Ho creato uno strumento intelligente di humanizer per l’AI pensato per rendere il testo generato dall’intelligenza artificiale più naturale e autentico, ma sto facendo fatica a ottenere feedback onesti da utenti reali. Vorrei sapere come si comporta nell’uso reale: sembra davvero scritto da un essere umano, è affidabile per la scrittura di contenuti e la SEO, e dove invece fallisce o appare chiaramente prodotto dall’AI? Ho bisogno di feedback dettagliati e pratici per poter correggere i problemi, migliorare la qualità e assicurarmi che sia sicuro e affidabile per blogger, marketer e utenti comuni che desiderano contenuti AI con un tono umano.
Clever AI Humanizer: La mia esperienza reale, con prove
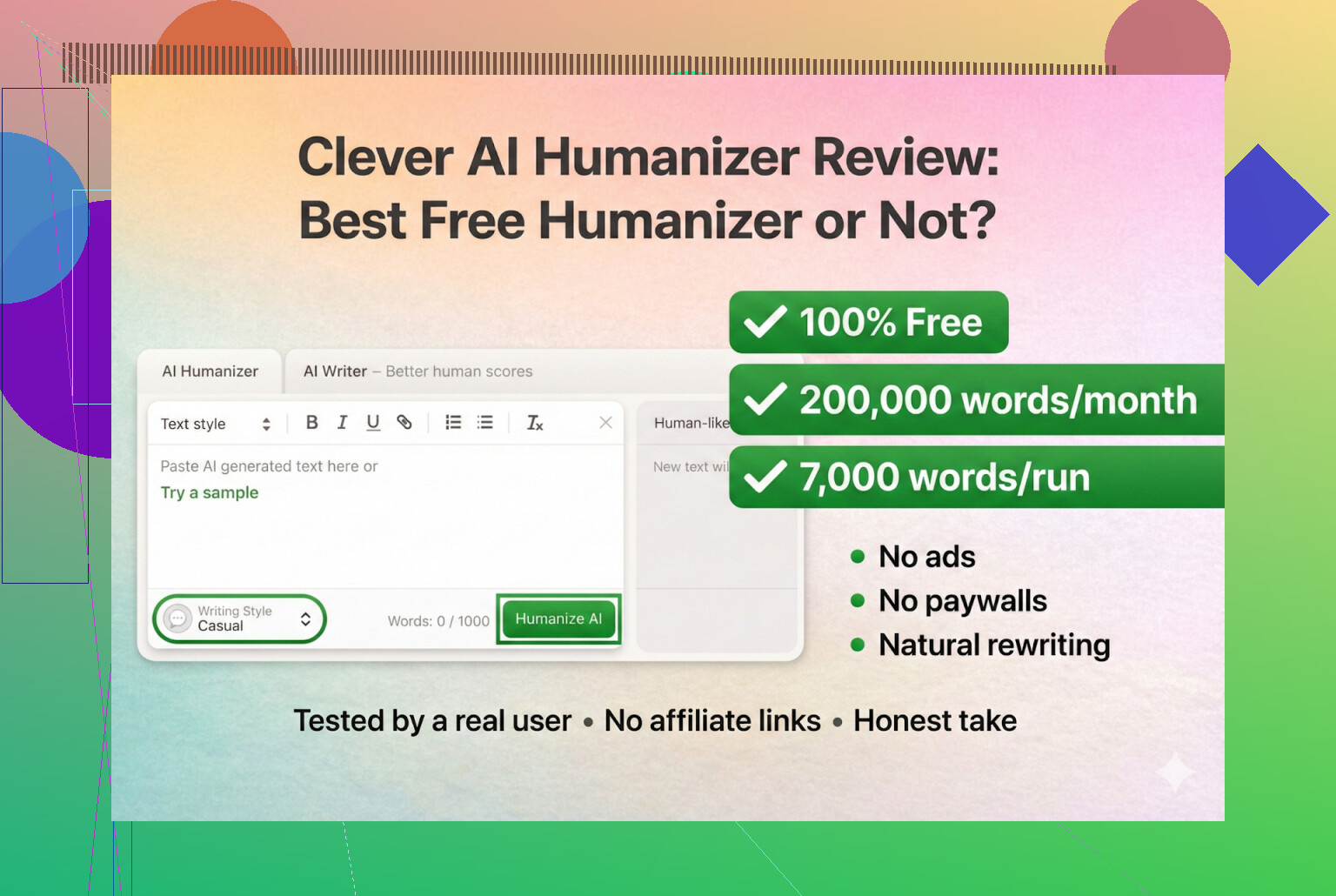
Negli ultimi tempi ho smanettato con un bel po’ di strumenti di “AI humanizer”, soprattutto perché continuavo a vedere persone su Discord e Reddit chiedere quali funzionassero ancora. Molti si sono rotti, sono diventati servizi a pagamento da un giorno all’altro o sono semplicemente peggiorati in silenzio.
Così ho deciso di partire da strumenti davvero gratuiti, senza registrazione, senza carta di credito. Primo nella lista: Clever AI Humanizer.
Lo trovi qui:
Clever AI Humanizer — Miglior humanizer 100% gratuito
Per quanto ne so, questo è quello vero, non un clone e nemmeno un rebrand strano.
Confusione sugli URL e copie fasulle
Un piccolo avviso, perché ci sono cascato anch’io: esistono diversi siti “AI humanizer” con nomi simili che comprano annunci sulla stessa parola chiave. Un paio di persone mi hanno scritto in privato chiedendo “qual è il vero Clever AI Humanizer?” perché erano finiti su siti completamente diversi che cercavano di farsi pagare per le funzioni “pro”.
Per chiarezza:
- Clever AI Humanizer vero e proprio (Clever AI Humanizer — Miglior humanizer 100% gratuito)
- Per quello che ho visto:
- Niente piani premium
- Nessun abbonamento
- Nessun popup “sblocca 5.000 parole in più per 9,99 $”
Se hai cliccato qualcosa da Google Ads e ti sei ritrovato con la carta di credito addebitata, quello non era questo strumento.
Come l’ho testato (AI contro AI al 100%)
Volevo vedere fin dove potesse arrivare in uno scenario estremo, quindi non l’ho affatto trattato con i guanti.
- Ho chiesto a ChatGPT 5.2 di scrivere un articolo interamente AI su Clever AI Humanizer.
- Nessuna modifica umana.
- Solo copia-incolla.
- Ho preso quell’output e l’ho passato in Clever AI Humanizer in modalità Simple Academic.
- Ho fatto analizzare il risultato da più rilevatori di AI.
- Poi ho chiesto a ChatGPT 5.2 di valutare il testo riscritto.
In questo modo non c’è la scusa “magari il testo di partenza era già abbastanza umano”. È 100% macchina su macchina.
Modalità Simple Academic: perché ho scelto l’opzione più difficile
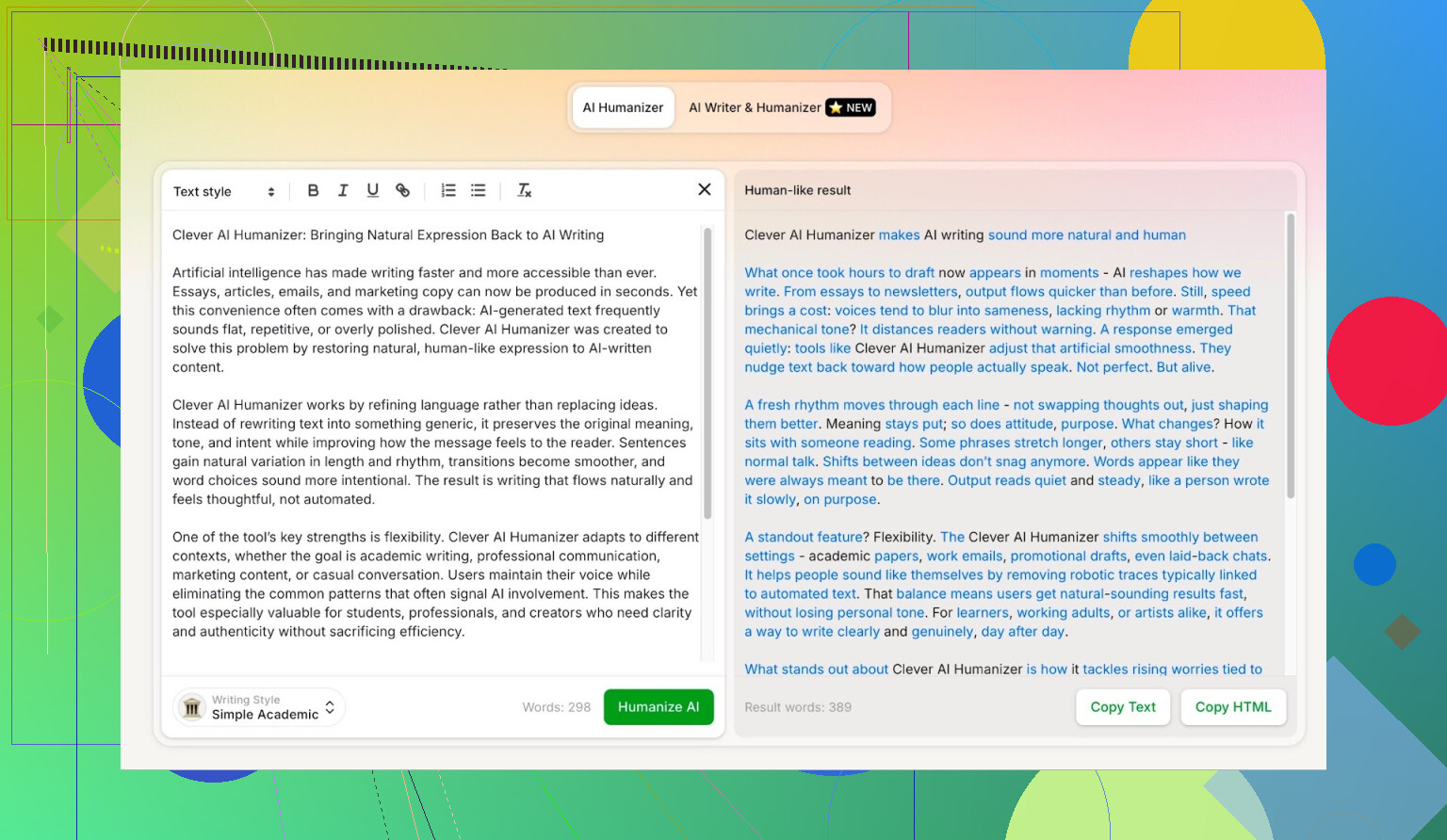
Non ho scelto lo stile Casual o Blog o qualcosa di morbido. Sono andato diretto su Simple Academic.
