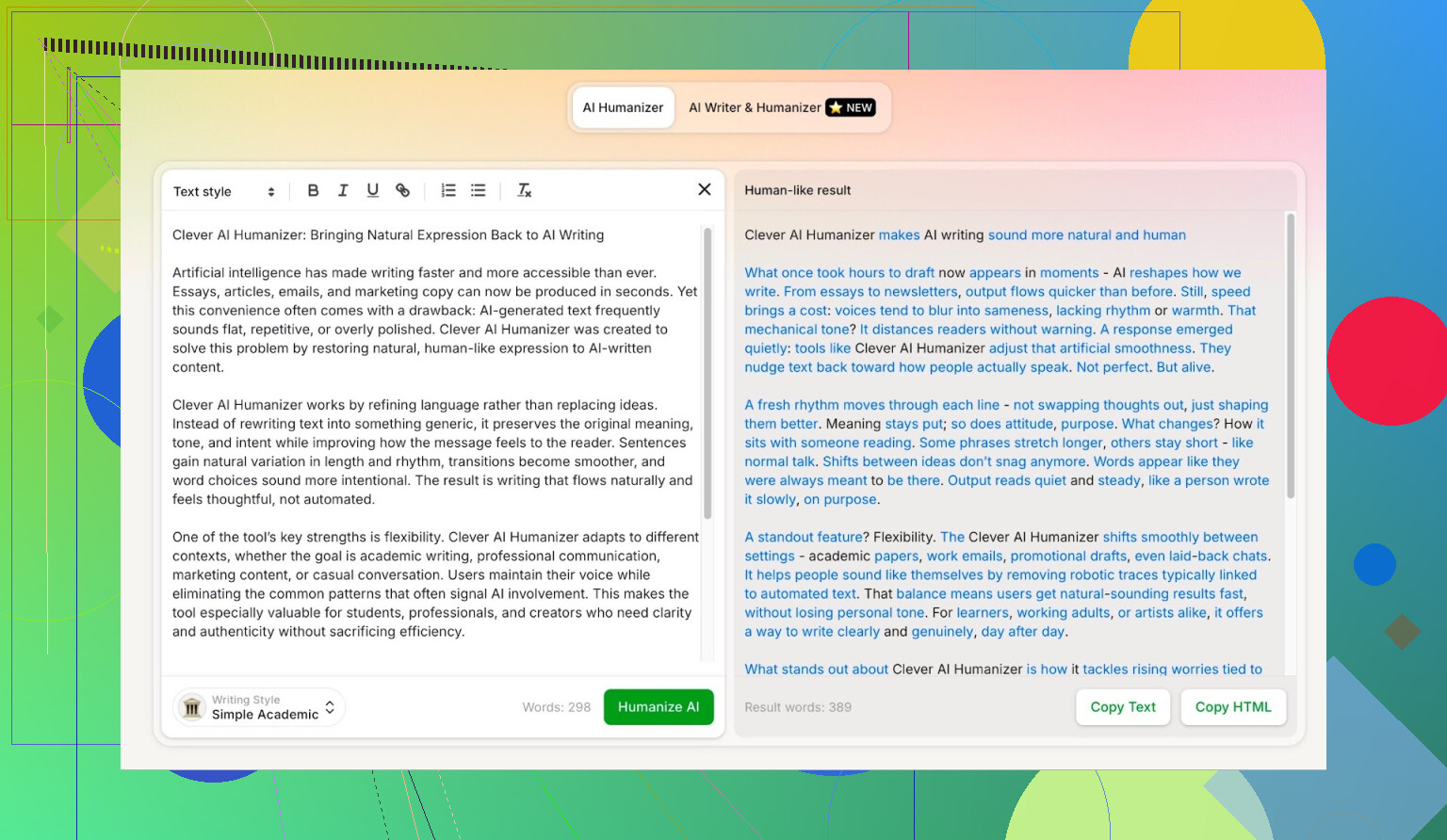
Não escolhi Casual, Blog, nem nada mais leve. Fui direto no Simple Academic.
Na prática, esse modo é assim:
- Ainda legível, sem jargão pesado de artigo científico
- Um pouco mais formal, estruturado e arrumado
- Com frases “meio acadêmicas” o suficiente para soar sério, mas sem cara de tese
Esse meio-termo é exatamente onde os detectores de IA costumam gritar “IA!” porque as frases ficam certinhas demais. Então, se um humanizador consegue segurar esse estilo e ainda pontuar bem, isso chama atenção.
ZeroGPT: o teste do “não confio, mas todo mundo usa”
Não sou fã do ZeroGPT por um motivo principal: ele marca a Constituição dos EUA como “100% IA”.
Depois que você vê isso, a confiança vai ladeira abaixo.
Dito isso:
- Ainda aparece em tudo que é busca no Google.
- Muita gente continua usando porque é um dos primeiros resultados.
- Então incluí no teste.
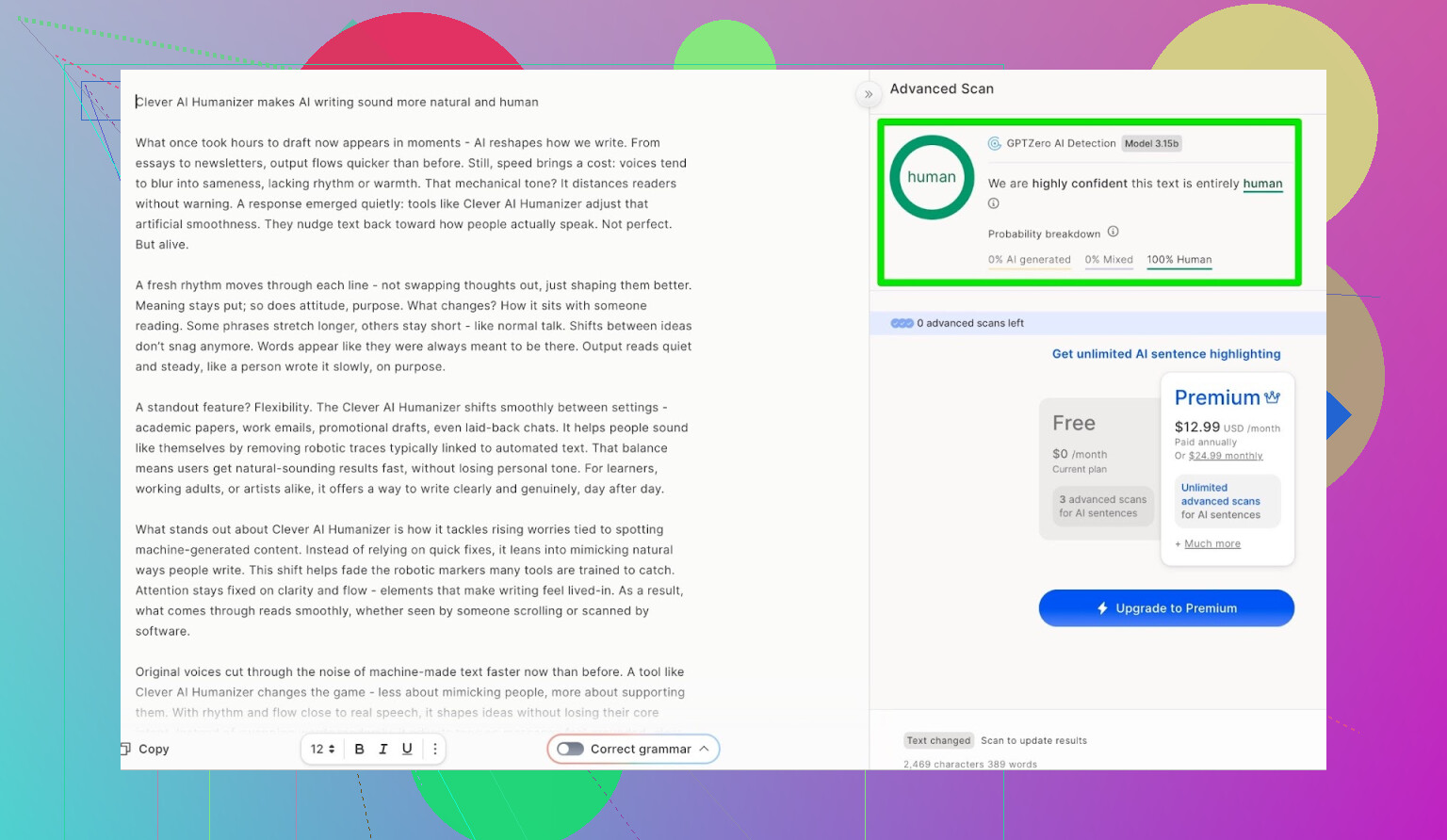
Resultado para o texto gerado pelo Clever AI Humanizer:
ZeroGPT: 0% de IA detectada.