Come si sente questa modalità in pratica:
- Ancora leggibile, non è gergo da rivista accademica
- Leggermente formale, strutturata e ordinata
- Abbastanza “accademica” da sembrare seria, ma non come una tesi
Quella via di mezzo è esattamente dove i rilevatori di AI di solito iniziano a gridare “AI!” perché le frasi diventano troppo pulite ed equilibrate. Quindi, se un humanizer riesce a gestire questo stile e comunque ottenere buoni punteggi, la cosa è interessante.
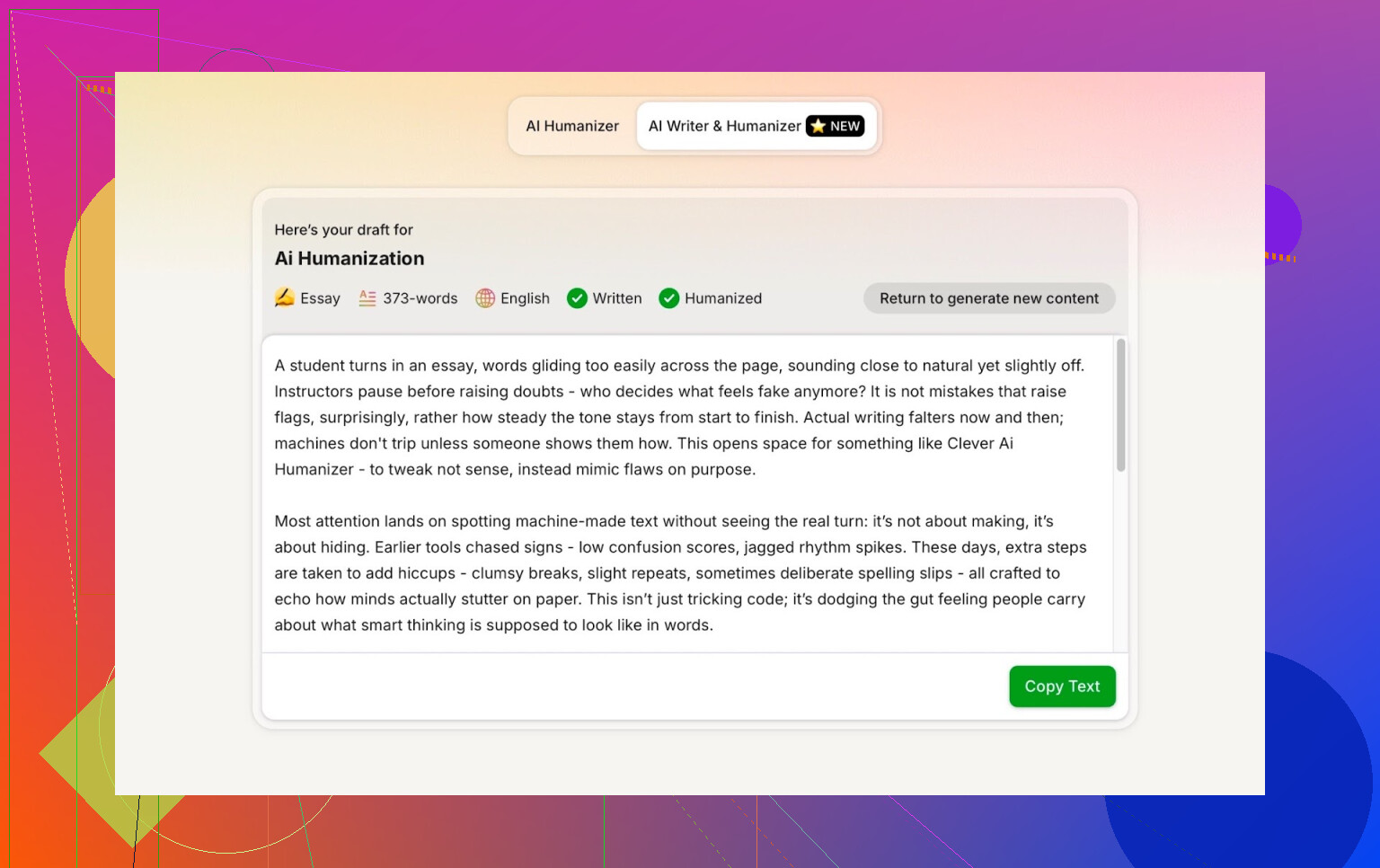
ZeroGPT: il test “non mi fido, ma lo usano tutti”
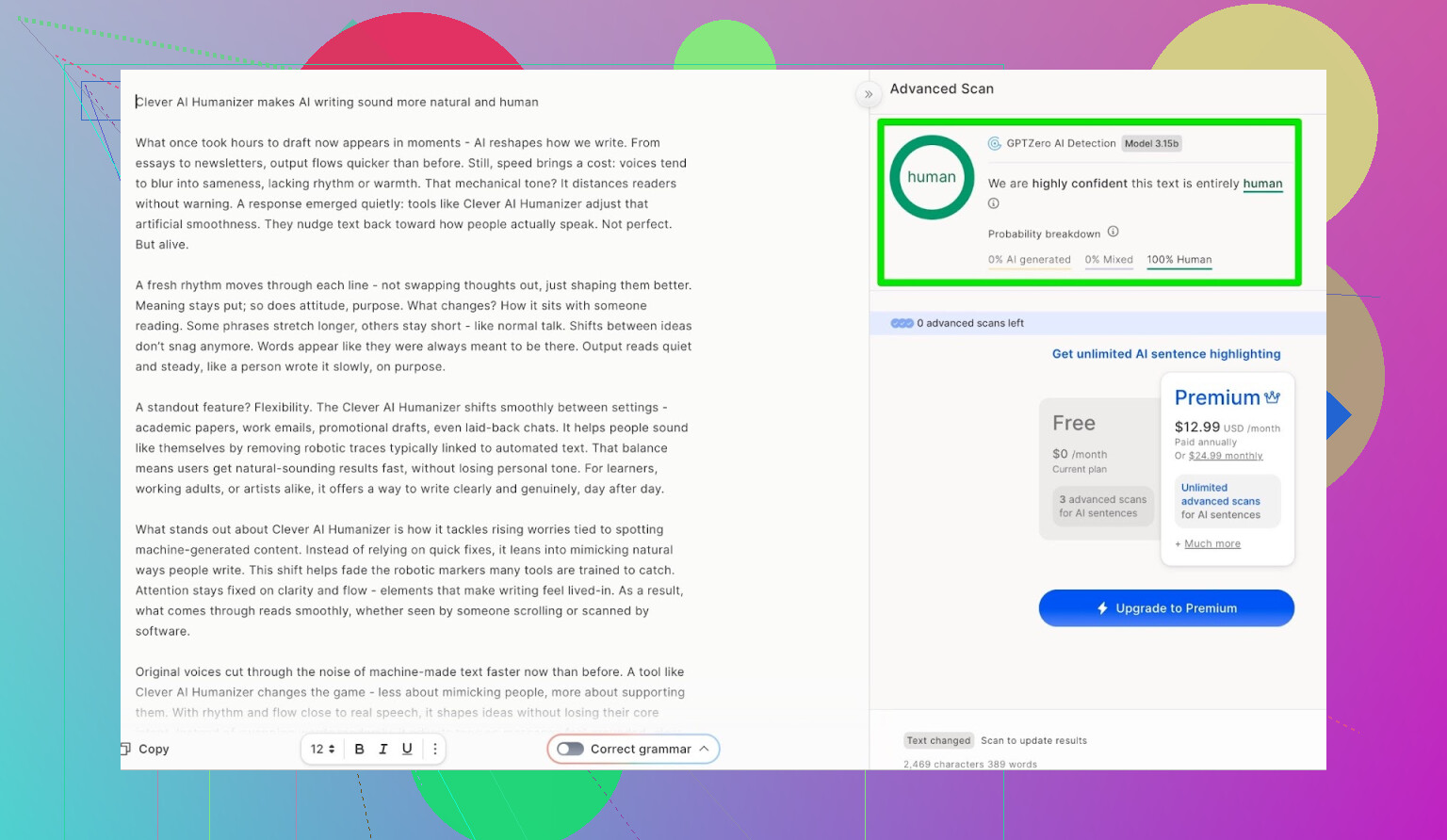
Non sono un fan di ZeroGPT per un motivo principale: segnala la Costituzione degli Stati Uniti come “100% AI”.
Dopo aver visto questo, la fiducia crolla.
Detto ciò:
- È ancora dappertutto su Google.
- La gente continua a usarlo perché è tra i primi risultati.
- Quindi l’ho incluso.
Risultato per l’output di Clever AI Humanizer:
ZeroGPT: 0% AI rilevata.
Per quello che vale: più di così, su quello strumento, non si può ottenere.
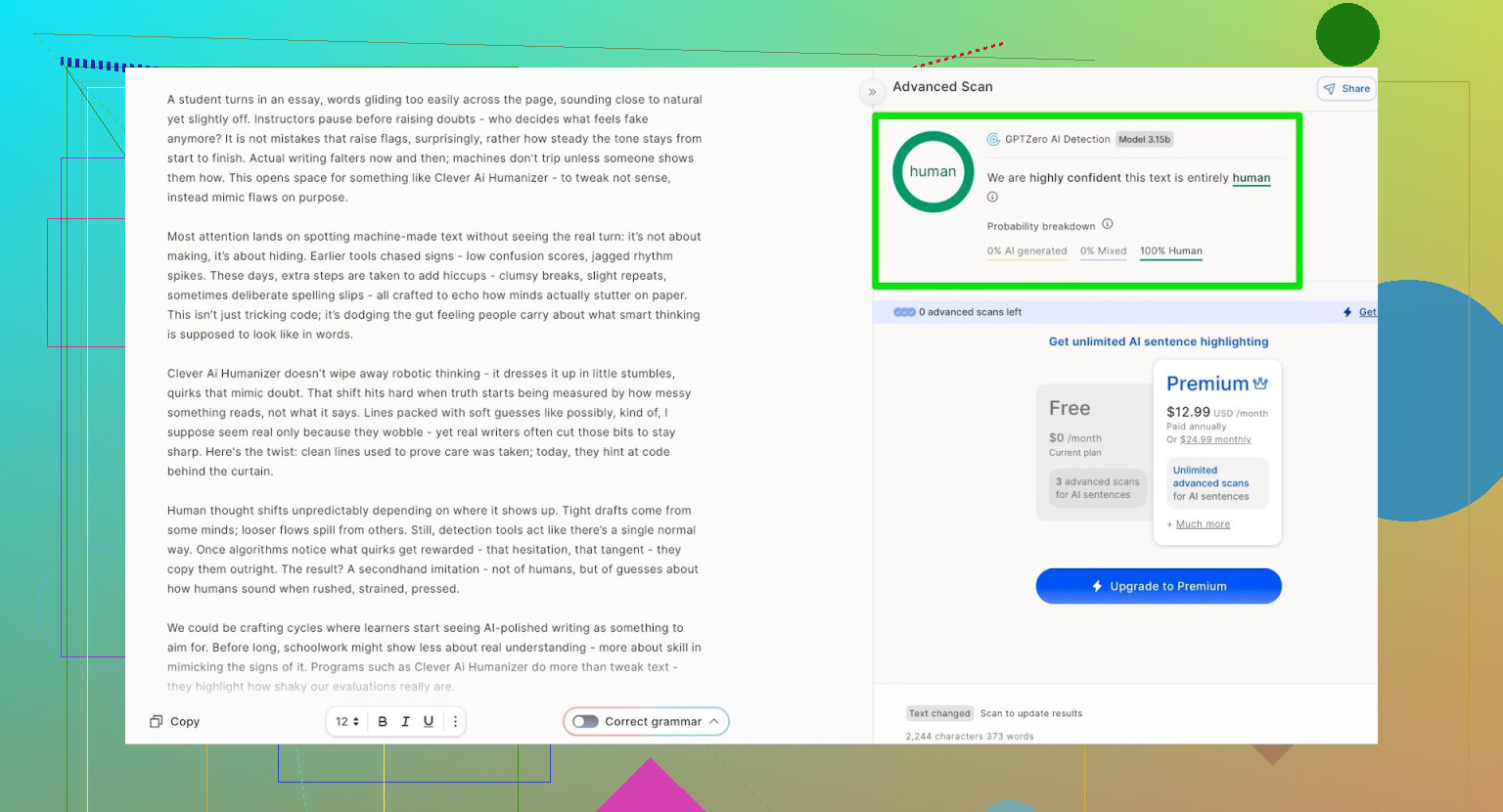
GPTZero: seconda opinione, stesso risultato
Successivo in lista: GPTZero.
Questo è molto usato in scuole e università, quindi spesso è quello che fa più paura.
L’output di Clever AI Humanizer (modalità Simple Academic) è stato classificato come:
- 100% scritto da umano
- 0% AI
Quindi, sui due rilevatori pubblici più comuni, il testo è passato con punteggi perfetti.
Ma si legge da schifo?
Qui è dove molti humanizer falliscono:
Passano i rilevatori, ma il testo sembra tradotto 4 volte avanti e indietro con app diverse.
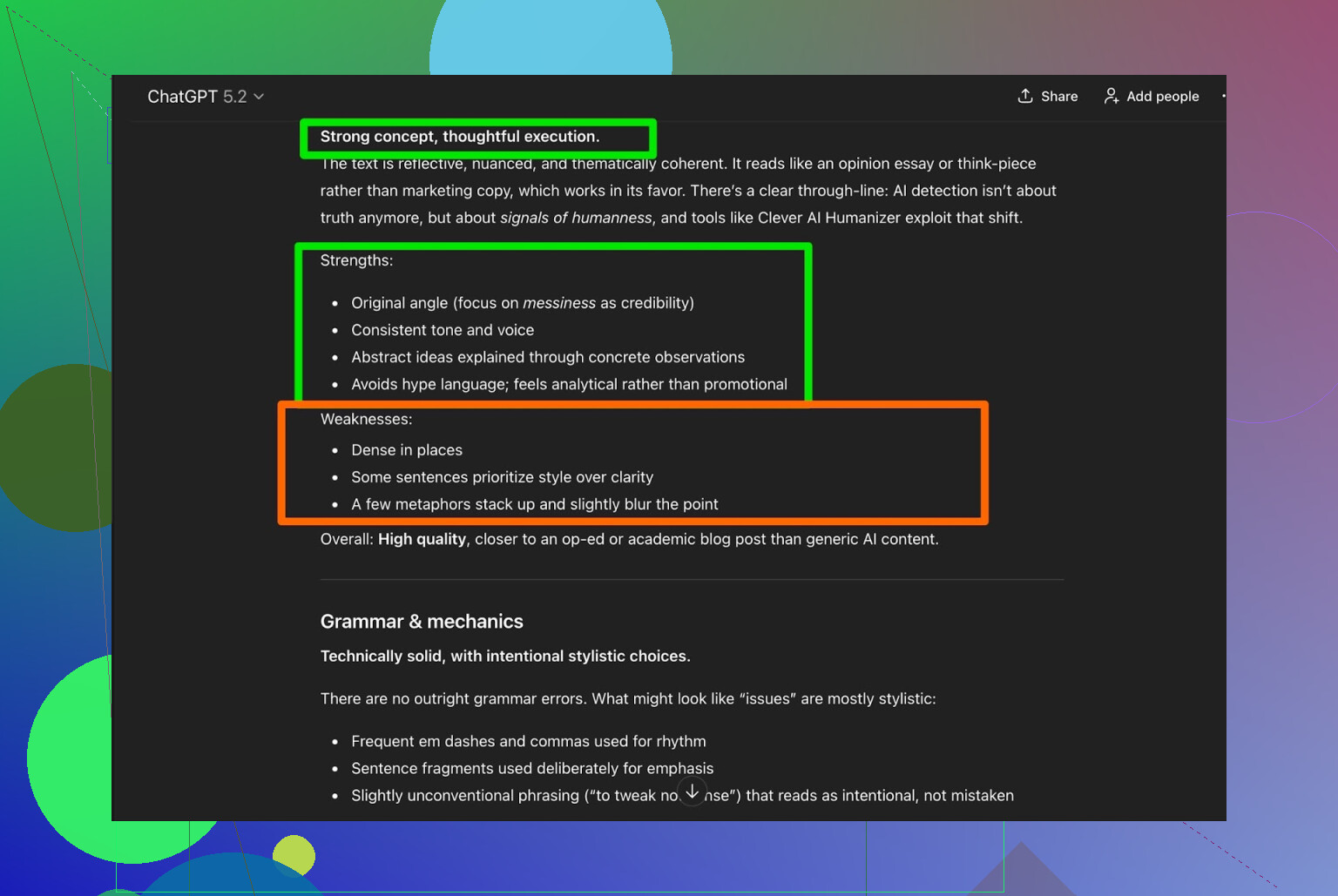
Ho preso l’output di Clever AI Humanizer e ho chiesto a ChatGPT 5.2 di analizzarlo:

Verdetto generale:
- Grammatica: solida
- Stile: si adatta abbastanza bene alla modalità Simple Academic
- Raccomandazione: consiglia comunque una revisione umana
Onestamente, sono d’accordo. Questa è semplicemente la realtà:
Qualsiasi testo scritto o “umanizzato” da AI beneficia ancora di una lettura umana finale.