Dentro do que a ferramenta oferece, é basicamente o melhor cenário possível.
GPTZero: segunda opinião, mesma história
Depois fui para o GPTZero.
Esse é amplamente usado em escolas e universidades, então costuma ser o que mais assusta as pessoas.
O texto do Clever AI Humanizer (modo Simple Academic) voltou como:
- 100% escrito por humano
- 0% IA
Então, nos dois detectores públicos mais usados, o texto passou com pontuação perfeita.
Mas o texto fica horrível de ler?
Aqui é onde muitos humanizadores falham:
Eles passam nos detectores, mas o texto parece que foi jogado em 4 tradutores automáticos e voltou.
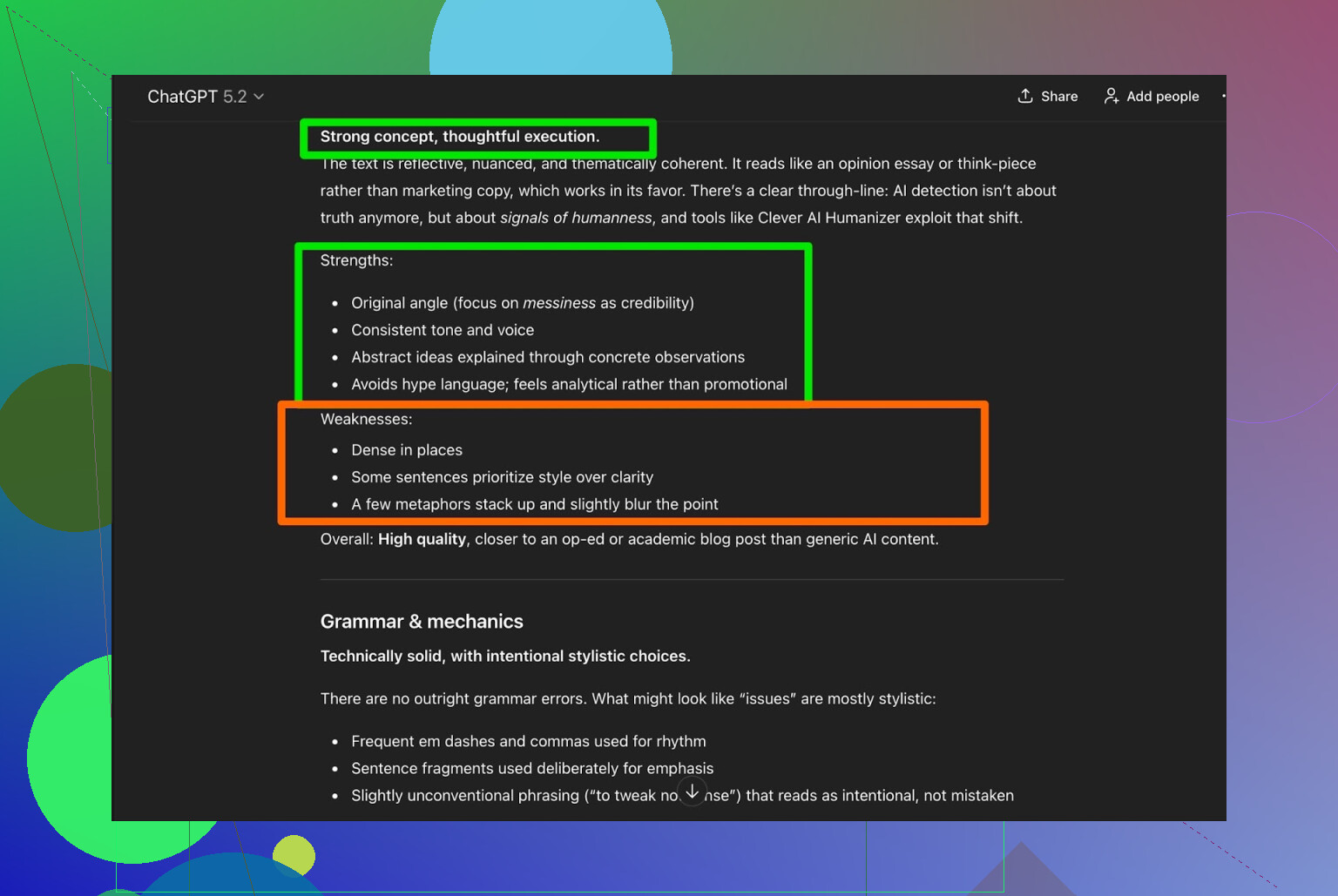
Peguei o texto do Clever AI Humanizer e pedi para o ChatGPT 5.2 analisar:

Resumo geral:
- Gramática: sólida
- Estilo: combina razoavelmente com Simple Academic
- Recomendação: ainda diz que uma edição humana é recomendada
Sinceramente, concordo. Essa é a realidade:
Qualquer texto escrito por IA ou “humanizado” por IA ainda se beneficia de uma leitura humana.
Se alguma ferramenta disser “não precisa de revisão humana”, provavelmente é marketing, não verdade.
Testando o AI Writer integrado ao Clever AI Humanizer
Eles têm uma ferramenta separada aqui:
https://aihumanizer.net/brai-writer
É aqui que fica mais interessante. Em vez de:
LLM → Copiar → Colar no Humanizer → Torcer para dar certo
Você pode:
- Gerar e humanizar em um único passo
- Deixar o sistema controlar estrutura e estilo desde o começo
Isso importa porque, se a ferramenta gera o conteúdo por conta própria, ela já pode moldar o texto de um jeito que evita alguns padrões óbvios de IA.
Para o teste, eu:
- Selecionei o estilo Casual
- Tema: humanização de IA, mencionando o Clever AI Humanizer
- Coloquei de propósito um pequeno erro no prompt para ver como lidava com isso
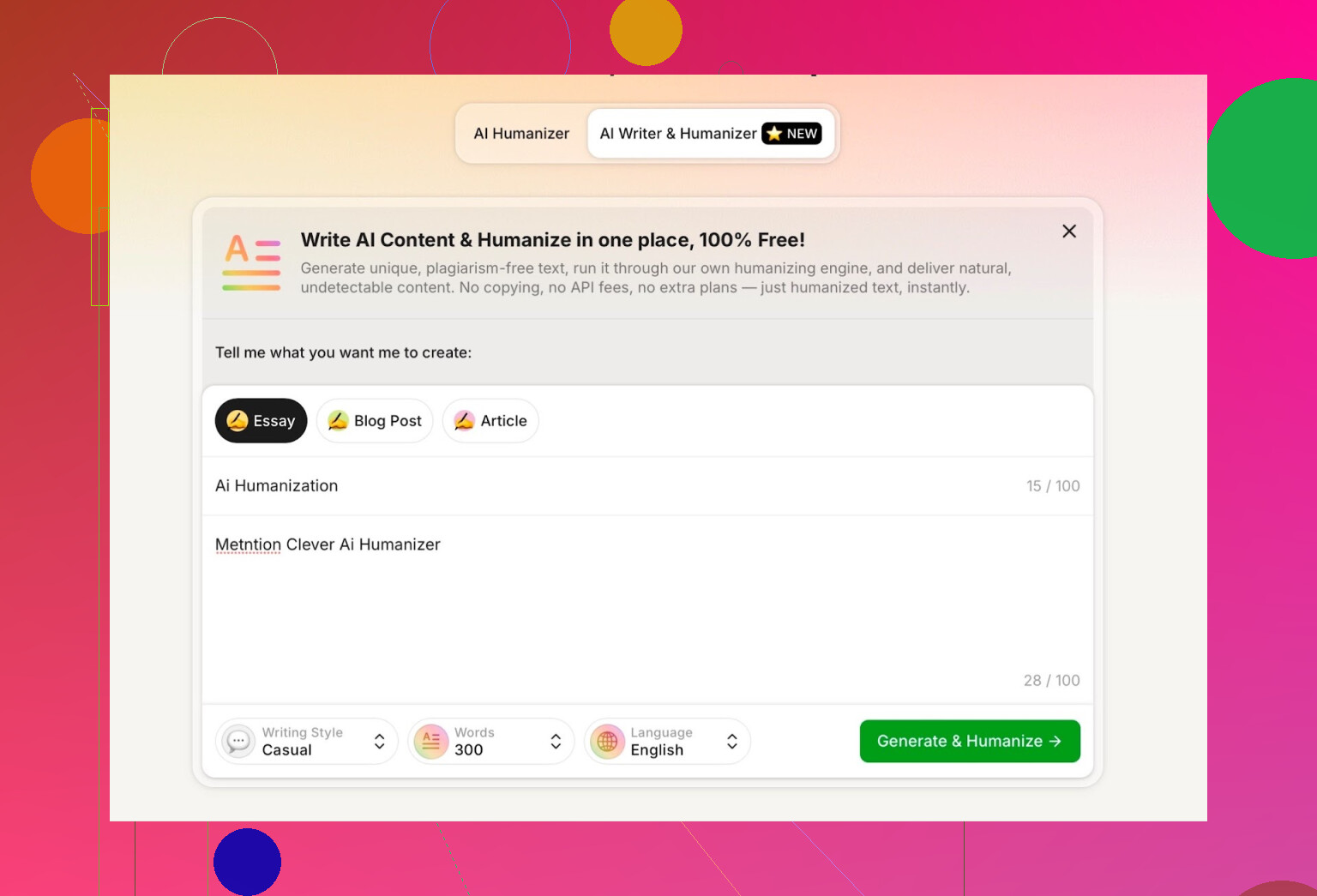
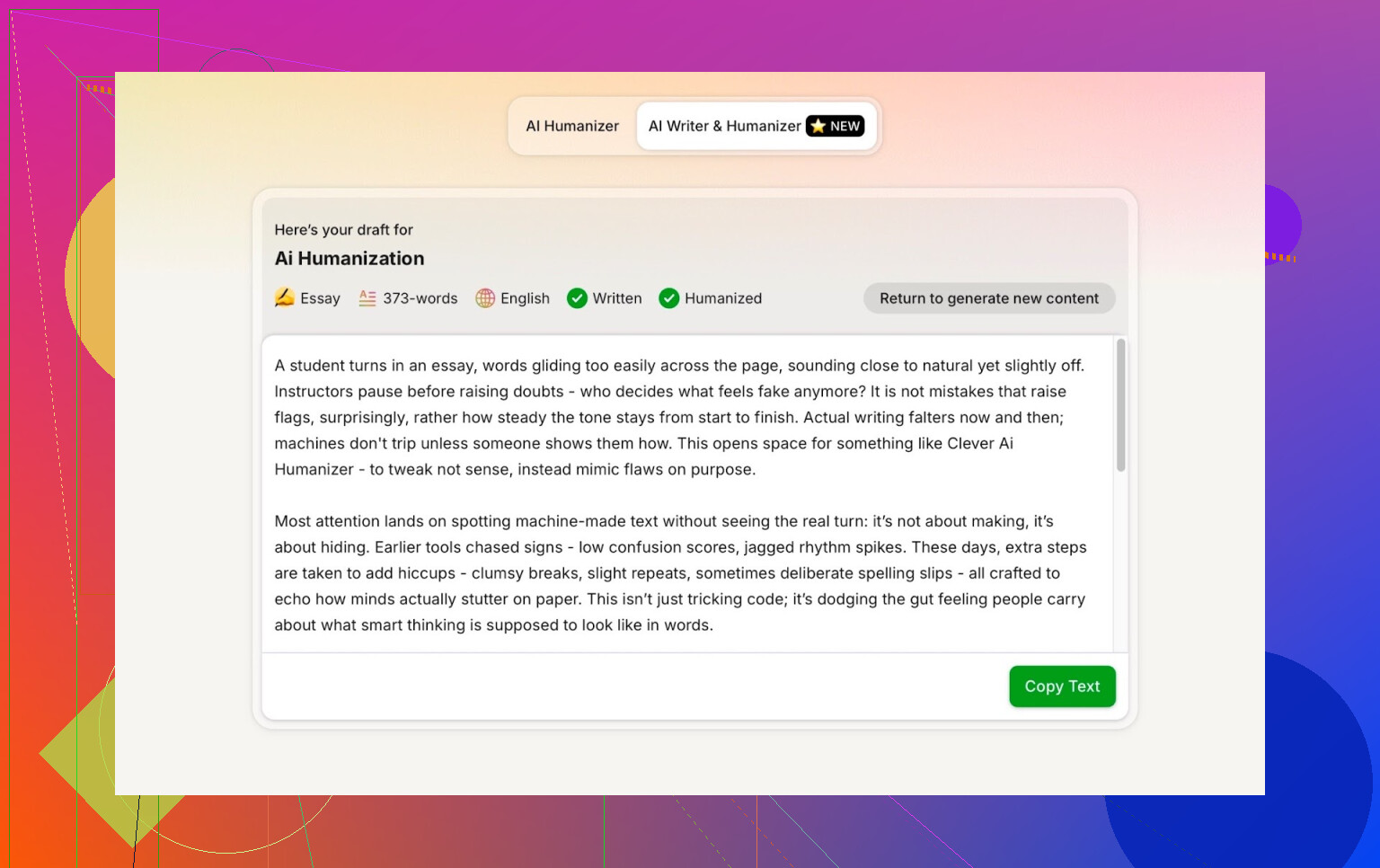
O resultado saiu limpo, conversacional e não repetiu meu erro de digitação de forma esquisita.
Uma coisa de que não gostei:
- Pedi 300 palavras
- Entregou mais de 300
Se eu peço 300, quero 300. Não 412. Esse tipo de coisa importa se você tiver limite rígido de trabalho escolar ou de briefing de conteúdo.
Esse foi meu primeiro ponto de crítica real.