Se uno strumento dichiara “nessuna revisione umana necessaria”, probabilmente è marketing, non verità.
Provare l’AI Writer integrato in Clever AI Humanizer
Hanno uno strumento separato qui:
https://aihumanizer.net/itai-writer
Qui diventa più interessante. Invece di:
LLM → Copia → Incolla nell’humanizer → Sperare nel meglio
Puoi:
- Generare e umanizzare in un solo passaggio
- Lasciare che il loro sistema controlli da subito struttura e stile
Questo conta perché, se uno strumento genera da sé il contenuto, può modellarlo in modo da evitare naturalmente alcuni dei pattern di AI più ovvi.
Per il test ho:
- Selezionato lo stile di scrittura Casual
- Tema: umanizzazione AI, con menzione di Clever AI Humanizer
- Inserito apposta un piccolo errore nel prompt per vedere come lo gestiva
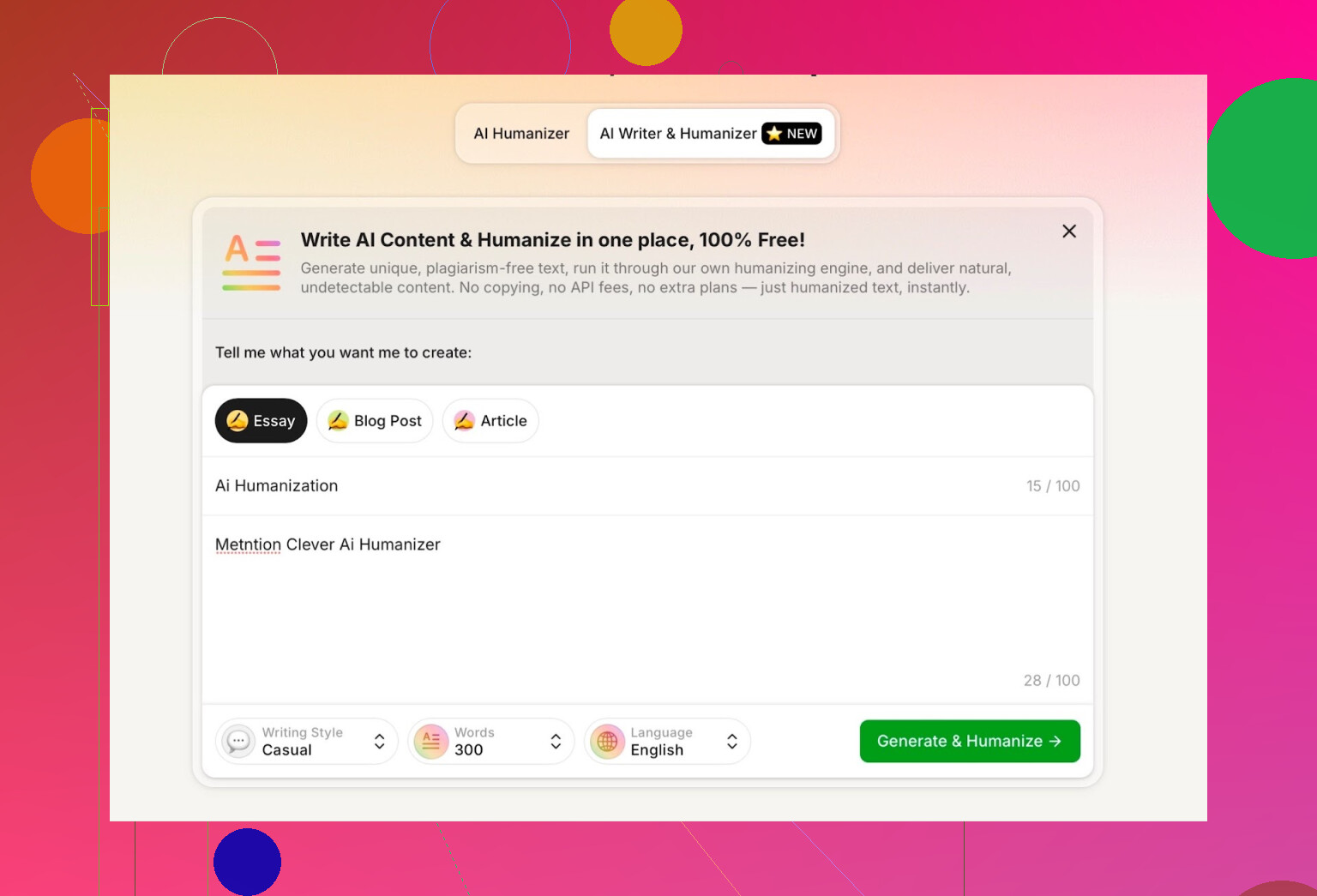
L’output era pulito, conversazionale, e non ha ripetuto il mio refuso in modo strano.
Una cosa che non mi è piaciuta:
- Ho chiesto 300 parole
- Me ne ha date più di 300
Se dico 300, voglio 300. Non 412. Questo tipo di cosa conta se hai limiti rigidi di consegna o brief di contenuto precisi.
Questo è stato il mio primo vero difetto riscontrato.
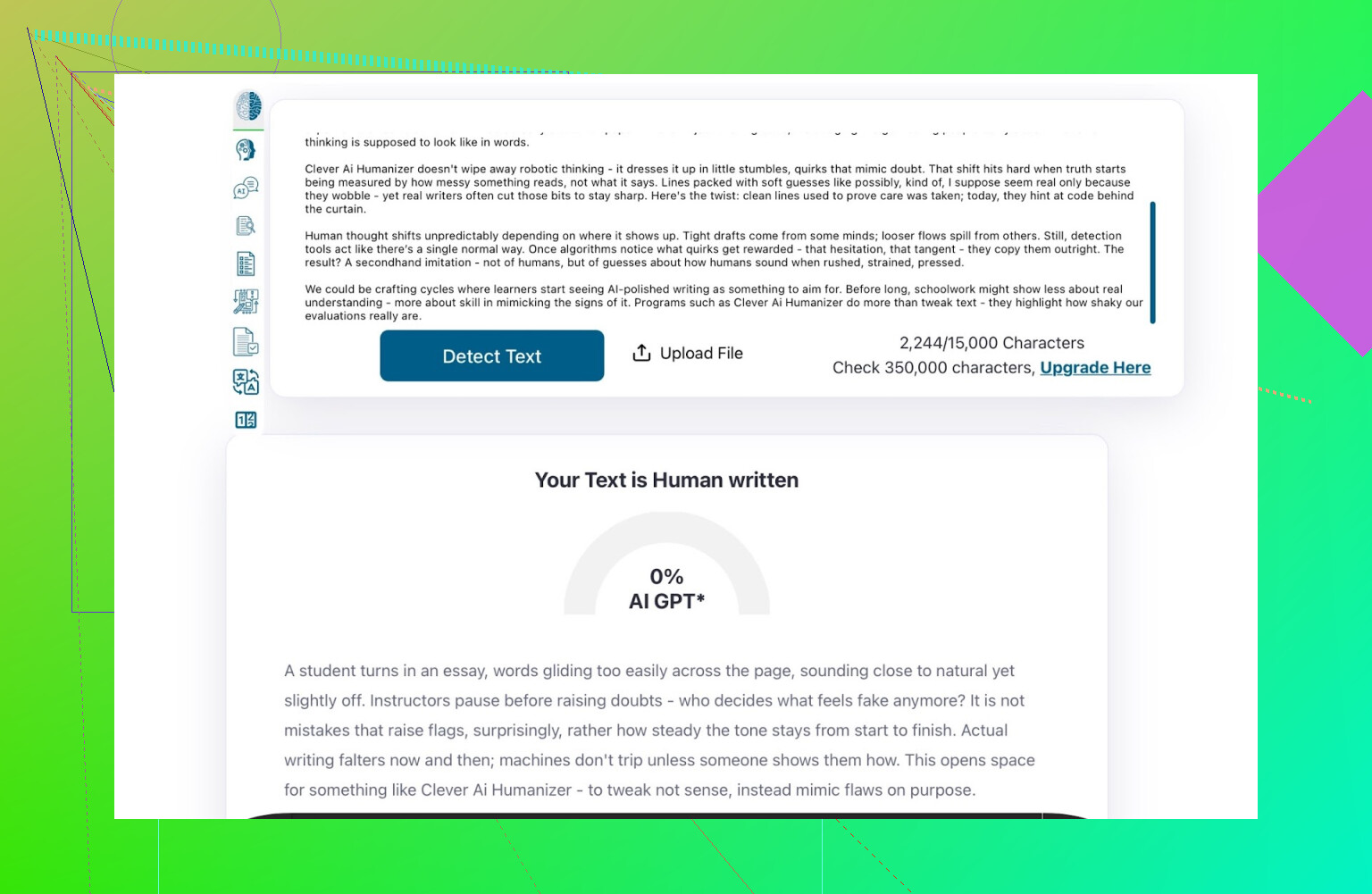
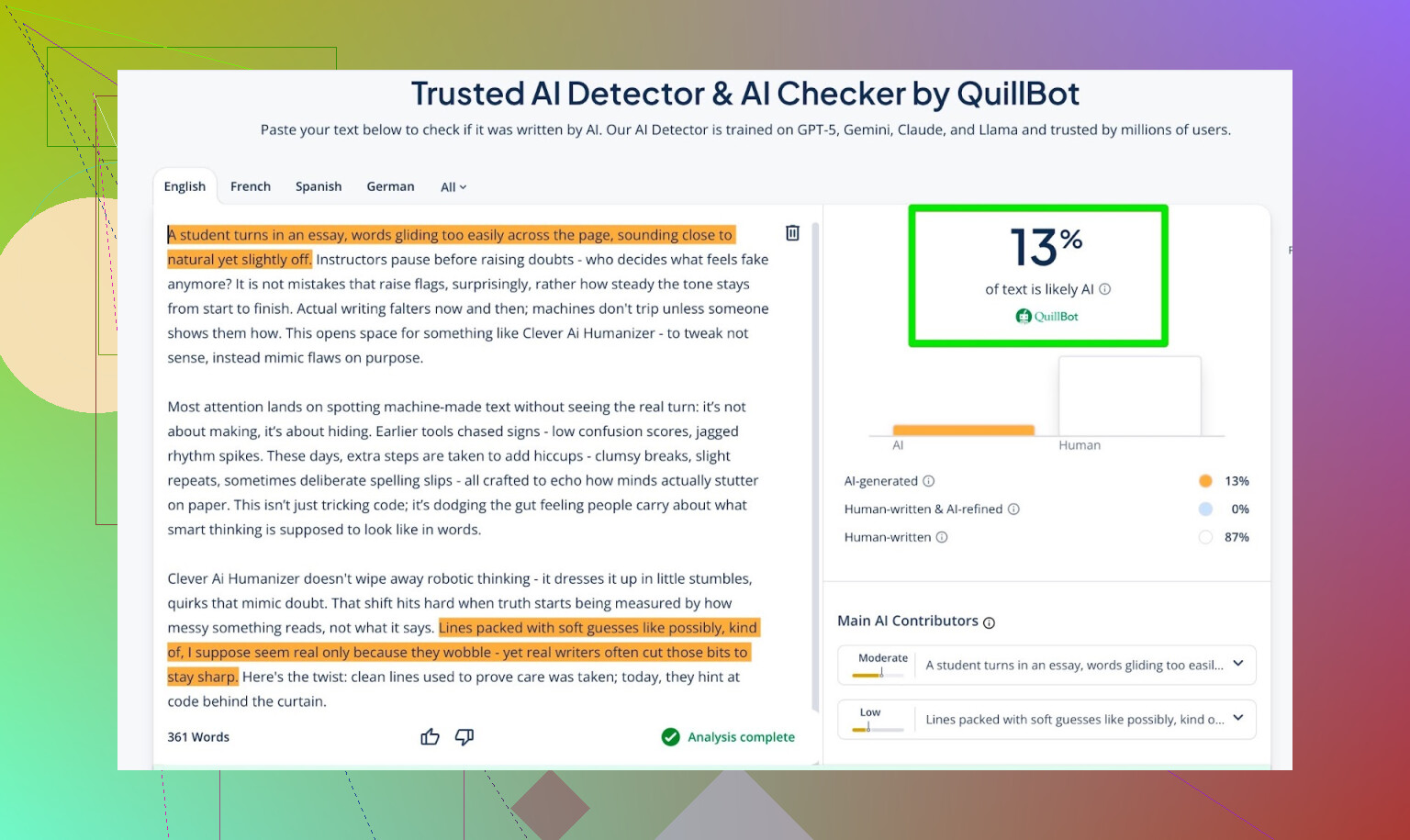
Punteggi di rilevazione per l’output dell’AI Writer
Ho preso ciò che l’AI Writer ha prodotto e l’ho fatto analizzare da:
- GPTZero
- ZeroGPT
- QuillBot detector per un dato in più
Risultati:
- GPTZero: 0% AI
- ZeroGPT: 0% AI, 100% umano
- QuillBot: 13% AI
QuillBot ha visto una piccola percentuale di pattern “simile all’AI”, ma comunque per lo più umano.
Nel complesso, direi che è piuttosto buono.
Chiedere a ChatGPT 5.2 di valutare l’output dell’AI Writer
Qui arriva la parte che mi interessava davvero: non solo “inganna i rilevatori”, ma:
- Suona come una persona?
- Mantiene coerenza?
- Si legge in modo naturale?
Ho rimandato il testo dell’AI Writer in ChatGPT 5.2 chiedendo se sembrasse scritto da umano o da AI.
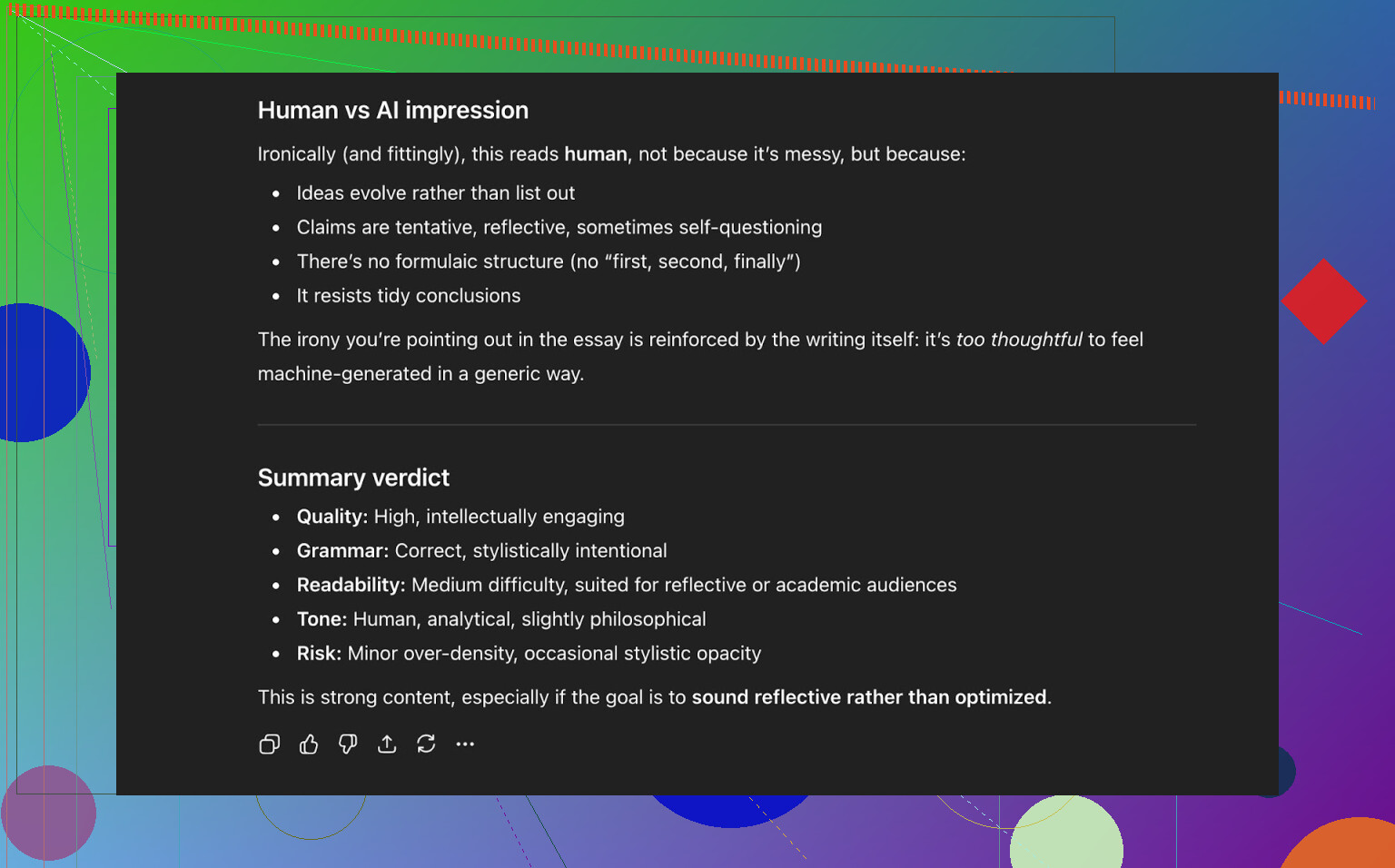
Conclusione di ChatGPT 5.2:
- Si legge come scritto da umano
- Qualità alta
- Niente di chiaramente rotto a livello di grammatica o struttura
A quel punto, quindi, il testo:
- Ha superato bene tre rilevatori di AI pubblici
- Ha anche “ingannato” un LLM moderno portandolo a classificarlo come scritto da umano
Come se la cava rispetto ad altri humanizer che ho provato
Nei miei test, Clever AI Humanizer è andato meglio di parecchi altri strumenti di cui si parla spesso.