Pontuações nos detectores para o texto do AI Writer
Peguei o que o AI Writer gerou e rodei em:
- GPTZero
- ZeroGPT
- Detector da QuillBot como dado extra
Resultados:
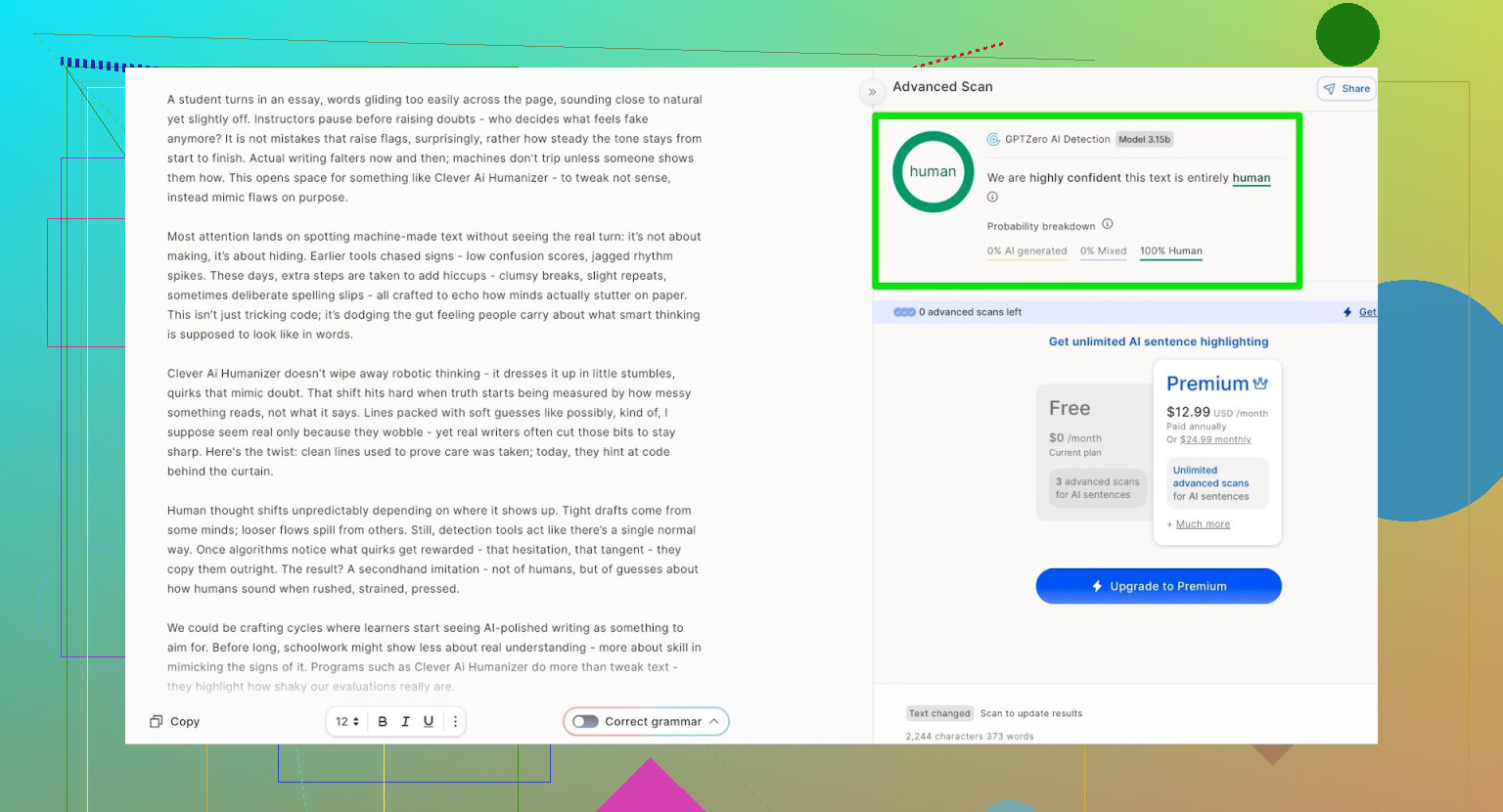
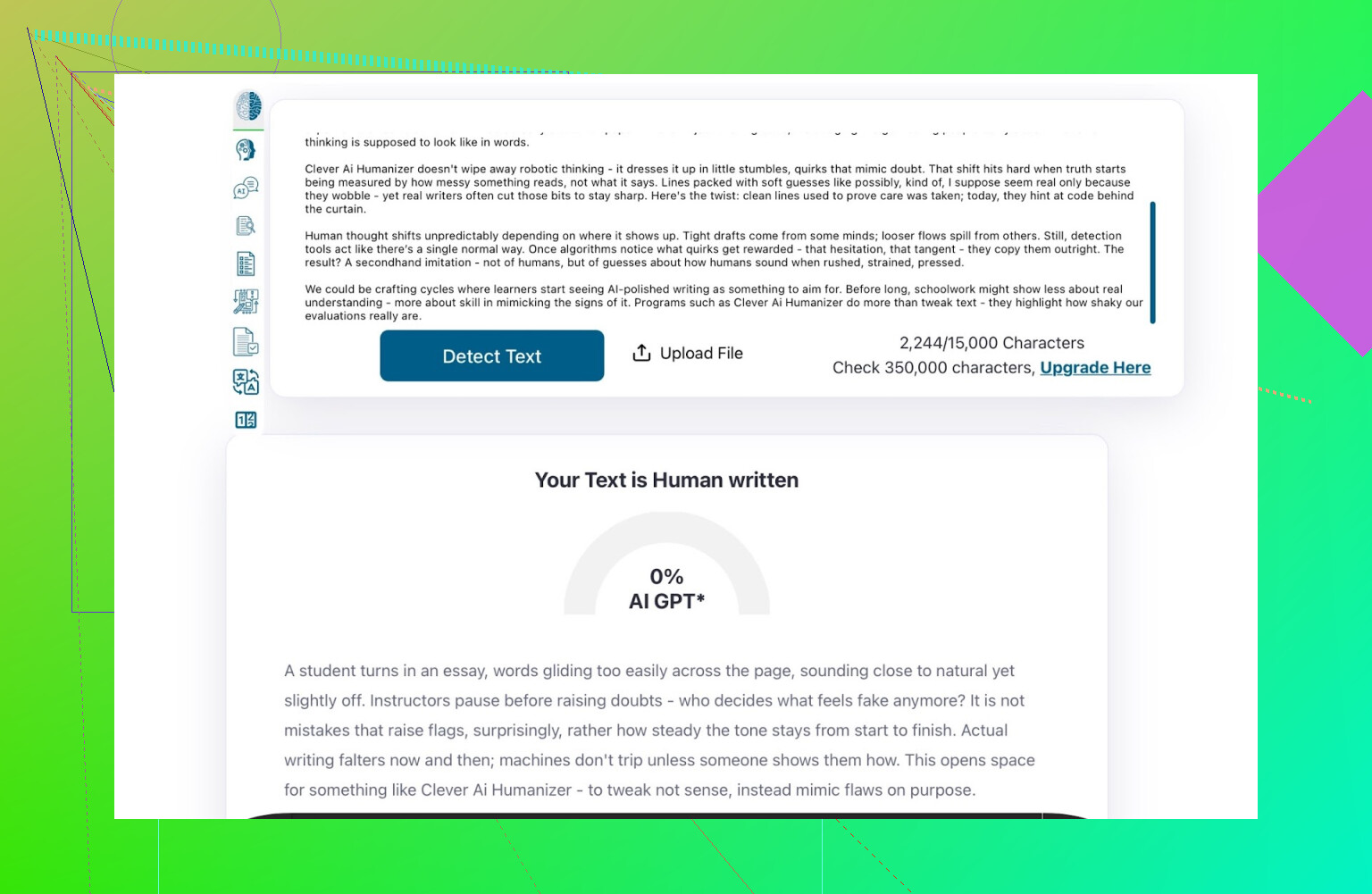
- GPTZero: 0% IA
- ZeroGPT: 0% IA, 100% humano
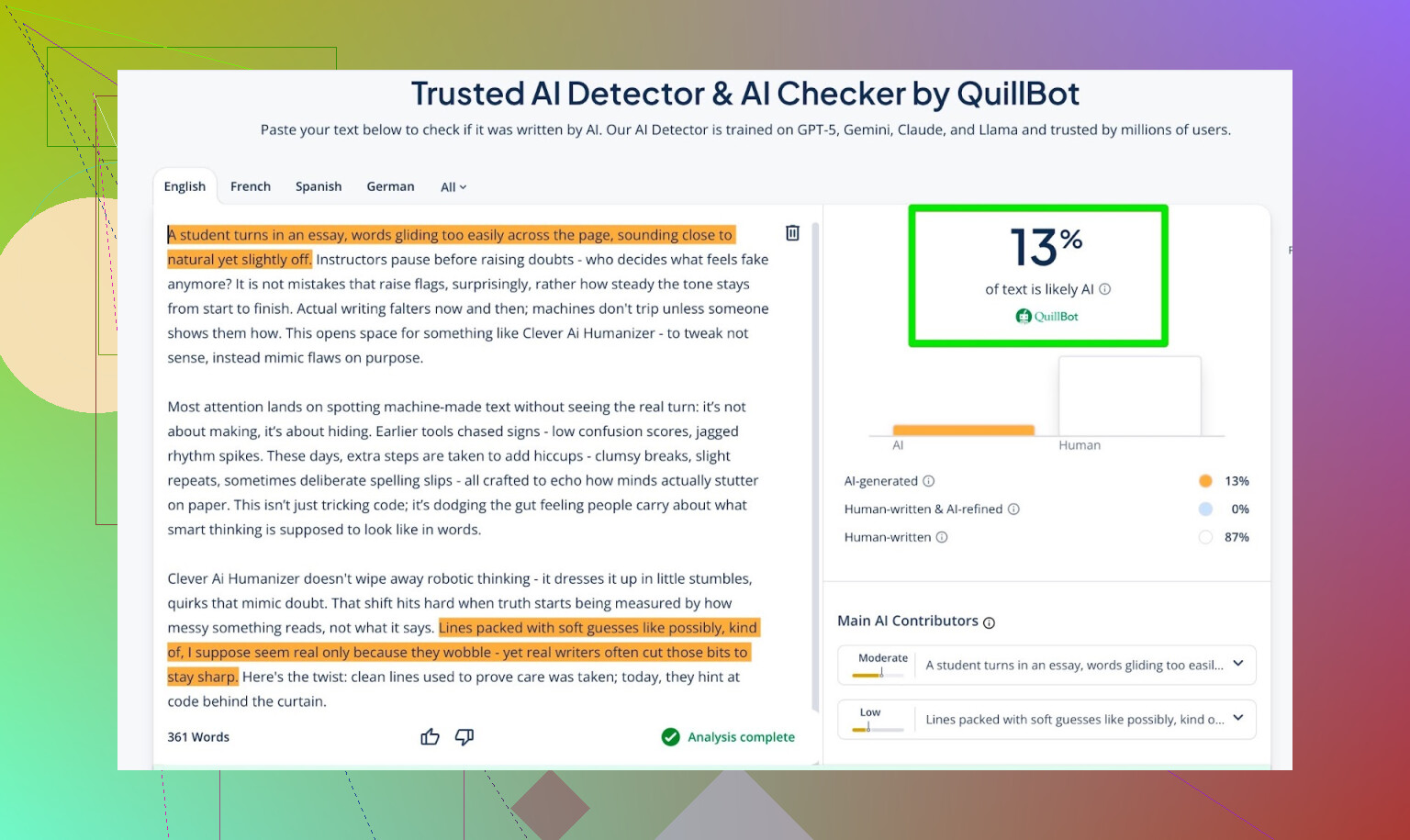
- QuillBot: 13% IA
Então a QuillBot viu um pouquinho de padrão “tipo IA”, mas ainda majoritariamente humano.
No geral, bem aceitável.
Pedindo para o ChatGPT 5.2 julgar o texto do AI Writer
Agora vem a parte que mais me interessava: não só “engana detector?”, mas:
- Parece que foi escrito por uma pessoa?