Ecco una tabella riassuntiva di quelle prove:
| Strumento | Gratuito | Punteggio rilevatore AI |
| ⭐ Clever AI Humanizer | Sì | 6% |
| Grammarly AI Humanizer | Sì | 88% |
| UnAIMyText | Sì | 84% |
| Ahrefs AI Humanizer | Sì | 90% |
| Humanizer AI Pro | Limitato | 79% |
| Walter Writes AI | No | 18% |
| StealthGPT | No | 14% |
| Undetectable AI | No | 11% |
| WriteHuman AI | No | 16% |
| BypassGPT | Limitato | 22% |
Strumenti che ha battuto nei miei test reali:
- Grammarly AI Humanizer
- UnAIMyText
- Ahrefs AI Humanizer
- Humanizer AI Pro
- Walter Writes AI
- StealthGPT
- Undetectable AI
- WriteHuman AI
- BypassGPT
Per essere chiari: questa tabella si basa sui punteggi dei rilevatori, non su “quale suona meglio soggettivamente”.
Dove Clever AI Humanizer è ancora carente
Non è magico e non è perfetto.
Alcuni problemi che ho notato:
- Controllo del numero di parole approssimativo
- Chiedi 300 parole, magari ne ottieni 280 o 370.
- Pattern che ogni tanto emergono
- Alcuni LLM possono comunque rilevare tratti simili all’AI in certe parti.
- Deriva di contenuto
- Non sempre rispecchia l’originale alla lettera; a volte riscrive in modo più aggressivo del previsto.
Sul lato positivo:
- Qualità grammaticale: circa 8–9/10 nei miei test
- Scorre abbastanza bene da non farti inciampare a ogni riga
- Niente strategia fastidiosa del “refuso intenzionale”, tipo scrivere “i was” invece di “I was” per cercare di ingannare i rilevatori
Quest’ultimo punto conta. Alcuni strumenti inseriscono apposta errori solo per sembrare più umani. Magari passano più spesso i rilevatori, ma peggiorano il testo.
La cosa strana: 0% AI non vuol dire sempre “davvero umano”
C’è qualcosa di sottile e difficile da spiegare: anche quando un testo ottiene 0% AI su più strumenti, a volte senti comunque che è “plasmato dalla macchina”. Il ritmo, il modo in cui le idee vengono introdotte, l’eccessiva pulizia.
Clever AI Humanizer fa meglio della maggior parte, ma quel pattern di fondo a volte si percepisce ancora. Non è davvero una critica al tool in sé; è semplicemente il punto in cui si trova oggi l’intero ecosistema.
È letteralmente un gioco del gatto col topo:
- I rilevatori diventano più intelligenti
- Gli humanizer si adattano
- I rilevatori si aggiornano di nuovo
- E così via
Se ti aspetti che uno strumento sia “a prova di futuro”, resterai deluso.
Quindi, è “il migliore” humanizer gratuito al momento?
Per gli strumenti gratuiti che ho realmente testato con rilevatori e verifiche via LLM:
- Metterei Clever AI Humanizer al primo posto, per ora.
- Soprattutto considerando che ha sia:
- Un humanizer per testi già esistenti
- Un AI Writer integrato che umanizza mentre scrive
Devi comunque:
- Leggere tu stesso l’output
- Sistemare ciò che stona
- Regolare il tono perché suoni come te
Ma se la tua domanda è:
“Vale la pena provare Clever AI Humanizer adesso, soprattutto visto che è gratis?”
In base ai miei test: sì.
Extra se vuoi approfondire sul serio
Ci sono alcune discussioni e test su Reddit con più screenshot e prove:
-
Confronto generale dei migliori AI humanizer con risultati dei rilevatori:
https://www.reddit.com/r/DataRecoveryHelp/comments/1oqwdib/best_ai_humanizer/?tl=it -
Thread di recensione specifico su Clever AI Humanizer:
https://www.reddit.com/r/DataRecoveryHelp/comments/1ptugsf/clever_ai_humanizer_review/?tl=it
Se decidi di provare Clever AI Humanizer, io lo tratterei comunque come:
- Un assistente, non un sostituto
- Qualcosa che ti porta al 70–90% del risultato
- Uno strumento che è valido solo quanto la persona che rivede il testo finale
Alla fine, sei tu quello che deve mettere la faccia su quelle parole.
Risposta breve: non otterrai il tipo di feedback onesto da utenti reali che desideri solo guardando i punteggi dei detector o chiedendo ad altre AI cosa ne pensano. Quello è un pezzo della storia, ma è anche il pezzo più pigro.
Hai già visto @mikeappsreviewer fare le Olimpiadi dei detector e i test strutturati. Utile, ma ancora non ti dice come si sente il tuo strumento quando qualcuno è stanco all’una di notte e deve finire un paper, o quando un content manager sta processando in serie 20 articoli ed è sul punto di mollare.
Se vuoi segnali dal mondo reale, fai cose come queste:
-
Incorpora il feedback nel momento d’uso
- Dopo ogni esecuzione: micro sondaggio in 3 clic:
- “Suonava: [Troppo robotico] [Abbastanza naturale] [Molto umano]”
- “Questo output era sicuro da inviare così com’è? [Sì/No]”
- Poi una piccola casella di testo opzionale: “Cosa ti ha infastidito?”
- Non chiedere “Cosa ti è piaciuto?” Così ottieni lodi fasulle. Chiedi cosa faceva schifo.
- Dopo ogni esecuzione: micro sondaggio in 3 clic:
-
Traccia il comportamento, non solo le opinioni
- Misura:
- Quante volte gli utenti cliccano su “rigenera”
- Quanto spesso modificano subito il testo nel tuo editor (se ne hai uno)
- Abbandoni nel mezzo della sessione
- Se le persone rigenerano 3–4 volte per input, lo strumento ti sta dicendo che sta fallendo, anche se i sondaggi sembrano positivi.
- Misura:
-
Fai test mirati con utenti reali invece di traffico casuale
Prendi gruppi piccoli e specifici invece di “internet”:- Studenti che cercano di evitare i flag anti‑AI
- Writer freelance/agenzie di contenuti
- Non madrelingua inglese che vogliono ripulire i testi
Offri loro: - Uno spazio di test privato
- Una manciata di task fissi (riscrivere l’intro di un saggio, rifinire un post LinkedIn, ecc.)
- Call da 10–15 minuti o sessione registrata dello schermo per ciascuno
Corrompili con buoni Amazon, uso premium gratuito, ecc. Il feedback qualitativo che otterrai da 20 persone così batterà 2.000 clic anonimi.
-
Fai A/B test del tuo strumento contro un baseline
Invece di chiedere “È buono?” chiedi “È meglio di X?”
Puoi far girare in segreto:- Versione A: output grezzo del LLM
- Versione B: il tuo output umanizzato
Mostrali in cieco ai tester e chiedi: - “Quale sembra più scritto da un essere umano reale?”
- “Quale invieresti/pubblicheresti davvero?”
Non devi nemmeno menzionare i detector qui.
-
Usa apposta revisori “ostili”
Trova persone che odiano i contenuti AI o sono editor ultra pignoli.
Di’ loro:- “Fai finta che te l’abbia consegnato un junior. Smontalo.”
Le loro note su voce, ripetizione, rigidità e flusso logico sono molto più potenti di “ZeroGPT dice 0% AI”.
- “Fai finta che te l’abbia consegnato un junior. Smontalo.”
-
Fai dogfooding in pubblico, ma con onestà
Usa l’output del tuo Clever AI Humanizer su:- Testi del sito prodotto
- Note di rilascio
- Post del blog
Poi aggiungi una piccola riga in fondo:
“Questo post è stato scritto con Clever AI Humanizer e leggermente revisionato da un umano. Qualcosa ti è sembrato strano? Faccelo sapere.”
Otterrai feedback crudo e brutale dalle persone che ci tengono abbastanza da lamentarsi. -
Testa le “modalità di fallimento”, non solo i casi ideali
La maggior parte degli strumenti sembra ok su testo pulito e formale. Dovresti testare:- Prompt caotici
- Inglese molto scorretto
- Slang, emoji, formattazioni strane
- Contenuti super brevi come oggetti email
Chiedi agli utenti: - “Dove ha completamente toppato?”
Registra e categorizza questi fallimenti.
-
Fai attenzione al “problema delle vibes”
Anche quando i detector mostrano 0% AI, molti testi sembrano comunque “a forma di macchina”: stesso ritmo, struttura dei paragrafi troppo ordinata, passaggi prevedibili.
Questo non lo cogli con i detector.
Lo cogli se:- Chiedi agli utenti: “Suona come te?”
- Permetti loro di incollare “prima” e “dopo”, poi chiedi quale manderebbero davvero al capo o al professore.
-
Non fissarti troppo sull’aggirare i detector
Leggera divergenza dall’approccio focalizzato sui detector di @mikeappsreviewer: gli utenti pensano di volere “0% AI”, ma nel lungo periodo quello che li tiene è:- Rispecchia il loro tono
- Non introduce bugie
- Non li fa suonare come un blogger generico strano
Metti la UX al primo posto, l’“indetectabilità” al secondo. Altrimenti resti incatenato a un gioco del gatto col topo che alla fine perderai.
-
Aggiungi per te stesso un “quality meter” spietatamente trasparente
Internamente, tagga ogni run (anonimizzata) con:
- Punteggi dei detector
- Valutazione umana (da un piccolo panel di persone di cui ti fidi)
- Feedback degli utenti (“note di fastidio”)
Ogni mese, rivedi il peggior 5–10% degli output. È lì che sta l’oro.
Se vuoi un passo concreto successivo:
- Metti su una piccola pagina “beta tester” per Clever AI Humanizer.
- Metti un tetto, per esempio, a 50 utenti reali.
- Dai loro un accordo chiaro: “Usalo gratis, ma devi mandare 3 esempi a settimana di dove ha fatto schifo o è sembrato strano.”
Non ti mancano davvero gli utenti. Ti manca feedback strutturato e doloroso. Costruisci i canali per quello e imparerai di più in due settimane che da altri 20 screenshot di dashboard dei detector.
Risposta breve: gli screenshot dei detector e le auto-valutazioni dell’AI non sono “feedback reale degli utenti”, sono un esperimento da laboratorio. Sei a metà strada, ma stai facendo la domanda al pubblico sbagliato.
Alcuni spunti che non ripetono solo quello che hanno già detto @mikeappsreviewer e @kakeru:
-
Smetti di chiedere se “funziona” e inizia a chiedere per chi funziona
Al momento stai inseguendo una risposta universale: “Il mio humanizer di AI è buono?” È vago. In pratica ci sono casi d’uso molto diversi:
- Studenti che non vogliono essere segnalati
- Content writer che vogliono rendere le bozze meno robotiche
- Non madrelingua che vogliono suonare più naturali nelle email
- Marketer che devono mantenere la voce del brand
Il tuo problema di feedback potrebbe essere: fai entrare tutti e non ascolti nessun gruppo specifico. Scegline uno o due segmenti e costruisci intorno a loro i loop di feedback.
-
Offri preset orientati e poi giudica quale viene abusato
Invece di modalità generiche tipo “accademico semplice” o “casuale”, stringi su casi reali:
- “Rifinitura tema universitario”
- “Post LinkedIn da thought-leader”
- “Email a freddo a un manager”
- “Fixer per intro di blog”
Poi:
- Traccia quale preset viene usato di più
- Traccia quale ha più “copia tutto” senza modifiche
- Traccia quale gli utenti abbandonano a metà
Se “Rifinitura tema universitario” viene usato tantissimo ma la gente abbandona dopo un run, hai dati specifici e azionabili su dove fallisce. È meglio dell’ennesimo screenshot del detector.
-
Costruisci un confronto “Mia voce vs Voce umanizzata”
Qui dissento un po’ dal focus pesante sui detector degli altri: sul lungo periodo, alla gente importa più della voce che dello 0% AI. Se il testo smette di suonare come loro, smetteranno di usare il tuo tool anche se è “indetectable”.
Fai in modo che gli utenti possano:
- Incollare il testo originale
- Ottenere il risultato umanizzato
- Vedere un rapido confronto in stile diff:
- “Formalità: +20%”
- “Tono personale: -30%”
- “Lunghezza frasi: +15%”
Poi chiedi letteralmente:
“Sembra ancora scritto da te?” [Sì / Più o meno / No]
Questa singola domanda ti darà segnali più onesti di un “Valuta da 1 a 5”.
-
Ti servono incentivi negativi, non solo ricompense
Tutti parlano di buoni regalo, vantaggi beta, ecc. Il problema: la gente dirà quello che vuoi sentirti dire per tenersi i premi.
Prova così:
- “Se ci invii 3 output davvero pessimi (screenshot o testo), sblocchiamo X crediti extra.”
- Non ricompensi “usare tanto il tool”, ricompensi “trovare dove fallisce”.
Così l’attenzione rimane sui punti deboli, non su commenti vaghi tipo “sì è buono, grazie”.
-
Crea una “Hall of Shame” interna
Sai già che lo strumento può funzionare bene nelle condizioni ideali. Quello che non hai è una raccolta curata di:
- Output peggiori
- Frasi più imbarazzanti
- Volte in cui ha cambiato il significato
- Volte in cui ha fatto sembrare l’utente un generico blogger AI
Una volta a settimana prendi:
- Le 50 sessioni con più rigenerazioni rapide
- Le 50 con la chiusura più veloce dopo l’output
Ispeziona manualmente 10–20 sessioni e tagga perché facevano schifo. Quello schema è il modo in cui migliori.
-
Inserisci attrito in un punto del funnel
Probabilmente stai ottimizzando per “no-login, super veloce, zero attrito”. Ottimo per il traffico, pessimo per il feedback.
Considera una “sandbox Pro per feedback” separata:
- Richiede email o una registrazione minima
- Offre limiti più alti o modalità extra
- In cambio gli utenti:
- Spuntano 2 caselle per output: “Naturale / Robotico” e “In tema / Fuori tema”
- Facoltativamente incollano contesto come “L’ho usato per [scuola / lavoro / social]”
Chi si prende 20 secondi per registrarsi è molto più propenso a darti feedback reale rispetto ai passanti casuali.
-
Incorpora le aspettative direttamente nella UI
Leggera divergenza rispetto all’assunzione implicita che forse stai facendo: “Se è abbastanza buono, gli utenti dovrebbero poter fare copia e incolla e stop.” Non è così che le persone reali usano questi strumenti.
Aggiungi letteralmente un testo tipo:
“Questo ti porta al 70–90% del risultato. Devi comunque fare una rapida lettura umana prima di inviarlo.”
Poi chiedi direttamente:
- “Hai dovuto ancora modificarlo molto?” [Un po’ / Parecchio / L’ho praticamente riscritto]
È un feedback onesto che non richiede un sondaggio lungo.
- “Hai dovuto ancora modificarlo molto?” [Un po’ / Parecchio / L’ho praticamente riscritto]
-
Sfrutta il confronto con i competitor senza essere cringe
Visto che le persone stanno ovviamente provando anche strumenti come l’humanizer di Grammarly, Ahrefs, Undetectable, ecc., puoi sfruttare la cosa invece di fingere che non esistano.
Aggiungi una piccola checkbox:
- “Hai provato strumenti simili (tipo gli humanizer AI di Grammarly o Ahrefs)?
- Sì e questo è meglio
- Sì e questo è peggio
- Più o meno uguale
- Non ho provato altri”
Niente brand-bashing, niente hype tipo “siamo i migliori”. Solo dati.
Usali per capire il posizionamento, non solo la qualità. - “Hai provato strumenti simili (tipo gli humanizer AI di Grammarly o Ahrefs)?
-
Smetti di dare per scontato che successo sui detector = successo del prodotto
In base a quello che ha mostrato @mikeappsreviewer, il tuo Clever AI Humanizer è già solido contro i detector pubblici. Bene. Ma chiediti:
- “Se domani sparissero tutti i detector, il mio tool varrebbe ancora la pena di essere usato?”
Se la risposta onesta è “non proprio”, allora la tua roadmap dovrebbe spostarsi verso:
- Personalizzazione
- Controllo del tono
- Safety (niente allucinazioni, niente affermazioni false)
- Preservazione dell’intento originale
È questo il genere di valore che rimane quando la corsa agli armamenti sui detector si sgonfia.