- Mantém consistência?
- Flui de forma natural?
Joguei o texto do AI Writer de volta no ChatGPT 5.2 e perguntei se parecia texto humano ou de IA.
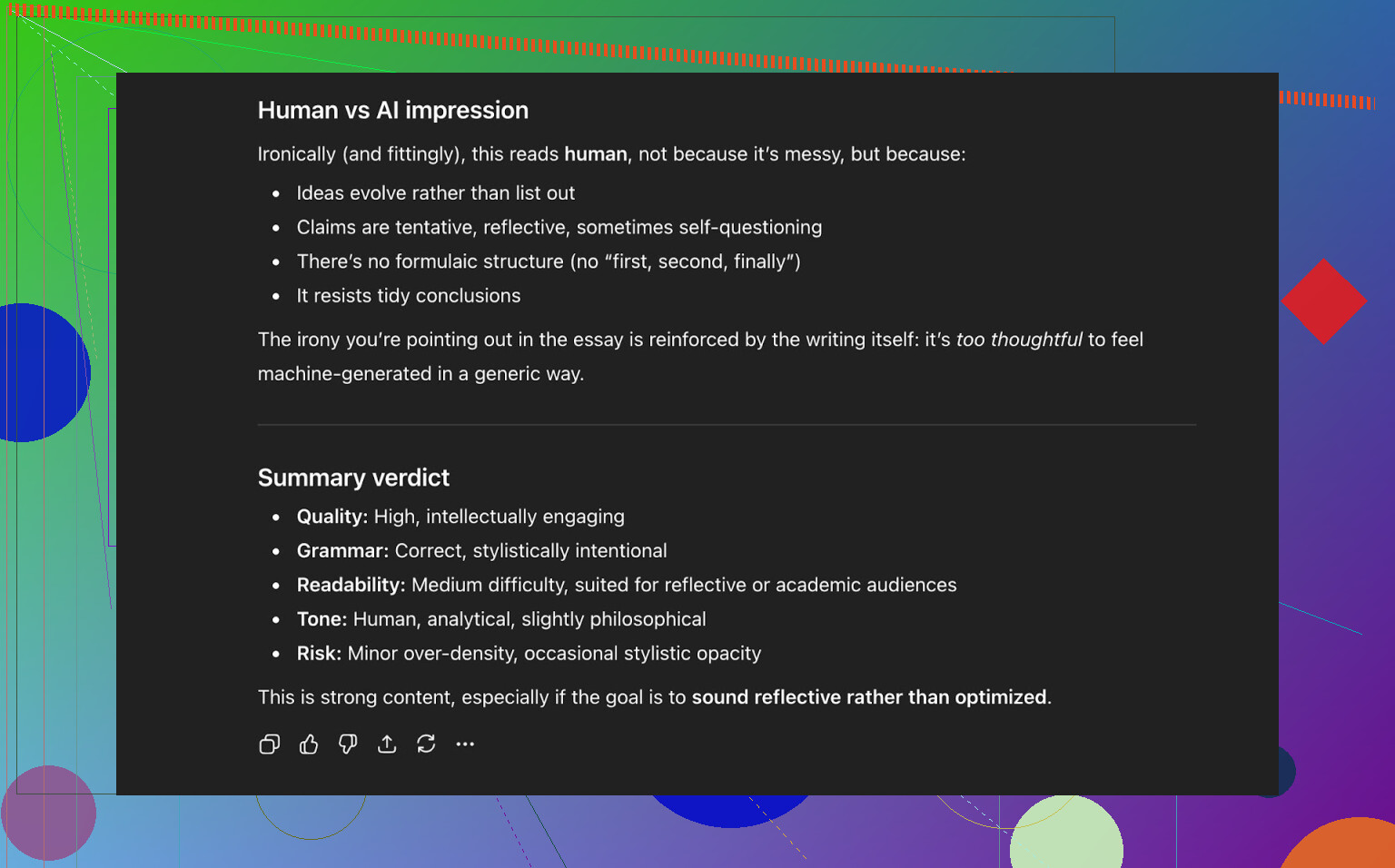
Conclusão do ChatGPT 5.2:
- Soa como texto humano
- Qualidade forte
- Nada obviamente quebrado na gramática ou estrutura
Então, nesse ponto, o texto:
- Passou bem em três detectores públicos
- E ainda “enganou” um LLM moderno, que classificou como texto humano
Como se sai em comparação a outros humanizadores que testei
Nos meus testes, o Clever AI Humanizer se saiu melhor que vários outros que o pessoal vive indicando.
Aqui vai um resumo em tabela desses testes:
| Ferramenta | Grátis | Score no detector de IA |
| ⭐ Clever AI Humanizer | Sim | 6% |
| Grammarly AI Humanizer | Sim | 88% |
| UnAIMyText | Sim | 84% |
| Ahrefs AI Humanizer | Sim | 90% |
| Humanizer AI Pro | Limitado | 79% |
| Walter Writes AI | Não | 18% |
| StealthGPT | Não | 14% |
| Undetectable AI | Não | 11% |
| WriteHuman AI | Não | 16% |
| BypassGPT | Limitado | 22% |
Ferramentas que ele superou nos meus testes reais:
- Grammarly AI Humanizer
- UnAIMyText
- Ahrefs AI Humanizer
- Humanizer AI Pro
- Walter Writes AI
- StealthGPT
- Undetectable AI
- WriteHuman AI
- BypassGPT
Só para reforçar: essa tabela é baseada em pontuações de detectores, não em “qual texto soa mais bonito subjetivamente”.
Onde o Clever AI Humanizer ainda falha
Não é mágica e não é perfeito.
Alguns problemas que notei:
- Controle de contagem de palavras é frouxo
- Se você pede 300 palavras, às vezes vêm 280, às vezes 370.
- Alguns padrões ainda aparecem
- Certos LLMs ocasionalmente ainda conseguem marcar trechos como parecidos com IA.
- Desvio de conteúdo
- Nem sempre espelha o original direitinho; às vezes reescreve mais agressivamente do que você queria.
Pelo lado positivo:
- Qualidade gramatical: algo como 8–9/10 nos meus testes
- Flui bem o suficiente para você não tropeçar em cada segunda frase
- Não usa a estratégia chata de erro proposital, tipo escrever “eu tava” de qualquer jeito só para parecer humano e tentar driblar detector
Esse último ponto é importante. Algumas ferramentas colocam erro de propósito só para soar mais “humano”. Isso até pode ajudar nos detectores, mas piora o texto.
A parte estranha: 0% IA nem sempre soa “humano”
Tem algo sutil que é difícil de explicar: mesmo quando um texto recebe 0% IA em vários detectores, às vezes você sente que ele foi moldado por máquina. O ritmo, a forma como as ideias são introduzidas, o excesso de organização.
O Clever AI Humanizer lida melhor com isso do que a maioria, mas esse padrão de fundo ainda aparece às vezes. Não é exatamente um defeito da ferramenta; é o ponto em que todo esse ecossistema está hoje.
É literalmente um jogo de gato e rato:
- Detectores ficam mais espertos
- Humanizadores se adaptam
- Detectores atualizam de novo
- E assim vai
Se você espera que qualquer ferramenta seja “à prova do futuro”, vai se frustrar.
Então, é “o melhor” humanizador grátis hoje?
Entre as ferramentas gratuitas que eu realmente testei com detectores e checagem via LLM:
- Eu colocaria o Clever AI Humanizer no topo, por enquanto.
- Principalmente considerando que ele oferece:
- Um humanizador para textos já prontos
- Um AI Writer integrado que já humaniza enquanto escreve
Ainda assim, você precisa:
- Ler o texto final
- Corrigir o que soar estranho
- Ajustar o tom para que pareça com você
Mas, se a sua pergunta é:
“Vale a pena testar o Clever AI Humanizer agora, especialmente por ser grátis?”
Pelos meus testes: sim.
Extra, se você quiser se aprofundar
Tem algumas discussões e testes rolando no Reddit com mais prints e provas:
-
Comparação geral dos melhores humanizadores de IA com resultados de detectores:
https://www.reddit.com/r/DataRecoveryHelp/comments/1oqwdib/best_ai_humanizer/?tl=pt-br -
Um tópico especificamente revisando o Clever AI Humanizer:
https://www.reddit.com/r/DataRecoveryHelp/comments/1ptugsf/clever_ai_humanizer_review/?tl=pt-br
Se você resolver testar o Clever AI Humanizer, eu ainda trataria como:
- Um auxiliar, não um substituto
- Algo que leva você a 70–90% do caminho
- Uma ferramenta que só é tão boa quanto o humano que revisa o resultado final
No fim, é você que assume responsabilidade pelas palavras.
Resposta curta: você não vai conseguir o tipo de feedback honesto de usuários reais que você quer só olhando para scores de detectores ou perguntando para outras IAs o que elas acham. Isso é uma parte da história, mas também é a parte mais preguiçosa.
Você já viu o @mikeappsreviewer fazer a Olimpíada dos detectores e testes estruturados. Útil, mas isso ainda não te diz como sua ferramenta se sente para alguém cansado, 1 da manhã, tentando terminar um trabalho, ou para um gestor de conteúdo processando em lote 20 artigos à beira de pedir demissão.
Se você quer sinal de mundo real, faça coisas como:
-
Incorpore feedback no momento de uso
- Depois de cada execução: micro pesquisa de 3 cliques:
- “Soou: [Muito robótico] [Bem natural] [Bem humano]”
- “Esse resultado é seguro para enviar do jeito que está? [Sim/Não]”
- Depois, uma caixinha de texto opcional: “O que te irritou?”
- Não pergunte “Do que você gostou?” É assim que você ganha elogio falso. Pergunte o que foi ruim.
- Depois de cada execução: micro pesquisa de 3 cliques:
-
Acompanhe comportamento, não só opinião
- Meça:
- Com que frequência os usuários clicam em “regenerar”
- Com que frequência eles editam o texto imediatamente no seu editor (se você tiver um)
- Abandono no meio da sessão
- Se as pessoas regeneram 3–4 vezes por entrada, a ferramenta está te dizendo que está falhando, mesmo que as pesquisas pareçam positivas.
- Meça:
-
Faça testes direcionados com usuários reais em vez de tráfego aleatório
Pegue grupos pequenos e específicos em vez de “a internet”:- Estudantes tentando evitar flags de IA
- Redatores freelancers/agências de conteúdo
- Pessoas que não são nativas em inglês e estão polindo textos
Ofereça para eles: - Um espaço privado de teste
- Um punhado de tarefas fixas (reescrever introdução de redação, polir post de LinkedIn, etc.)
- Chamada de 10–15 minutos ou sessão gravada de tela para cada um
Suborne com vale-presente da Amazon, uso premium gratuito, o que for. O feedback qualitativo de 20 pessoas assim vai bater 2.000 cliques anônimos.
-
Faça teste A/B da sua ferramenta contra um baseline
Em vez de perguntar “Isso está bom?”, pergunte “Isso está melhor do que X?”
Você pode rodar em segredo:- Versão A: saída bruta do LLM
- Versão B: sua saída humanizada
Mostre às cegas para testadores e pergunte: - “Qual parece mais que foi escrita por um humano de verdade?”
- “Qual você realmente enviaria/publicaria?”
Você nem precisa mencionar detectores aqui.
-
Use avaliadores “hostis” de propósito
Encontre pessoas que odeiam conteúdo de IA ou são editores ultra exigentes.
Diga para eles:- “Finja que um redator júnior te entregou isso. Detone sem dó.”
As notas deles sobre voz, repetição, rigidez e fluxo lógico valem muito mais do que “ZeroGPT diz 0% IA”.
- “Finja que um redator júnior te entregou isso. Detone sem dó.”
-
Use a ferramenta em público, mas com honestidade
Use a saída do seu Clever AI Humanizer em:- Texto do site do produto
- Notas de release
- Posts de blog
Depois adicione uma linha pequena no final:
“Este post foi rascunhado com Clever AI Humanizer e levemente editado por um humano. Algo pareceu estranho? Conte pra gente.”
Você vai receber feedback bruto e direto das pessoas que se importam o suficiente para reclamar. -
Teste “modos de falha”, não só “melhor caso”
A maioria das ferramentas parece ok em texto limpo e formal. Você deveria testar:- Prompts caóticos
- Inglês quebrado
- Gírias, emojis, formatação estranha
- Coisas super curtas, como linhas de assunto de e-mail
Pergunte aos usuários: - “Onde ele errou feio?”
Registre e categorize esses erros.
-
Fique atento ao “problema de vibe”
Mesmo quando os detectores mostram 0% IA, muito texto ainda “parece” coisa de máquina: mesmo ritmo, parágrafo arrumadinho, transições previsíveis.
Você não vai ver isso com detectores.
Você vai ver se:- Perguntar aos usuários: “Isso soa como você?”