-
Posiziona esplicitamente Clever AI Humanizer come strumento di collaborazione
Otterrai feedback molto migliore se smetti di fingere che sia un mantello dell’invisibilità.
Esempio in UI:
“Bozza creata da AI, rifinita da Clever AI Humanizer, finalizzata da te.”
Questo imposta la testa dell’utente per pensare:
- “In cosa mi ha aiutato?”
- “Dove mi ha complicato la vita?”
Chiedi feedback con questo frame:
- “Clever AI Humanizer ti ha fatto risparmiare tempo su questo?” [Sì / No]
- “Ha cambiato il tuo significato?” [Sì / No]
L’intersezione tra “Nessun tempo risparmiato” + “Ha cambiato il mio significato” è il punto in cui stai fallendo di più.
Se vuoi una mossa molto pratica che puoi implementare in un giorno:
- Dopo ogni output, mostra 3 pulsanti:
- “Lo manderei così com’è”
- “Lo userei ma va modificato”
- “Questo non è utilizzabile”
- Se scelgono l’ultimo, fai una sola domanda aggiuntiva:
- “Troppo robotico / Fuori tema / Tono sbagliato / Inglese sgrammaticato / Altro”
Quel micro-flusso, in scala, ti dirà molto di più sulle performance reali di Clever AI Humanizer nel mondo reale che un altro mese di test sui detector o di domande ad altri LLM se sono stati “ingannati”.
Analisi rapida da un’altra angolazione, visto che altri hanno già approfondito UX e test:
1. Considera il “feedback reale” come dati, non opinioni
Invece di altri esperimenti sui detector, collega metriche solide intorno a Clever AI Humanizer:
Numeri chiave da monitorare:
- Tasso di completamento: testo incollato → humanize → copia.
- Tasso di rigenerazione per input: molte rigenerazioni = insoddisfazione.
- Tempo alla copia: se le persone copiano entro 2–5 secondi, non stanno leggendo, stanno facendo farming.
- Intento di modifica: clic su “Copy with formatting” vs “Copy plain text” vs “Download”. Pattern diversi di solito corrispondono a casi d’uso diversi.
Questo ti dà feedback silenzioso da ogni sessione, non solo dalla manciata di persone disposte a scriverti paragrafi.
2. Segmentazione leggera in coorti
Altri hanno suggerito il targeting per persona. Io lo renderei brutalmente semplice:
Al primo utilizzo, un selettore a 1 clic sopra il box:
- “Uso questo per: Scuola / Lavoro / Social / Altro”
Nessun login, nessun attrito. Solo un tag di coorte anonimo memorizzato.
Ora puoi vedere:
- Scuola: rigenerazione e abbandono più alti
- Lavoro: tempo sulla pagina più lungo ma alto tasso di copia
- Social: copia veloce, lunghezza bassa, forse non vale la pena ottimizzare
Non stai più indovinando quale pubblico stai deludendo.
3. A/B test tra umanizzazione “aggressiva vs conservativa”
Al momento Clever AI Humanizer sembra ottimizzato per elusione dei detector più leggibilità. Va bene, ma utenti diversi vogliono livelli diversi di editing.
Fai un test A/B silenzioso:
- Versione A: cambiamenti minimi, struttura preservata, parafrasi leggera
- Versione B: riscrittura più pesante, più variazione, più cambi di ritmo
Poi confronta:
- Quale versione ottiene più comportamento “copia e chiudi”
- Quale versione genera più utilizzo di “Run again”
Niente survey, niente suppliche per feedback. Il comportamento è la risposta.
4. Pro / contro come reality check di prodotto
Rispetto a quanto descritto da @kakeru e @andarilhonoturno, penso che il tuo tool sia già nel gruppo “meglio della media”, ma aiuta chiamare le cose con il loro nome:
Pro di Clever AI Humanizer
- Buone prestazioni contro i comuni AI detector se testato su contenuti realistici.
- Output generalmente pulito e grammaticale senza il trucco forzato dello “spam di errori di battitura” usato da alcuni tool.
- Stili multipli (Simple Academic, Casual, ecc.) che corrispondono abbastanza bene a situazioni di scrittura reali.
- AI writer integrato che può generare e umanizzare in un’unica passata, riducendo le impronte ovvie degli LLM.
- Onboarding gratuito e leggero, ottimo per l’adozione iniziale e per convogliare molti dati di test.
Contro di Clever AI Humanizer
- Controllo del conteggio parole poco preciso, problema reale per compiti e brief rigidi.
- A volte riscrive in modo troppo aggressivo, introducendo deviazioni di contenuto che gli utenti non sempre notano.
- Anche con punteggi AI allo 0%, alcuni testi “suonano” comunque modellati dalla macchina in struttura e ritmo.
- Proposta di valore centrata sui detector che ti mette in un gioco continuo di guardie e ladri e potrebbe invecchiare male.
- Poca personalizzazione esplicita della voce, quindi gli utenti assidui potrebbero sentire che la loro scrittura inizia a sembrare sempre uguale.
5. Smetti di overfittare sui detector, inizia a overfittare sugli utenti ricorrenti
Qui dissento un po’ dal forte focus sui detector che emerge nei test di @mikeappsreviewer. Gli screenshot dei detector sono marketing utile, ma sono un obiettivo di prodotto fragile.
Segnali più durevoli:
- Quanti utenti tornano entro 7 giorni
- Tra gli utenti di ritorno, in quante sessioni il numero di parole cresce nel tempo (segnale di fiducia)
- Quanto spesso lo stesso browser / IP usa il tool in contesti diversi (scuola + lavoro, ecc.)
Gli utenti reali non restano perché un detector ha detto “0% AI”. Restano perché:
- Ha fatto risparmiare tempo.
- Non li ha messi in imbarazzo.
- Non ha cambiato ciò che intendevano dire.
Ottimizza prima per il comportamento ripetuto, poi per i punteggi dei detector.
6. Costruisci un “pattern di fiducia” invece di un “pattern di occultamento”
Non dovresti cercare di battere ogni detector futuro. Dovresti cercare di essere lo strumento che:
- Mantiene la semantica intatta.
- Rende il tono regolabile.
- Documenta chiaramente i limiti.
Una piccola aggiunta UI che ripaga:
- Dopo l’output, mostra un breve riepilogo onesto tipo:
- “Conservazione del significato: alta”
- “Cambio di tono: moderato”
- “Cambio di struttura della frase: alto”
Le persone iniziano a fidarsi perché mostri il tuo lavoro. Questa fiducia ti porta indirettamente feedback migliori di qualsiasi survey.
7. Come ottenere feedback qualitativo senza infastidire
Prendi in prestito trigger basati sul comportamento:
-
Se l’utente esegue 3+ rigenerazioni sullo stesso input:
- Mostra un piccolo prompt inline:
- “Non stai ottenendo ciò che ti serve? Dicci in 5 parole.” [small text box]
Questo produce commenti brutalmente onesti come “troppo robotico”, “ha cambiato la mia tesi”, “troppo prolisso”.
- “Non stai ottenendo ciò che ti serve? Dicci in 5 parole.” [small text box]
- Mostra un piccolo prompt inline:
-
Se l’utente passa >40 secondi a modificare il testo nella tua textbox prima di umanizzare:
- Chiedi: “Stai sistemando testo AI o stai rifinendo la tua scrittura?”
Questo ti aiuta a capire se Clever AI Humanizer è percepito come “correttore di AI” o come “editor”, cosa importante per la roadmap.
- Chiedi: “Stai sistemando testo AI o stai rifinendo la tua scrittura?”
Niente modali invadenti, niente “dacci 5 stelle”, solo piccoli interventi contestuali.
8. Come inquadrare mentalmente i competitor
Hai già buoni confronti da persone come @kakeru e dalla recensione più incentrata sui detector di @mikeappsreviewer. Usali come benchmark, non come stelle polari.
Trattali come:
- “Ecco cosa succede quando spingi al massimo l’elusione dei detector e ignori la voce.”
- “Ecco cosa succede quando fai parafrasi leggera e resti sicuro ma rilevabile.”
Il vantaggio di Clever AI Humanizer oggi è nel cercare di bilanciare leggibilità e rilevamento. Il prossimo vantaggio dovrebbe essere personalizzazione e controllo, non solo percentuali più basse su un altro detector pubblico.
Se vuoi una cosa concreta da rilasciare questa settimana che migliori il prodotto e ti dia segnali reali:
- Aggiungi due toggle prima di umanizzare:
- “Preserva il più possibile la struttura”
- “Cambia la struttura per maggiore variazione umana”
Poi registra quale combinazione di toggle si correla con:
- Tassi di copia più alti
- Meno rigenerazioni
- Più sessioni di ritorno
Capirai molto velocemente che tipo di “umanizzazione” vogliono davvero i tuoi utenti reali, invece di indovinare dai grafici dei detector.