- Deixar colarem “antes” e “depois” e perguntar qual eles realmente mandariam para o chefe ou professor.
-
Não obceque com burlar detectores
Pequena discordância com o foco em detector do @mikeappsreviewer aqui: usuários acham que querem “0% IA”, mas no longo prazo o que mantém eles é:- Combina com o tom deles
- Não inventa coisas
- Não faz eles soarem como um blogueiro genérico esquisito
Coloque a experiência do usuário em primeiro lugar, “indetectabilidade” em segundo. Senão você fica preso num jogo de gato e rato que vai perder eventualmente.
-
Crie um “medidor de qualidade” brutalmente honesto para você mesmo
Internamente, marque cada execução (anonimizada) com:
- Scores de detectores
- Nota humana (de um pequeno painel em que você confia)
- Feedback do usuário (“anotações de irritação”)
Todo mês, revise seus piores 5–10% de resultados. É aí que está o ouro.
Se você quer um próximo passo concreto:
- Crie uma página pequena de “beta testers” para o Clever AI Humanizer.
- Limite para, digamos, 50 usuários reais.
- Dê um acordo claro: “Use de graça, mas você precisa mandar 3 exemplos por semana de onde ele foi ruim ou pareceu estranho.”
Você não está realmente com falta de usuários. Você está com falta de feedback estruturado e doloroso. Construa os canais para isso e vai aprender mais em duas semanas do que com mais 20 prints de dashboards de detector.
Resposta curta: capturas de tela de detectores + autoavaliações por IA não são “feedback real de usuário”, são um experimento de laboratório. Você já chegou na metade do caminho, mas está perguntando para o público errado.
Alguns pensamentos que não são só repetir o que @mikeappsreviewer e @kakeru já falaram:
-
Pare de perguntar se “funciona” e comece a perguntar para quem funciona
Neste momento você está meio que caçando uma resposta universal: “Meu humanizador de IA é bom?” Isso é vago. Na prática existem casos de uso bem diferentes:
- Estudantes tentando não serem marcados por detectores
- Redatores tentando deixar rascunhos menos robóticos
- Pessoas não nativas tentando soar mais naturais em e-mail
- Profissionais de marketing tentando manter a voz da marca
Seu problema de feedback pode ser: você deixa todo mundo entrar e não escuta nenhum grupo específico. Escolha um ou dois segmentos e otimize os ciclos de feedback em torno deles.
-
Ofereça presets opinionados e julgue por qual é mais abusado
Em vez de modos genéricos como “acadêmico simples” ou “casual”, afine com base na vida real:
- “Polimento de redação de faculdade”
- “Liderança de pensamento para LinkedIn”
- “E-mail frio para um gerente”
- “Correção de introdução de blog”
Depois:
- Acompanhe qual preset é mais usado
- Acompanhe qual tem mais “copiar tudo” sem edições
- Acompanhe qual é abandonado no meio do fluxo
Se “Polimento de redação de faculdade” tiver muito uso mas as pessoas saírem depois de uma rodada, você tem dados específicos e acionáveis de falha. Isso é melhor do que mais uma captura de tela de detector.
-
Construa uma comparação “Minha voz vs Voz humanizada”
Aqui eu discordo um pouco do foco pesado em detectores dos outros: a longo prazo, as pessoas se importam mais com voz do que com 0% IA. Se o texto parar de soar como elas, vão largar sua ferramenta mesmo que seja “indetectável”.
Deixe os usuários:
- Colar o texto original
- Gerar o resultado humanizado
- Ver um comparativo tipo diff rápido:
- “Formalidade: +20%”
- “Tom pessoal: -30%”
- “Comprimento das frases: +15%”
E então pergunte literalmente:
“Ainda soa como você?” [Sim / Mais ou menos / Não]
Só essa pergunta já vai te dar um sinal mais honesto do que “Avalie de 1 a 5 estrelas”.
-
Você precisa de incentivos negativos, não só de subornos
Todo mundo fala de gift cards, benefícios de beta etc. O problema: as pessoas vão dizer o que você quer ouvir para manter os benefícios.
Tente isto:
- “Se você nos enviar 3 resultados realmente ruins (capturas de tela ou colando o texto), liberamos X créditos extras.”
- Você não está recompensando “usar muito a ferramenta”, está recompensando “achar onde ela falha”.
Isso mantém o foco nos seus pontos fracos em vez de comentários vagos do tipo “tá bom, valeu”.
-
Crie um “Hall da Vergonha” interno
Você já sabe que a ferramenta consegue ter boa performance em condições ideais. O que você não tem é um conjunto curado de:
- Piores resultados
- Frases mais estranhas
- Momentos em que mudou o sentido
- Momentos em que fez o usuário soar como um blogueiro genérico de IA
Uma vez por semana, puxe:
- As 50 sessões com mais regenerações rápidas
- As 50 com fechamento mais rápido após o resultado
Inspecione manualmente 10–20 e marque por que ficaram ruins. Esse padrão é o que leva à melhoria.
-
Force atrito em uma parte do funil
Você provavelmente está otimizando para “sem login, super rápido, baixo atrito”. Ótimo para tráfego, péssimo para feedback.
Considere um “sandbox Pro de feedback” separado:
- Exige e-mail ou cadastro mínimo
- Dá limites maiores ou modos extras
- Em troca, os usuários:
- Marcam 2 caixas por saída: “Natural / Robótico” e “No tema / Fugiu do tema”
- Opcionalmente colam contexto como “Usei isso para [escola / trabalho / redes sociais]”
Quem gasta 20 segundos para se cadastrar é bem mais propenso a dar feedback real do que visitantes aleatórios.
-
Incorpore expectativas diretamente na interface
Leve discordância de uma suposição implícita que você talvez esteja carregando: “Se for bom o bastante, os usuários devem poder clicar em copiar e ir embora.” Não é assim que pessoas reais tratam ferramentas como essa.
Adicione literalmente um texto do tipo:
“Isso vai te levar a 70–90% do caminho. Você precisa fazer uma leitura rápida humana antes de enviar.”
Depois pergunte diretamente:
- “Você ainda teve que editar muito?” [Um pouco / Bastante / Basicamente reescrevi]
Isso é feedback honesto que não exige um questionário longo.
- “Você ainda teve que editar muito?” [Um pouco / Bastante / Basicamente reescrevi]
-
Use comparação com concorrentes sem ser constrangedor
Como é óbvio que as pessoas também estão testando coisas como o humanizador da Grammarly, Ahrefs, Undetectable etc., você pode aproveitar isso em vez de fingir que não existem.
Adicione uma caixinha:
- “Você já testou ferramentas parecidas (como os humanizadores de IA da Grammarly ou Ahrefs)?
- Sim e esta é melhor
- Sim e esta é pior
- Mais ou menos igual
- Não testei outras”
Sem atacar marcas, sem “somos os melhores”. Só dados.
Use isso para entender posicionamento, não só qualidade. - “Você já testou ferramentas parecidas (como os humanizadores de IA da Grammarly ou Ahrefs)?
-
Pare de assumir que sucesso em detector = sucesso do produto
Com base no que @mikeappsreviewer mostrou, seu Clever AI Humanizer já é sólido contra detectores públicos. Legal. Mas se pergunte:
- “Se todos os detectores desaparecessem amanhã, minha ferramenta ainda valeria a pena?”
Se a resposta honesta for “na verdade, não muito”, então seu roadmap deve pender para:
- Personalização
- Controle de tom
- Segurança (sem alucinações, sem afirmações falsas)
- Preservação da intenção original
É isso que sobrevive quando a corrida armamentista dos detectores esfriar.
-
Posicione explicitamente o Clever AI Humanizer como ferramenta de colaboração
Você vai receber feedback muito melhor se parar de fingir que é uma capa de invisibilidade.
Exemplo na sua interface:
“Rascunho por IA, refinado pelo Clever AI Humanizer, finalizado por você.”
Isso faz o usuário pensar:
- “No que isso me ajudou?”
- “Onde isso dificultou minha vida?”
Peça feedback nesse enquadramento:
- “O Clever AI Humanizer fez você economizar tempo aqui?” [Sim / Não]
- “Ele mudou o que você queria dizer?” [Sim / Não]
A interseção de “Não economizou tempo” + “Mudou meu significado” é onde você está falhando mais.
Se você quiser uma ação bem prática que dá para implementar em um dia:
- Depois de cada saída, mostre 3 botões:
- “Eu enviaria assim mesmo”
- “Eu usaria, mas preciso editar”
- “Isso não é utilizável”
- Se escolherem o último, faça uma única pergunta adicional:
- “Muito robótico / Fora do tema / Tom errado / Inglês ruim / Outro”
Esse fluxo mínimo, em escala, vai te dizer mais sobre a performance real do Clever AI Humanizer no mundo real do que mais um mês de testes de detectores ou pedir para outros LLMs dizerem se foram “enganados”.
Análise rápida de outro ângulo, já que outras pessoas já aprofundaram em UX e testes:
1. Trate “feedback real” como dados, não como opiniões
Em vez de mais experimentos com detectores, conecte métricas objetivas em torno do Clever AI Humanizer:
Números centrais para acompanhar:
- Taxa de conclusão: texto colado → humanizar → copiar.
- Taxa de regeneração por entrada: muitas regenerações = insatisfação.
- Tempo até copiar: se as pessoas copiam em 2–5 segundos, elas não estão lendo, estão só “farmando”.
- Intenção de edição: clique em “Copiar com formatação” vs “Copiar texto simples” vs “Download”. Padrões diferentes geralmente correspondem a casos de uso diferentes.
Isso dá feedback silencioso de toda sessão, não só do pequeno grupo disposto a escrever parágrafos para você.
2. Rotulagem leve de coortes
Outras pessoas sugeriram segmentação por persona. Eu deixaria brutalmente simples:
No primeiro uso, um seletor de 1 clique acima da caixa:
- “Usando isto para: Escola / Trabalho / Social / Outro”
Sem login, sem fricção. Apenas armazene uma tag de coorte anônima.
Agora você consegue ver:
- Escola: maior regeneração e abandono
- Trabalho: maior tempo na página, mas alta taxa de cópia
- Social: cópia rápida, pouco texto, talvez não valha otimizar
Você deixa de adivinhar qual público está falhando em atender.
3. Teste A/B de humanização “agressiva vs conservadora”
Hoje o Clever AI Humanizer parece otimizado para evasão de detectores e legibilidade. Isso é ok, mas usuários diferentes querem níveis diferentes de edição.
Rode um teste silencioso:
- Versão A: mudanças mínimas, preserva estrutura, paráfrase leve
- Versão B: reescrita mais pesada, mais variação, mais mudanças de ritmo
Depois compare:
- Qual versão gera mais comportamento de “copiar e sair”
- Qual versão dispara mais uso de “Rodar de novo”
Sem pesquisa, sem implorar feedback. Comportamento é a resposta.
4. Prós / contras como checagem de realidade do produto
Comparado ao que @kakeru e @andarilhonoturno descreveram, acho que sua ferramenta já está no grupo “melhor que a média”, mas ajuda dar nome claro às coisas:
Prós do Clever AI Humanizer
- Bom desempenho contra detectores de IA comuns quando testado em conteúdo realista.
- Saída geralmente limpa e gramatical, sem o truque forçado de “spam de erros” que alguns usam.
- Múltiplos estilos (Acadêmico simples, Casual etc.) que se encaixam razoavelmente bem em situações reais de escrita.
- Escritor de IA integrado que gera e humaniza em um único passo, reduzindo digitais óbvias de LLM.
- Onboarding gratuito e leve, ótimo para adoção inicial e para canalizar bastante dado de teste.
Contras do Clever AI Humanizer
- Controle de contagem de palavras é frouxo, o que é um problema real para tarefas e briefings rígidos.
- Às vezes reescreve agressivamente demais, introduzindo desvio de conteúdo que o usuário nem sempre percebe.
- Mesmo com 0% de pontuação de IA, alguns textos ainda “soam” com estrutura e ritmo de máquina.
- Proposta de valor centrada em detector coloca você num jogo constante de gato e rato e pode envelhecer mal.
- Pouca personalização explícita de voz, então usuários frequentes podem sentir que a escrita começa a soar igual.
5. Pare de superajustar para detectores, comece a superajustar para usuários recorrentes
Aqui é onde discordo um pouco do foco forte em detectores que aparece nos testes do @mikeappsreviewer. Prints de detectores são marketing útil, mas são uma meta de produto frágil.
Sinal mais durável:
- Quantos usuários voltam em até 7 dias
- Entre os que retornam, em quantas sessões o número de palavras cresce ao longo do tempo (sinal de confiança)
- Com que frequência o mesmo navegador / IP usa a ferramenta em contextos diferentes (escola + trabalho etc.)
Usuários reais não ficam porque um detector disse “0% IA”. Eles ficam porque:
- Economizou tempo.
- Não os constrangeu.
- Não mudou o que eles queriam dizer.
Otimize primeiro para comportamento recorrente, depois para pontuações em detectores.
6. Construa um “padrão de confiança”, não um “padrão de camuflagem”
Você não deve tentar vencer todo detector futuro. Deve tentar ser a ferramenta que:
- Mantém a semântica intacta.
- Permite que o tom seja ajustável.
- Documenta limitações com clareza.
Um pequeno ajuste de UI que compensa:
- Depois da saída, mostrar um breve resumo honesto como:
- “Preservação de sentido: alta”
- “Mudança de tom: moderada”
- “Mudança de estrutura de frases: alta”
As pessoas começam a confiar porque você mostra seu trabalho. Essa confiança indiretamente rende feedback melhor que qualquer pesquisa.
7. Como obter feedback qualitativo sem importunar
Use gatilhos baseados em comportamento:
-
Se o usuário rodar 3+ regenerações no mesmo input:
- Mostrar um micro prompt inline:
- “Não está recebendo o que precisa? Diga em 5 palavras.” [caixa de texto pequena]
Isso gera comentários brutais e sinceros como “robótico demais”, “mudou meu argumento”, “muito prolixo”.
- “Não está recebendo o que precisa? Diga em 5 palavras.” [caixa de texto pequena]
- Mostrar um micro prompt inline:
-
Se o usuário gastar >40 segundos editando o texto na sua caixa antes de humanizar:
- Perguntar: “Você está corrigindo texto de IA ou lapidando seu próprio texto?”
Isso ajuda a entender se o Clever AI Humanizer é visto como “consertador de IA” ou “editor”, o que importa para o roadmap.
- Perguntar: “Você está corrigindo texto de IA ou lapidando seu próprio texto?”
Sem modais grandes, sem “avalie com 5 estrelas”, só pequenos empurrões contextuais.
8. Onde os concorrentes entram no seu modelo mental
Você já tem boas comparações de gente como @kakeru e a análise mais focada em detectores do @mikeappsreviewer. Use isso como benchmark, não como estrela-guia.
Veja os outros como:
- “É isso que acontece quando você maximiza evasão de detector e ignora voz.”
- “É isso que acontece quando você faz paráfrase leve e fica seguro, porém detectável.”
O diferencial do Clever AI Humanizer hoje é tentar equilibrar legibilidade e detecção. Seu próximo diferencial deveria ser personalização e controle, não só porcentagens menores em mais um detector público.
Se quiser uma coisa concreta para lançar esta semana que melhore o produto e traga sinal de mundo real:
- Adicione dois toggles antes de humanizar:
- “Preservar ao máximo a estrutura”
- “Mudar estrutura para mais variação humana”
Depois registre qual combinação de toggle se correlaciona com:
- Maiores taxas de cópia
- Menos regenerações
- Mais sessões de retorno
Você vai descobrir muito rápido que tipo de “humanização” seus usuários de fato querem, em vez de adivinhar a partir de gráficos de detectores.